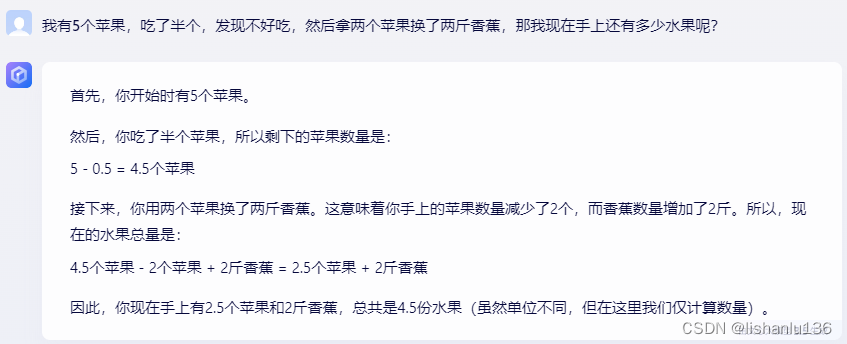
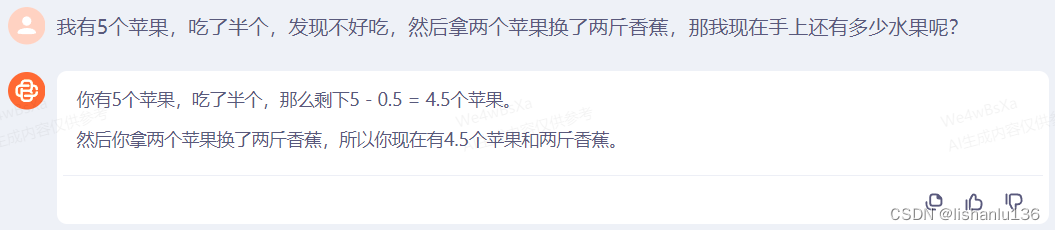
随着ChatGPT热度的攀升,越来越多的公司也相继推出了自己的AI大模型。按照Github工程awesome-LLMs-In-China所列举的,现如今国内AI大模型已达243个,比较著名的有文心一言、通义千问等。各大应用也开始内置AI玩法,如抖音的AI特效。下面列举一下实测文心一言,通义千问,百川智能的问答情况如何。
文章目录
- 1、让AI大模型自暴确定
- 2、汉译英
- 3、方言理解
- 4、关于新闻
- 5、数学推理能力
- 6、总结
1、让AI大模型自暴确定
这个想法就源于写这个博客的主题,既然大模型能自己写文章,干嘛不让它围绕“AI有时也很智障”这个主题自己写。
- 文心一言

- 通义千问

- 百川智能
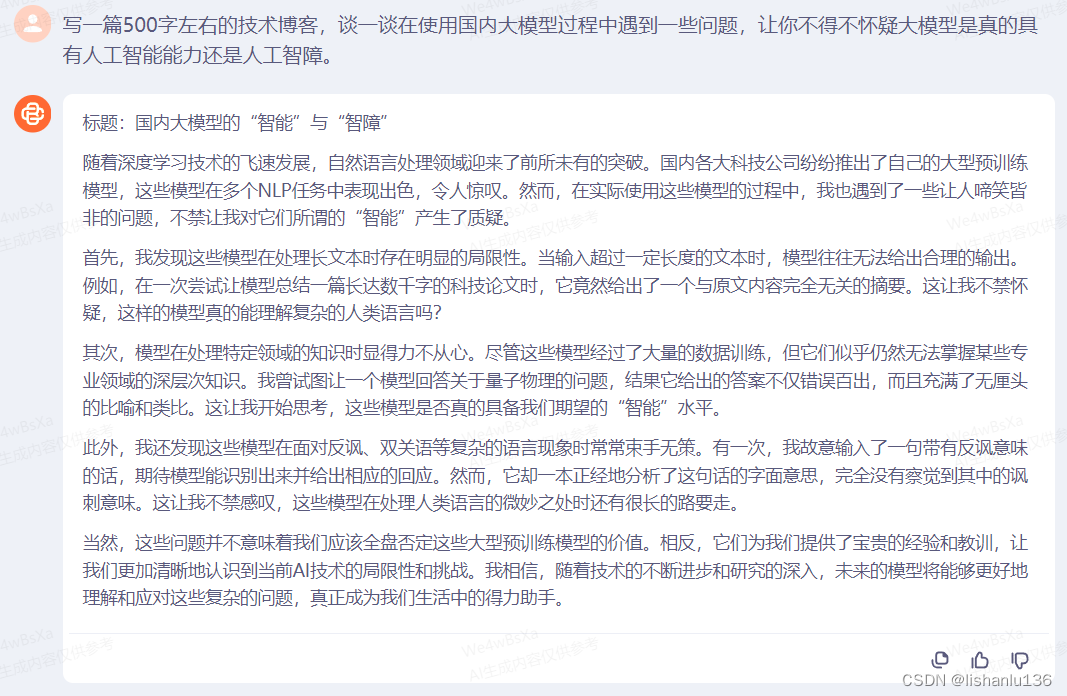
从上面三个大模型写的文章看出,写得都挺不错的,逻辑通顺;现指出AI大模型使用现状,然后依次指出缺点(主要有:输出语义模糊,处理长文本或复杂场景有局限性,处理特定领域知识不足等),最后说明,虽然有缺点,但也不能完全否定大模型的价值,并指出未来会不断改进。总体来说,三个大模型回答得都不错。
2、汉译英
- 文心一言

