

Stable Diffusion 超详细讲解
这篇文章是 《Stable Diffusion原理详解》的后续,在《Stable Diffusion原理详解》中我更多的是以全局视角讲解了 Stable Diffusion 的原理和工作流程,并未深入步骤细节。本文将在《Stable Diffusion原理详解》和《Diffusion Model 深入剖析》这两篇文章的基础上,进一步细致地讲解 Stable Diffusion 的算法原理。

文章目录
- Diffusion Model
- Diffusion Model 概览
- 正向扩散过程
- 逆向扩散过程
- 训练
- 采样
- 扩散速度问题
- Stable Diffusion
- 潜在空间
- Latent Diffusion
- 调节机制
- 训练
- 采样
- 架构对比
- 纯扩散模型
- Stable Diffusion (潜在扩散模型)
- 总结
Diffusion Model
Stable Diffusion 脱胎于 Diffusion 模型。因此在搞懂 Stable Diffusion 之前,先搞懂 Diffusion Model 模型非常有必要。这一部分我会带大家大致过一遍 Diffusion Model。如果你想了解 Diffusion Model 的全部细节,可以阅读我之前的文章:《Diffusion Model 深入剖析》。
Diffusion Model 概览
图1. 扩散模型原理概要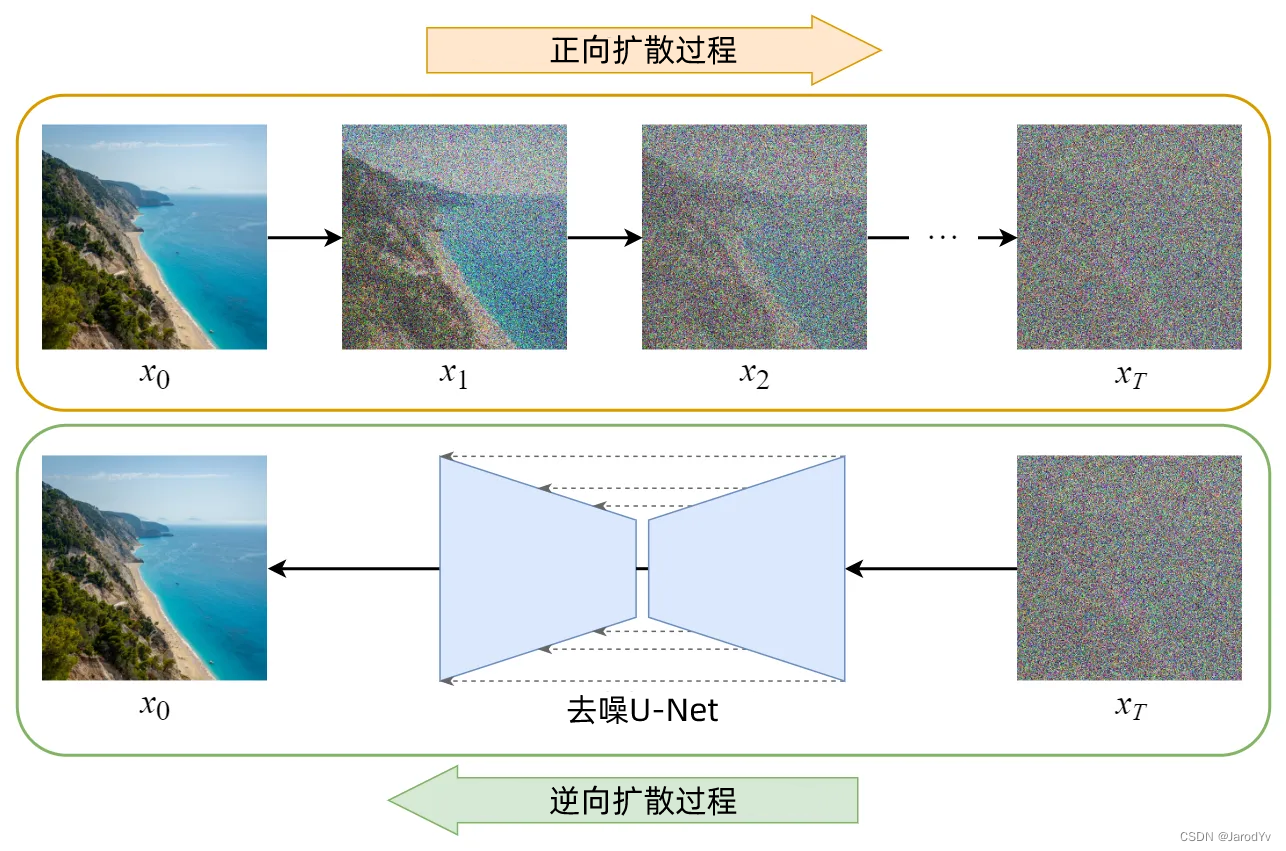
Diffusion Model的训练可以分为两部分:
- 正向扩散过程 → 为图像添加噪声。
- 反向扩散过程 → 去除图像中的噪声。
正向扩散过程
正向扩散过程将高斯噪声逐步添加到输入图像中。我们使用以下闭合公式(推导过程详见《Diffusion Model 深入剖析》)更快地完成噪声添加,从而直接获得特定时间步长 t t t 的噪声图像:
x t = α t ˉ x 0 + 1 − α ˉ t ε x_t=\sqrt{\bar{\alpha_t}}x_0+\sqrt{1-\bar{\alpha}_t}\varepsilon xt=αtˉ x0+1−αˉt ε
逆向扩散过程
由于逆向扩散过程不可直接计算(计算代价太高),我们通过训练神经网络 p θ ( x t − 1 ∣ x t ) p_\theta(x_{t-1}|x_t) pθ(xt−1∣xt) 来近似。
训练目标(损失函数)如下:
L simple = E t , x 0 , ε [ ∣ ∣ ε t − ε θ ( x t , t ) ∣ ∣ 2 ] x t = α t ˉ x 0 + 1 − α ˉ t ε