

环境配置
-
GPU 云服务厂商对比
我用了featurize和揽睿星舟。云服务厂商的选择主要看是否有jupyter,存储够大,下载快,能连git,有高配torch环境。这两家在众多小厂里脱颖而出,4090的卡一个小时也就3块钱,来来来盆友辛苦把推广费结一下~
强调下环境配置,想跑通微调,搞定环境你就成功了80%!运气好1分钟,运气差1天都在原地打转
-
实例环境:TRX4090 + py38 + torch2.0 + CUDA12
-
python环境:主要坑在transforemrs和peft,几个相关issue包括:llama tokenizer special token有问题,peft adapter.bin微调不更新,Bug with fan_in_fan_out。我一个不差都踩中了。。。
# 以下配置可能会随时间变化,出了问题就去issue里面刨吧 # 要相信你不是唯一一个大冤种! accelerate appdirs loralib bitsandbytes black black[jupyter] datasets fire transformers>=4.28.0 git+https://github.com/huggingface/peft.git sentencepiece gradio wandb cpm-kernel
模型初始化
以下代码主要整合自alpaca-lora和chatglm-finetune。其实lora微调的代码本身并不复杂,相反是如何加速大模型训练,降低显存占用的一些技巧大家可能不太熟悉。模型初始化代码如下,get_peft_model会初始化PeftModel把原模型作为base模型,并在各个self-attention层加入lora层,同时改写模型forward的计算方式。
主要说下load_in_8bit和prepare_model_for_int8_training,这里涉及到2个时间换空间的大模型显存压缩技巧。
from peft import get_peft_model, LoraConfig, prepare_model_for_int8_training, set_peft_model_state_dict from transformers import AutoTokenizer, AutoModel model = AutoModel.from_pretrained("THUDM/chatglm-6b", load_in_8bit=True, torch_dtype=torch.float16, trust_remote_code=True, device_map="auto") tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True) model = prepare_model_for_int8_training(model) lora_config = LoraConfig( task_type=TaskType.CAUSAL_LM, inference_mode=False, r=8, lora_alpha=8, lora_dropout=0.05, ) model = get_peft_model(model, lora_config) model.config.use_cache = False模型显存占用分成两个部分,一部分是静态显存基本由模型参数量级决定,另一部分是动态显存在向前传播的过程中每个样本的每个神经元都会计算激活值并存储,用于向后传播时的梯度计算,这部分和batchsize以及参数量级相关。以下8bit量化优化的是静态显存,而梯度检查优化的是动态显存。
1. 8bit Quantization
from_pretrained中的load_in_8bit参数是bitsandbytes库赋予的能力,会把加载模型转化成混合8bit的量化模型,注意这里的8bit模型量化只用于模型推理,通过量化optimizer state降低训练时显存的时8bit优化器是另一个功能不要搞混哟~
模型量化本质是对浮点参数进行压缩的同时,降低压缩带来的误差。 8-bit quantization是把原始FP32(4字节)压缩到Int8(1字节)也就是1/4的显存占用。如上加载后会发现除lora层外的多数层被转化成int类型如下