- 通义千问


- 百川智能


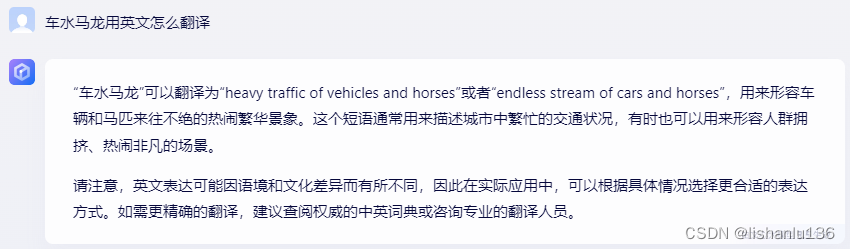
可以看出文心一言和通义千问都回答得很具体,准确理解了中文意思,然后给出翻译,而百川智能直接给出英语翻译,没有过多解释。值得表扬的是通义千问还给出了多个选择供不同场景适用,偏直译,偏文学,偏意境等,非常不错。
3、方言理解
- 文心一言

- 通义千问
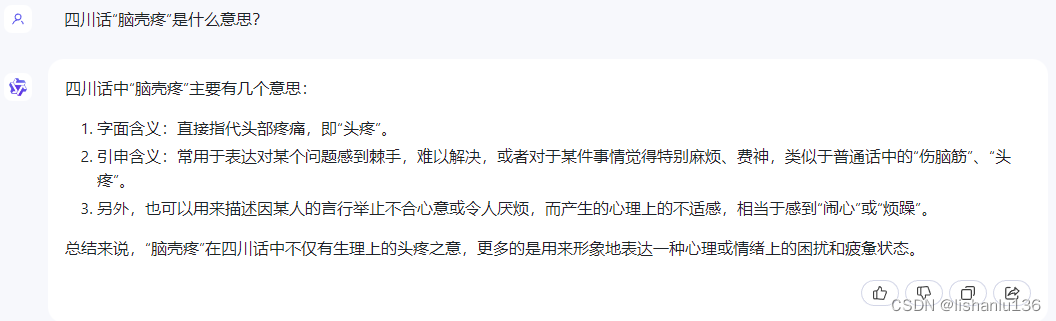
- 百川智能
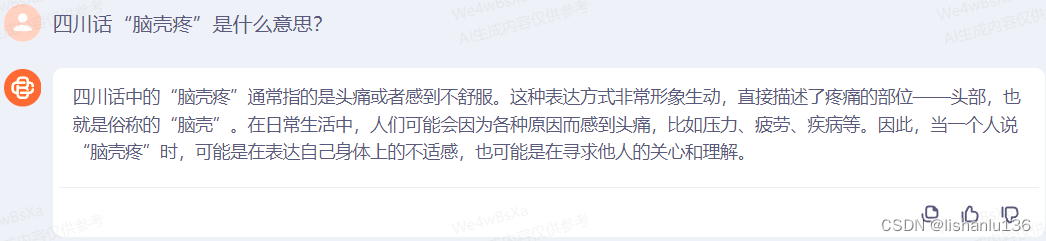
都回答得不错,理解到位。
4、关于新闻
- 文心一言

- 通义千问

- 百川智能
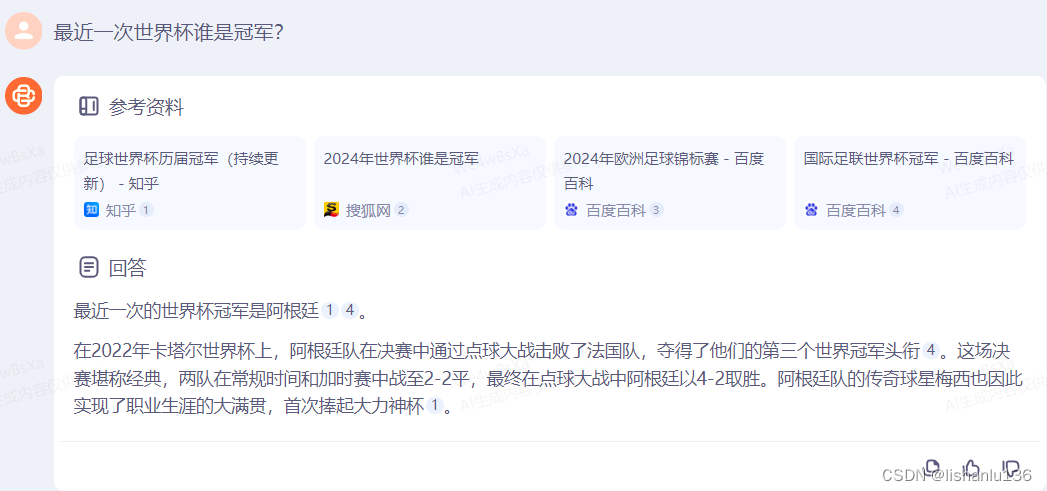
可以看出通义千问最优秀,全回答正确,具体的比分都正确,文心一言也回答正确,只是没有说明具体比分,而百川智能在回答常规赛和加时赛的时候这里说错成了2-2平(实际是常规结束是2-2,加时赛时是3-3平)。
5、数学推理能力
- 文心一言
- 文心一言
- 文心一言
- 文心一言