L_{\text{simple}} = \mathbb{E}_{t,x_0,\varepsilon}\Big[||\varepsilon_t-\varepsilon_\theta(x_t,t)||^2\Big]\\ x_t=\sqrt{\bar{\alpha_t}}x_0+\sqrt{1-\bar{\alpha}_t}\varepsilon Lsimple=Et,x0,ε[∣∣εt−εθ(xt,t)∣∣2]xt=αtˉ x0+1−αˉt ε
训练
每一轮训练过程如下:
- 为每个训练样本(图像)选择一个随机时间步长 t t t。
- 将高斯噪声(对应于 t t t)应用于每个图像。
- 将时间步长转换为嵌入(向量)。
图2. 训练数据集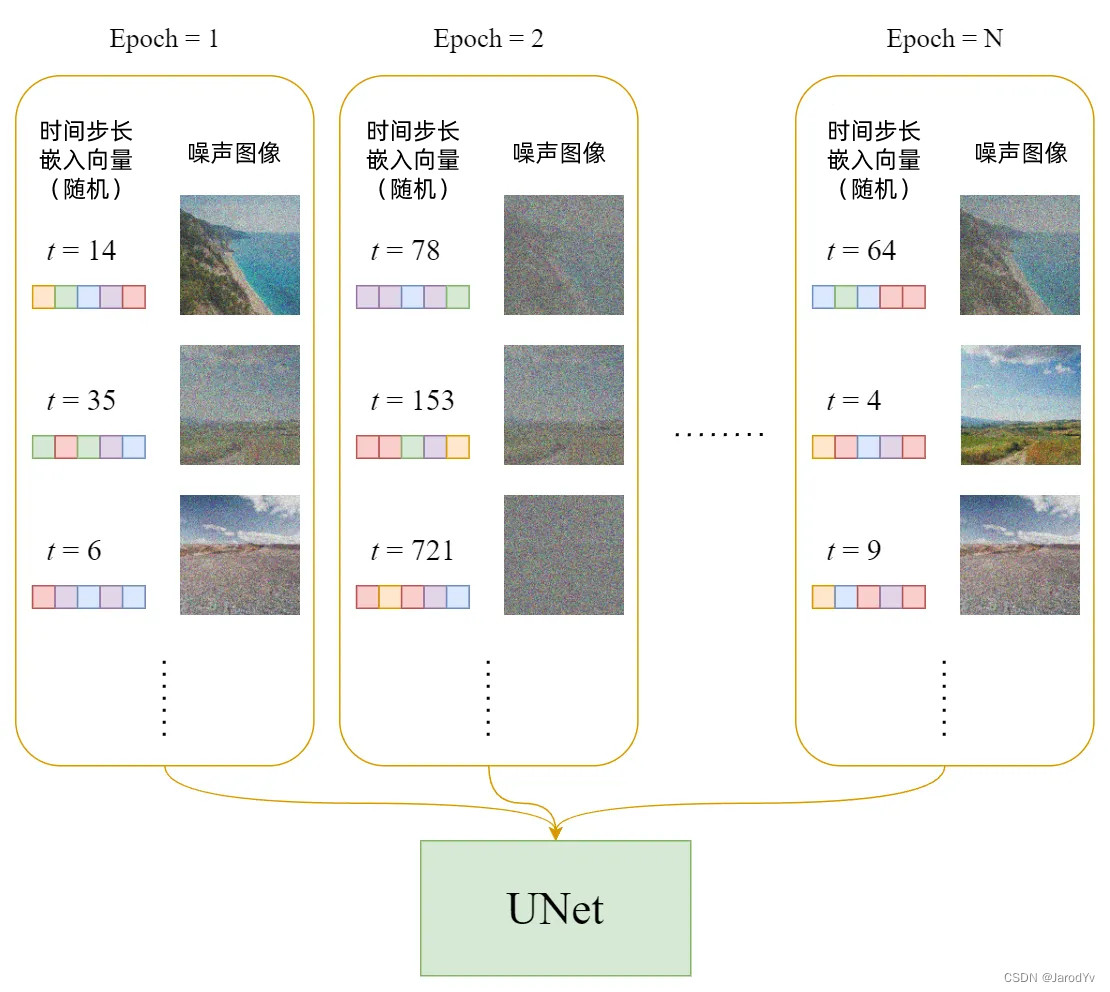
下面详细解释一下训练步骤是如何工作的:
图3. 训练步骤图解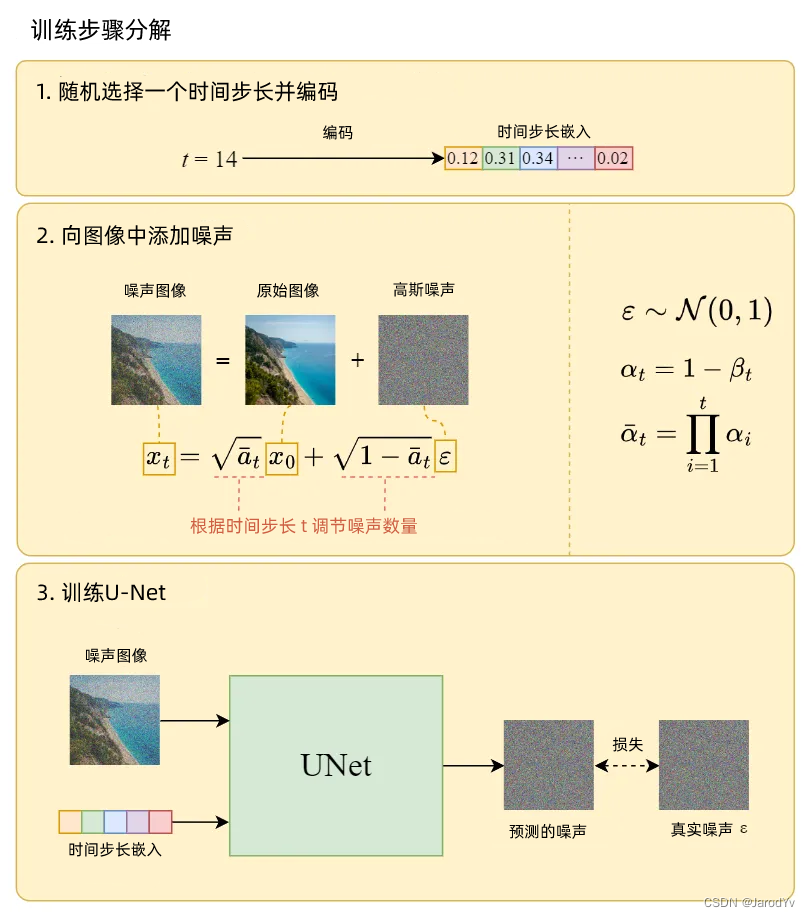
采样
采样意味着从高斯噪声图中绘制出图像。下图展示了我们如何使用经过训练的 U-Net 生成图像:
图4. 采样过程图解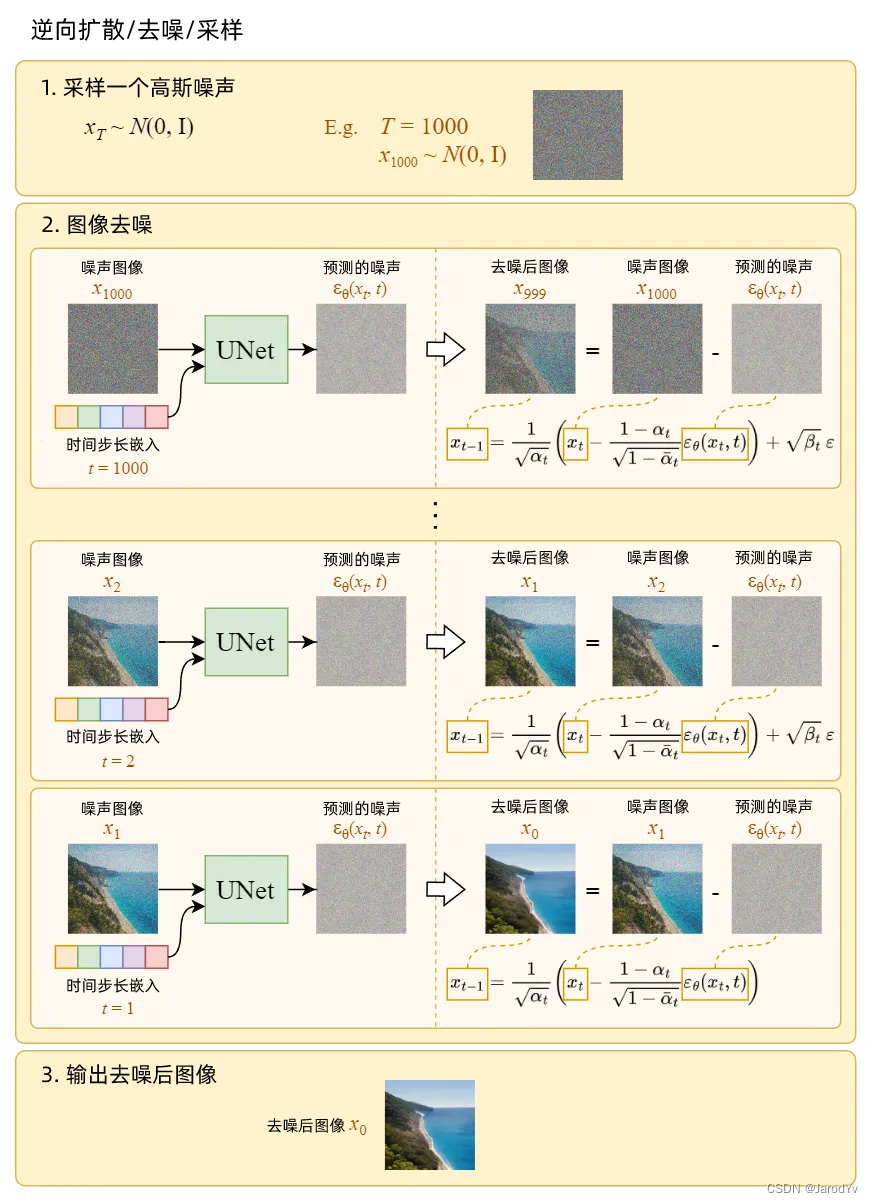
扩散速度问题
如你所见,扩散(采样)过程迭代地将全尺寸图像提供给 U-Net 来获得最终结果。当总扩散步数 T T T 和图像很大时,这种纯扩散模型会非常慢。