当然压缩方式肯定不是直接四舍五入,那样会带来巨大的精度压缩损失。常见的量化方案有absolute-maximum和zero-point,它们的差异只是rescale的方式不同,这里简单说下absmax,如下
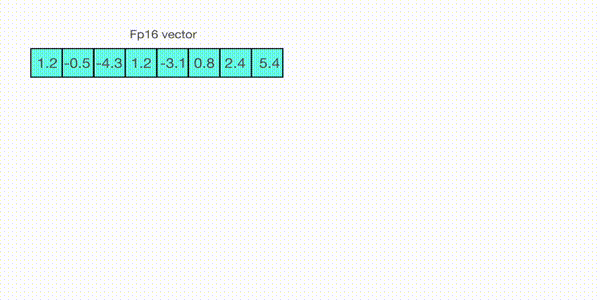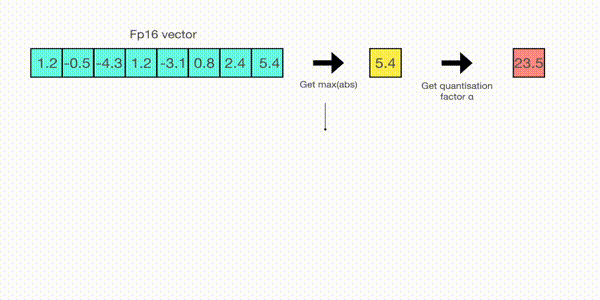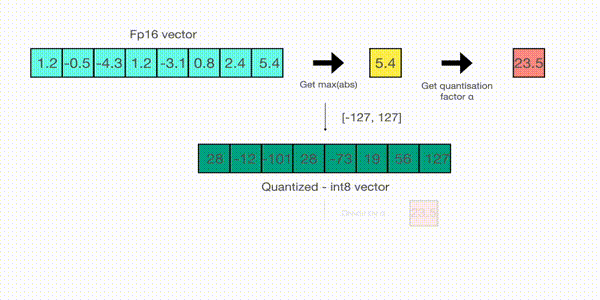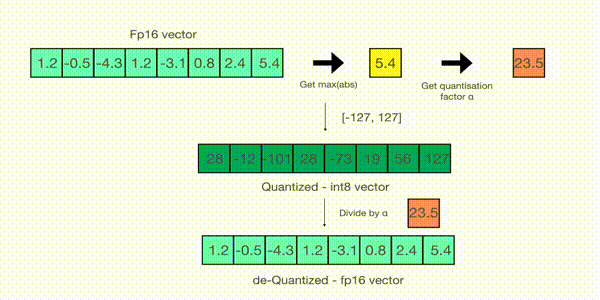
先寻找tensor矩阵的绝对值的最大值,并计算最大值到127的缩放因子,然后使用该缩放因子对整个tensor进行缩放后,再round到整数。这样就把浮点数映射到了INT8,逆向回到float的原理相同。
当然以上的缩放方案依旧存在精度损失,以及当矩阵中存在outlier时,这个精度损失会被放大,例如当tensor中绝大部分取值在1以下,有几个值在100+,则缩放后,所有1以下的tensor信息都会被round抹去。因此LLM.int8()的实现对outlier做了进一步的优化,把outlier和非outlier的矩阵分开计算,再把结果进行合并来降低outlier对精度的影响。

