

Deeplearning Algorithms tutorial
谷歌的人工智能位于全球前列,在图像识别、语音识别、无人驾驶等技术上都已经落地。而百度实质意义上扛起了国内的人工智能的大旗,覆盖无人驾驶、智能助手、图像识别等许多层面。苹果业已开始全面拥抱机器学习,新产品进军家庭智能音箱并打造工作站级别Mac。另外,腾讯的深度学习平台Mariana已支持了微信语音识别的语音输入法、语音开放平台、长按语音消息转文本等产品,在微信图像识别中开始应用。全球前十大科技公司全部发力人工智能理论研究和应用的实现,虽然入门艰难,但是一旦入门,高手也就在你的不远处! AI的开发离不开算法那我们就接下来开始学习算法吧!
堆叠自动编码器(Stacked AutoEncoder)
自从Hinton 2006年的工作之后,越来越多的研究者开始关注各种自编码器模型相应的堆叠模型。实际上,自编码器(Auto-Encoder)是一个较早的概念了,比如Hinton等人在1986, 1989年的工作。
自编码器可以理解为一个试图去还原其原始输入的系统。

图中,虚线蓝色框内就是一个自编码器模型,它由编码器(Encoder)和解码器(Decoder)两部分组成,本质上都是对输入信号做某种变换。 编码器将输入信号x变换成编码信号y,而解码器将编码y转换成输出信号

,即

而自编码器的目的是,让输出尽可能复现输入x.但是,这样问题就来了,如果f和g都是恒等映射,那就是,实际上事实确实如此,但这样的变换就没有什么用了,所以我们需要对中间信号y(也叫作“编码”)做一定的约束,这样,系统往往能学出很有趣的编码变换f和编码y。
在这里需要强调一点,对于自编码器,往往并不关系输出是什么,因常我们只需要关心中间层的编码,或者是从输入到编码的映射。在我们强迫编码y和输入x不同的情况下,系统还能够去复原原始信号x,那么说明编码y已经承载了原始数据的所有信息,但以一种不同的形式!这就是特征提取。这个是通过自动学出来的,事实上,自动学习原始数据的特征表达也是神经网络和深度学习的核心目的之一。
自编码器与神经网络,其中神经网络就是在对原始信号逐层地做非线性变换:

该网络把输入层数据

转换到中间层(隐层),再转换到输出层。图中的每个节点代表数据的一个维度(偏置项图中未标出)。每两层之间的变换都是“线性变化”+“非线性激活”,用公式表示即为。图中的每个节点代表数据的一个维度(偏置项图中未标出)。每两层之间的变换都是“线性变化”+“非线性激活”,用公式表示为:

神经网络通常可以用于分类,这样可以得道从输入层到输出层的变换函数。因此,我们需要定义一个目标函数来衡量当前的输出和真实结果的差异,利用该函数去逐步调整(如梯度下降)系统的参数

,以使得整个网络尽可能去拟合训练数据。如果有正则约束的话,还同时要求模型尽量简单(以防止过拟合)。
但是自编码器怎么表示呢?
自编码器试图复现其原始输入,因此,在训练中,网络中的输出应与输入相同,即 y=x,因此,一个自编码器的输入、输出应有相同的结构,即:

这里我们可以利用训练数据训练这个网络,等训练结束后,这个网络即学习出了
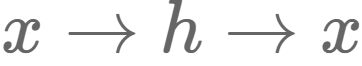
的能力。对我们来说,此时的h是至关重要的,因为它是在尽量不损失信息量的情况下,对原始数据的另一种表达。结合神经网络的惯例,我们再将自编码器的公式表示如下:(假设激活函数是sigmoid,用s表示)

其中,

表示损失函数,结合数据的不同形式,可以是二次误差(squared error loss)或交叉熵误差(cross entropy loss)。如果,一般称为tied weights。
这里我们会给隐层加入一定的约束。从数据维度来看,常见以下两种情况:
-
n>p,即隐层维度小于输入数据维度。从x→h的变换是一种降维的操作,网络试图以更小的维度去描述原始数据而尽量不损失数据信息。实际上,当每两层之间的变换均为线性,且监督训练的误差是二次型误差时,该网络等价于PCA!
-
n







