

HashMap的put方法源码
key是object类型,通过hasCode得到哈希值,但是由于得到的结果不能相同,需要通过hash桶进行构造,需要进行取模操作
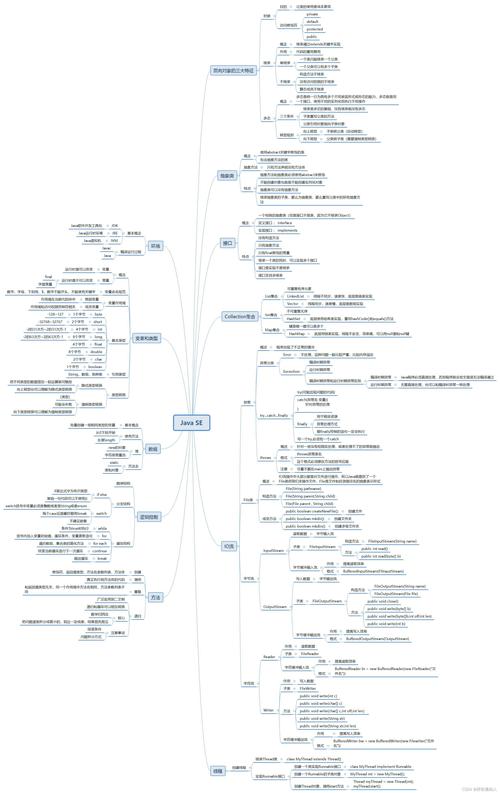
(图片来源网络,侵删)
3%5 = 3
8%5 = 3

(图片来源网络,侵删)
放在同一个结点位置,但是后来的需要链接在后面
在进行存放结点的过程中,由于大量扩容会造成遍历速度变慢,不能无限扩容,所以要对数组进行扩容
新数组扩容为原来大小的两倍,将原数组的内容,包括链表和红黑树进行重新组装后到新数组内
hasmap默认初始化容量为16,加载因子是0.75,链表长过8时则转换成红黑树,小于6则转换为链表,容量小于64时先扩容,而不会链表转化为红黑树。
当元素数量超过size的0.75时会提前进行扩容
映射机制
1.散列哈希算法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//散列哈希算法
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);//先进行hashCode然后再异或右移16位后的值 目的是为了使key的值更加分散 hash值必须大于16位(65536)才会有效果
}
2.表格大小计算法
Hash表格的大小永远是2的倍数,如果申请容量不是2的倍数,就会延伸到下一个2的倍数
static final int tableSizeFor(int cap) {
int n = -1 >>> Integer.numberOfLeadingZeros(cap - 1);//减一的目的是为了防止扩容太大 例如8 扩容为 32
return (n = MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
public static int numberOfLeadingZeros(int i) {
// HD, Count leading 0's
if (i = 1 >>= 16; }
if (i >= 1 >>= 8; }
if (i >= 1 >>= 4; }
if (i >= 1 >>= 2; }
return n - (i >>> 1);
}
/*
1000010101|
100001010|1 右移一位后和自身进行或操作
11
右移二位后和自身进行或操作
*/
//二进制全变为1,然后再加1 就可以成为2的倍数
3.映射算法
基于‘与’的映射算法
Hash表格的大小永远是2的倍数。
基减一后与hash码进行‘与’运算(&),就等同于表格大小与hash取模运算(%)
而且速度比取模要快
length - 1& hash(性能更高) == hash % length
比如表格的大小是16,减一再换算二进制后就是1111
比如表格的大小是32,减一再换算二进制后就是11111
int n=tab.length; int index=(n-1)&hash; /* 哈希Code 与 表格大小减一 进行与操作 得到在table中的索引位置 001001001111101 --------------- 1111 通过于运算达到取余的效果 */