prepare_model_for_int8_training是对在Lora微调中使用LLM.int8()进行了适配用来提高训练的稳定性,主要包括
-
layer norm层保留FP32精度
-
输出层保留FP32精度保证解码时随机sample的差异性
2. gradient checkpoint
prepare_model_for_int8_training函数还做了一件事就是设置gradient_checkpointing=True,这是另一个时间换空间的技巧。
gradient checkpoint的实现是在向前传播的过程中使用torch.no_grad()不去存储中间激活值,降低动态显存的占用。而只是保存输入和激活函数,当进行反向传播的时候,会重新获取输入和激活函数计算激活值用于梯度计算。因此向前传播会计算两遍,所以需要更多的训练时间。
use_cache设置为False,是因为和gradient checkpoint存在冲突。因为use_cache是对解码速度的优化,在解码器解码时,存储每一步输出的hidden-state用于下一步的输入,而因为开启了gradient checkpoint,中间激活值不会存储,因此use_cahe=False。其实#21737已经加入了参数检查,这里设置只是为了不输出warning。
模型训练
训练基本和常规训练基本相同,代码如下。主要说下模型存储和加载以及混合精度训练
import datasets from transformers import Trainer, DataCollatorForSeq2Seq if resume_from_checkpoint: lora_weight = torch.load(ckpt_name) set_peft_model_state_dict(model, lora_weight) train_data = datasets.load_from_disk(dataset_path) class ModifiedTrainer(Trainer): def save_model(self, output_dir=None, _internal_call=False): # 改写trainer的save_model,在checkpoint的时候只存lora权重 from transformers.trainer import TRAINING_ARGS_NAME os.makedirs(output_dir, exist_ok=True) torch.save(self.args, os.path.join(output_dir, TRAINING_ARGS_NAME)) saved_params = { k: v.to("cpu") for k, v in self.model.named_parameters() if v.requires_grad } torch.save(saved_params, os.path.join(output_dir, "adapter_model.bin")) trainer = ModifiedTrainer( model=model, train_dataset=train_data, args=transformers.TrainingArguments( per_device_train_batch_size=8, gradient_accumulation_steps=16, num_train_epochs=10, learning_rate=3e-4, fp16=True, logging_steps=10, save_steps=200, output_dir=output_dir ), data_collator=DataCollatorForSeq2Seq( tokenizer, pad_to_multiple_of=8, return_tensors="pt", padding=True ), ) trainer.train() model.save_pretrained(train_args.output_dir)1. 模型的存储和加载
因为peftModel重写了原始model的save_pretrained函数,只把lora层的权重进行存储,因此model.save_pretrained只会存储lora权重。而trainer的save_model函数没有做相应的重写,因此我们重写下对应的function,避免checkpoint写入原始模型全部参数。
相应的如果你从ckpt加载lora权重去继续训练的话,也是对PeftModel中的Lora权重进行加载。
2. 混合精度训练
除了默认的全精度FP32,参数精度还有半精度FP16,以及BF16和TF32。最常用也是这里使用的是FP16的混合精度。
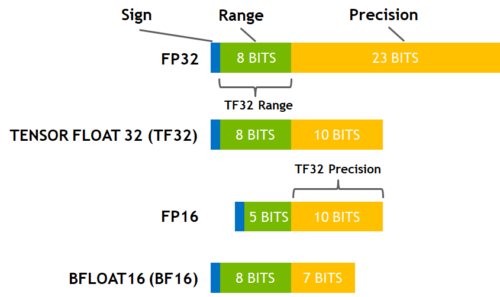
实现原理是并非所有变量都需要全精度存储,如果把部分中间变量转化成半精度,则计算效率会大幅提升,加上一些GPU对FP16计算做了优化,吞吐上比全精度会快2~5倍。
不过只使用半精度训练同样会带来量化误差,主要包括:数据溢出因为半精度比全精度的范围更小,训练到后期因为梯度越来越小可能会下溢出;舍入误差梯度变小后,因为精度有限,导致梯度更新被四舍五入,更新了个寂寞。
为了解决以上的问题引入了混合精度训练。简单来说就是向前传递时,模型权重、激活值和梯度都使用FP16进行存储,同时会拷贝一份模型权重以FP32存储,向后传播optimizer更新时会更新FP32的参数。因此混合精度训练并不会节省内存,只会提高模型训练速度。
在线教程
- 麻省理工学院人工智能视频教程 – 麻省理工人工智能课程
- 人工智能入门 – 人工智能基础学习。Peter Norvig举办的课程
- EdX 人工智能 – 此课程讲授人工智能计算机系统设计的基本概念和技术。
- 人工智能中的计划 – 计划是人工智能系统的基础部分之一。在这个课程中,你将会学习到让机器人执行一系列动作所需要的基本算法。
- 机器人人工智能 – 这个课程将会教授你实现人工智能的基本方法,包括:概率推算,计划和搜索,本地化,跟踪和控制,全部都是围绕有关机器人设计。
- 机器学习 – 有指导和无指导情况下的基本机器学习算法
- 机器学习中的神经网络 – 智能神经网络上的算法和实践经验
- 斯坦福统计学习
有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓


人工智能书籍
- OpenCV(中文版).(布拉德斯基等)
- OpenCV+3计算机视觉++Python语言实现+第二版
- OpenCV3编程入门 毛星云编著
- 数字图像处理_第三版
- 人工智能:一种现代的方法
- 深度学习面试宝典
- 深度学习之PyTorch物体检测实战
- 吴恩达DeepLearning.ai中文版笔记
- 计算机视觉中的多视图几何
- PyTorch-官方推荐教程-英文版
- 《神经网络与深度学习》(邱锡鹏-20191121)
- …

第一阶段:零基础入门(3-6个月)
新手应首先通过少而精的学习,看到全景图,建立大局观。 通过完成小实验,建立信心,才能避免“从入门到放弃”的尴尬。因此,第一阶段只推荐4本最必要的书(而且这些书到了第二、三阶段也能继续用),入门以后,在后续学习中再“哪里不会补哪里”即可。

第二阶段:基础进阶(3-6个月)
熟读《机器学习算法的数学解析与Python实现》并动手实践后,你已经对机器学习有了基本的了解,不再是小白了。这时可以开始触类旁通,学习热门技术,加强实践水平。在深入学习的同时,也可以探索自己感兴趣的方向,为求职面试打好基础。

第三阶段:工作应用

这一阶段你已经不再需要引导,只需要一些推荐书目。如果你从入门时就确认了未来的工作方向,可以在第二阶段就提前阅读相关入门书籍(对应“商业落地五大方向”中的前两本),然后再“哪里不会补哪里”。
有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓


-