为了解决这个问题,Stable Diffusion 应运而生。
Stable Diffusion
Stable Diffusion 一开始的名称是“潜在扩散模型”(Latent Diffusion Model)。顾名思义,Stable Diffusion 发生在潜在空间中。这就是它比纯扩散模型更快的原因。
潜在空间
图5. 潜在空间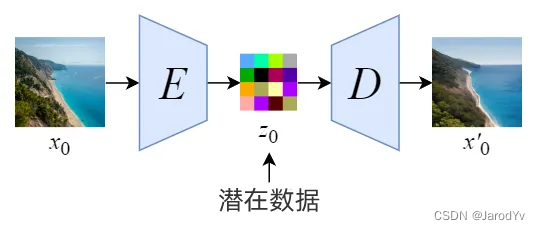
我们首先训练一个自动编码器来学习如何将图像数据压缩成低维表示。
- 通过使用经过训练的编码器 E E E,我们可以将全尺寸图像编码为低维潜在数据(压缩数据)。
- 通过使用经过训练的解码器
D
D
D,我们可以将潜在数据解码回图像。
Latent Diffusion
将图像编码为潜在数据后,将在潜在空间中进行正向和反向扩散过程。
图6. Stable Diffusion 模型概述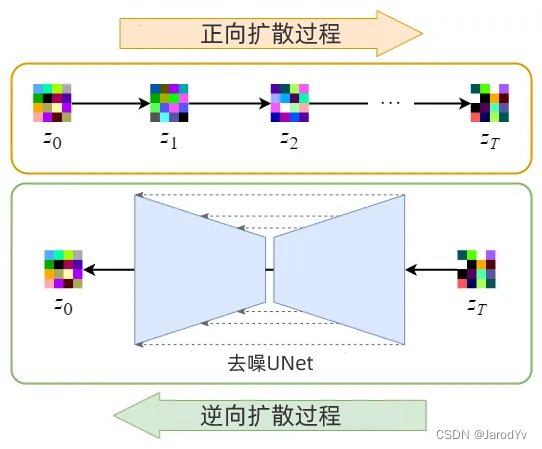
- 正向扩散过程 → 向潜在数据添加噪声。
- 逆向扩散过程 → 从潜在数据中去除噪声。
调节机制
图7. 调节机制概述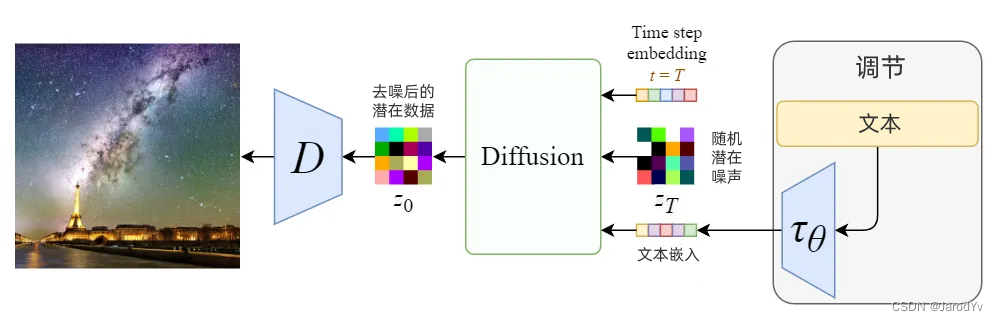
Stable Diffusion 真正强大之处在于它可以根据文本提示生成图像。这是通过接受调节输入修改内部扩散模型来实现的。
