

文件内容:CenterFusion/src/lib/model/model.py
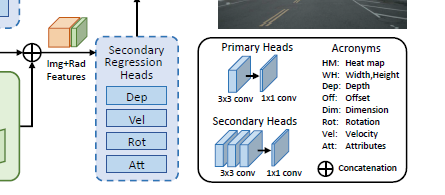
(图片来源网络,侵删)
model.py 具体内容如下:
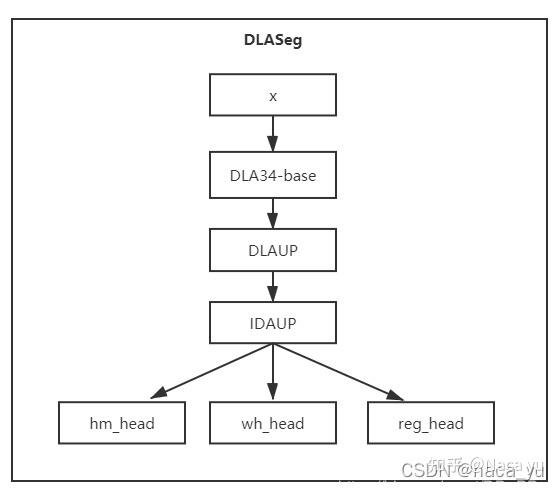
(图片来源网络,侵删)
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import torchvision.models as models
import torch
import torch.nn as nn
import os
from .networks.dla import DLASeg
from .networks.resdcn import PoseResDCN
from .networks.resnet import PoseResNet
from .networks.dlav0 import DLASegv0
from .networks.generic_network import GenericNetwork
_network_factory = {
'resdcn': PoseResDCN,
'dla': DLASeg,
'res': PoseResNet,
'dlav0': DLASegv0,
'generic': GenericNetwork
}
def create_model(arch, head, head_conv, opt=None):
num_layers = int(arch[arch.find('_') + 1:]) if '_' in arch else 0
'''
处理字符串 arch = dla_34 ,将下划线后半部分取出
最后 num_layers = 34
'''
arch = arch[:arch.find('_')] if '_' in arch else arch
'''
将 arch = dla_34 中下划线前半部分取出
最后 arch = 'dla'
'''
model_class = _network_factory[arch]
'''
根据 arch = 'dla' 获取 _network_factory 中的值
最后 model_class = DLASeg
DLASeg 类定义在 CenterFusion/src/lib/model/networks/dla.py 第 594 行
'''
model = model_class(num_layers, heads=head, head_convs=head_conv, opt=opt)
'''
配置模型
'''
return model
def load_model(model, model_path, opt, optimizer=None):
start_epoch = 0
'''
设定初始轮次 = 0
'''
checkpoint = torch.load(model_path, map_location=lambda storage, loc: storage)
print('loaded {}, epoch {}'.format(model_path, checkpoint['epoch']))
'''
torch.load() 函数:用来加载 torch.save() 保存的模型文件
'''
state_dict_ = checkpoint['state_dict']
'''
获取 checkpoint 模型文件中的 state_dict 属性
这个属性存放训练过程中需要学习的权重和偏执系数
state_dict 作为 Python 的字典对象将每一层的参数映射成 tensor 张量
需要注意的是 torch.nn.Module 模块中的 state_dict 只包含卷积层和全连接层的参数
'''
state_dict = {}
for k in state_dict_:
if k.startswith('module') and not k.startswith('module_list'):
state_dict[k[7:]] = state_dict_[k]
else:
state_dict[k] = state_dict_[k]
'''
startswith(str) 函数:检测字符串 str,检测到返回 True,否则返回 False
这里只执行了 else 语句,相当于保存导入模型的网络参数
'''
model_state_dict = model.state_dict()
'''
浅拷贝 main.py 中创建的新模型 DLA 的网络参数
'''
for k in state_dict:
'''
遍历导入的模型中的每层网络参数
'''
if k in model_state_dict:
'''
判断新模型的网络参数中是否有导入的模型的参数
是有的,因为导入的模型也是 DLA 模型
'''
if (state_dict[k].shape != model_state_dict[k].shape) or \
(opt.reset_hm and k.startswith('hm') and (state_dict[k].shape[0] in [80, 1])):
'''
第一个条件为 True
其余条件全部为 False
'''
if opt.reuse_hm:
'''
不执行
'''
print('Reusing parameter {}, required shape{}, '\
'loaded shape{}.'.format(
k, model_state_dict[k].shape, state_dict[k].shape))
# todo: bug in next line: both sides of = step:
start_lr *= 0.1
for param_group in optimizer.param_groups:
param_group['lr'] = start_lr
print('Resumed optimizer with start lr', start_lr)
else:
print('No optimizer parameters in checkpoint.')
if optimizer is not None:
'''
执行该 if 语句
'''
return model, optimizer, start_epoch
else:
return model
def save_model(path, epoch, model, optimizer=None):
if isinstance(model, torch.nn.DataParallel):
'''
isinstance(object, classinfo) 判断一个函数 object 是否是一个已知的类型 classinfo
是则返回 True,反之返回 False
'''
state_dict = model.module.state_dict()
else:
state_dict = model.state_dict()
'''
获取模型的参数矩阵
'''
data = {'epoch': epoch,
'state_dict': state_dict}
if not (optimizer is None):
data['optimizer'] = optimizer.state_dict()
'''
获取模型的优化器
'''
torch.save(data, path)
'''
保存模型
'''







