

AI基础知识扫盲
- AIGC
- Langchain--
- LangGraph | 新手入门
- RAG(Retrieval-Augmented Generation)检索增强生成
- fastGPT
AIGC
AIGC是一种新的人工智能技术,它的全称是Artificial Intelligence Generative Content,即人工智能生成内容。
AIGC的4个主要特征
现阶段国内AIGC多以单模型应用的形式出现,主要分为文本生成、图像生成、视频生成、音频生成,其中文本生成成为其他内容生成的基础。
、
Langchain–
-知乎讲解
LangChain是一个开源框架,允许从事人工智能的开发者将例如GPT-4的大语言模型与外部计算和数据来源结合起来。该框架目前以Python或JavaScript包的形式提供。
Agents 主要包含以下的主要能力:
- 内置 Tools
- 内置组件
- 自定义工具
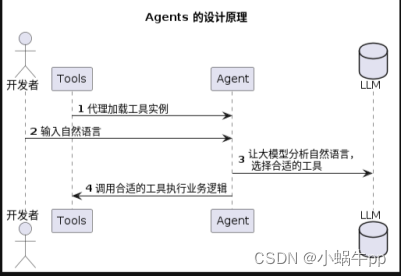

LangGraph | 新手入门
细讲
LangGraph 是在 LangChain 基础上的一个库,是 LangChain 的 LangChain Expression Language (LCEL)的扩展。能够利用有向无环图的方式,去协调多个LLM或者状态,使用起来比 LCEL 会复杂,但是逻辑会更清晰。
相当于一种高级的LCEL语言,值得一试。
LangGraph 中最基础的类型是 StatefulGraph,这种图就会在每一个Node之间传递不同的状态信息。然后每一个节点会根据自己定义的逻辑去更新这个状态信息。具体来说,可以继承 TypeDict 这个类去定义状态,下图我们就定义了有四个变量的信息。
- input:这是输入字符串,代表用户的主要请求。
- chat_history: 这是之前的对话信息,也作为输入信息传入.
- agent_outcome: 这是来自代理的响应,可以是 AgentAction,也可以是 AgentFinish。如果是 AgentFinish,AgentExecutor 就应该结束,否则就应该调用请求的工具。
- intermediate_steps: 这是代理在一段时间内采取的行动和相应观察结果的列表。每次迭代都会更新。
定义图中的节点
在LangGraph中,节点一般是一个函数或者langchain中runnable的一种类。
我们这里定义两个节点,agent和tool节点,其中
- agent节点就是决定执行什么样的行动,
- tool节点就是当agent节点选择执行某个行动时,去调用相应的工具。
此外,还需要定义节点之间的连接,也就是边。
**条件判断的边:**定义图的走向,比如Agent要采取行动时,就需要接下来调用tools,如果Agent说当前的的任务已经完成了,则结束整个流程。
普通的边:调用工具后,始终需要返回到Agent,让Agent决定下一步的行动
定义图
然后,我们就可以定义整个图了。值得注意的是,条件判断的边和普通的边添加方式是不一样的。
RAG(Retrieval-Augmented Generation)检索增强生成
RAG详写
预训练+微调
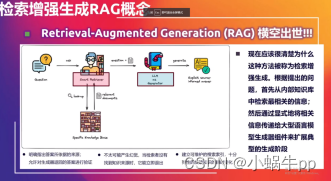
在 自然语言外理领域,大型语言模型依赖于提示词 (LLM)如GPT-3、BERT等已经取得了显著的进展,它们能够生成连贯、自然的文本,回答问题,并执行其他复杂的语言任务。然而,这些模型存在一些固有的局限性,如"模型幻觉问题”、“时效性问题”和“数据安全问题”。为了克服这些限制,检索增强生成(RAG)技术应运而生
RAG技术结合了大型语言模型的强大生成能力和检索系统的精确性。它允许模型在生成文本时,从外部知识库中检索相关信息,从而提高生成内容的准确性、相关性和时效性。这种方法不仅增强了模型的回答能力,还减少了生成错误信息的风险。
KBQA知识库问答
文本检索流程
步骤1(文本预处理):对原始文本进行清理和规范化(去除停用词、标点符号)文本统一转为小写。接着,采用词干化或词形还原等技术,将单词转换为基本形式,
步骤2(文本索引):构建倒排索引是文本检索的关键步骤。通过对文档集合进行分词,得到每个文档的词项列表,并为每个词项构建倒排列表,记录包含该词项的文档及其位置信息。这种结构使得在查询时能够快速找到包含查询词的文档,为后续的文本检索奠定了基础。
步骤3(文本检索):接下来是查询处理阶段,用户查询经过预处理后,与建立的倒排索引进行匹配。计算查询中每个词项的权重,并利用检索算法(如TFIDF或BM25)对文档进行排序,将相关性较高的文档排在前面。
fastGPT
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!
FastGPT 在线使用:https://fastgpt.in