图8. 调节机制细节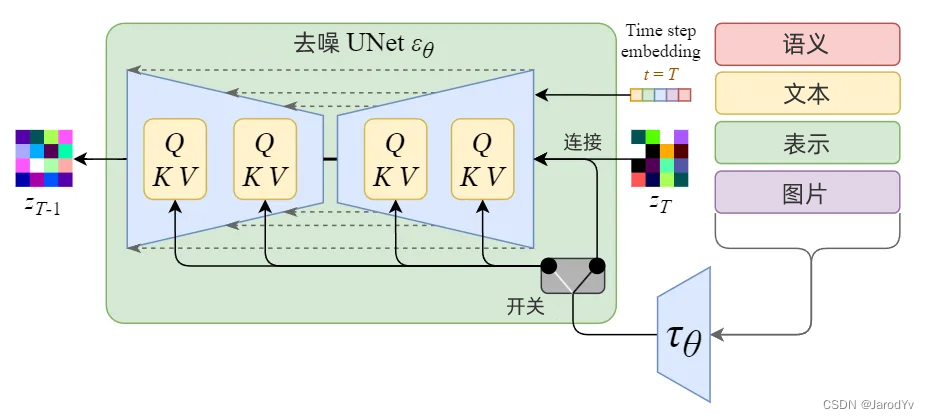
通过使用交叉注意机制增强其去噪 U-Net,将内部扩散模型转变为条件图像生成器。
上图中的开关用于在不同类型的调节输入之间进行控制:
- 对于文本输入,首先使用语言模型 τ θ \tau_\theta τθ(例如 BERT、CLIP)将文本转换为嵌入(向量),然后通过(多头)注意力 A t t e n t i o n ( Q , K , V ) Attention(Q, K, V) Attention(Q,K,V) 映射到 U-Net 层。
- 对于其他空间对齐的输入(例如语义映射、图像、修复),可以使用连接来完成调节。
训练
Stable Diffusion 的训练目标(损失函数)与纯扩散模型中的目标非常相似。 唯一的变化是:
- 输入潜在数据 z t z_t zt 而不是图像 x t x_t xt。
- 向 U-Net 添加了条件输入
τ
θ
(
y
)
\tau_\theta(y)
τθ(y)。
所以 Stable Diffusion 的损失函数是这样的:
L L D T = E t , z 0 , ε , y [ ∥ ε − ε θ ( z t , t , τ θ ( y ) ) ∥ 2 ] L_{LDT} = \mathbb{E}_{t,z_0,\varepsilon,y}\Big[\Vert \varepsilon-\varepsilon_\theta\big(z_t,t,\tau_\theta(y)\big)\Vert^2\Big] LLDT=Et,z0,ε,y[∥ε−εθ(zt,t,τθ(y))∥2]
其中 z t = α ˉ t z 0 + 1 − α ˉ t ε z_t = \sqrt{\bar\alpha_t}z_0 + \sqrt{1-\bar\alpha_t}\varepsilon zt=αˉt z0+1−αˉt ε, z 0 = E ( x 0 ) z_0 = E(x_0) z0=E(x0) ; τ θ ( y ) \tau_\theta(y) τθ(y) 是输入调节。
采样
图9. Stable Diffusion 采样过程(去噪)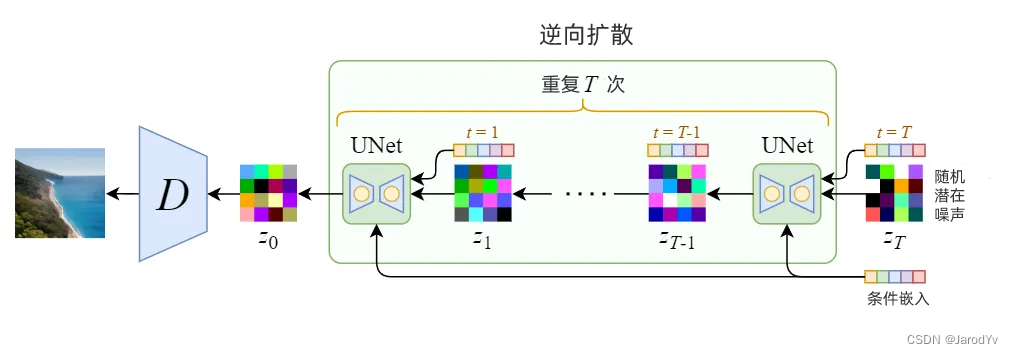
由于潜在数据的大小比原始图像小得多,因此去噪过程会快得多。
架构对比
最后,让我们比较一下纯扩散模型和 Stable Diffusion(潜在扩散模型)的整体架构。
纯扩散模型
图10. 纯扩散模型架构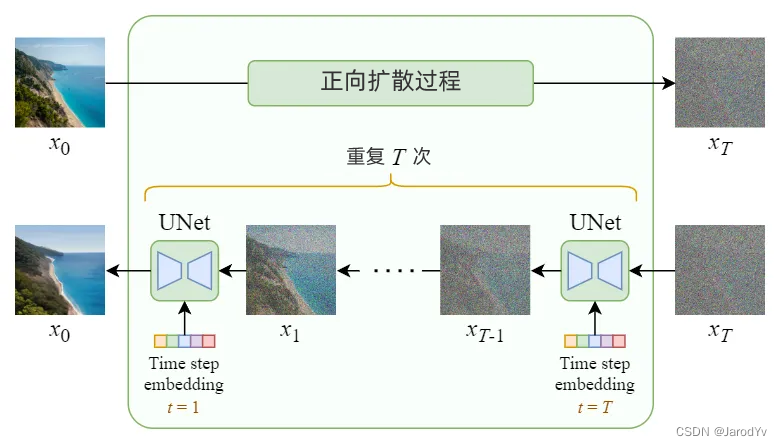
Stable Diffusion (潜在扩散模型)
图11. Stable Diffusion 架构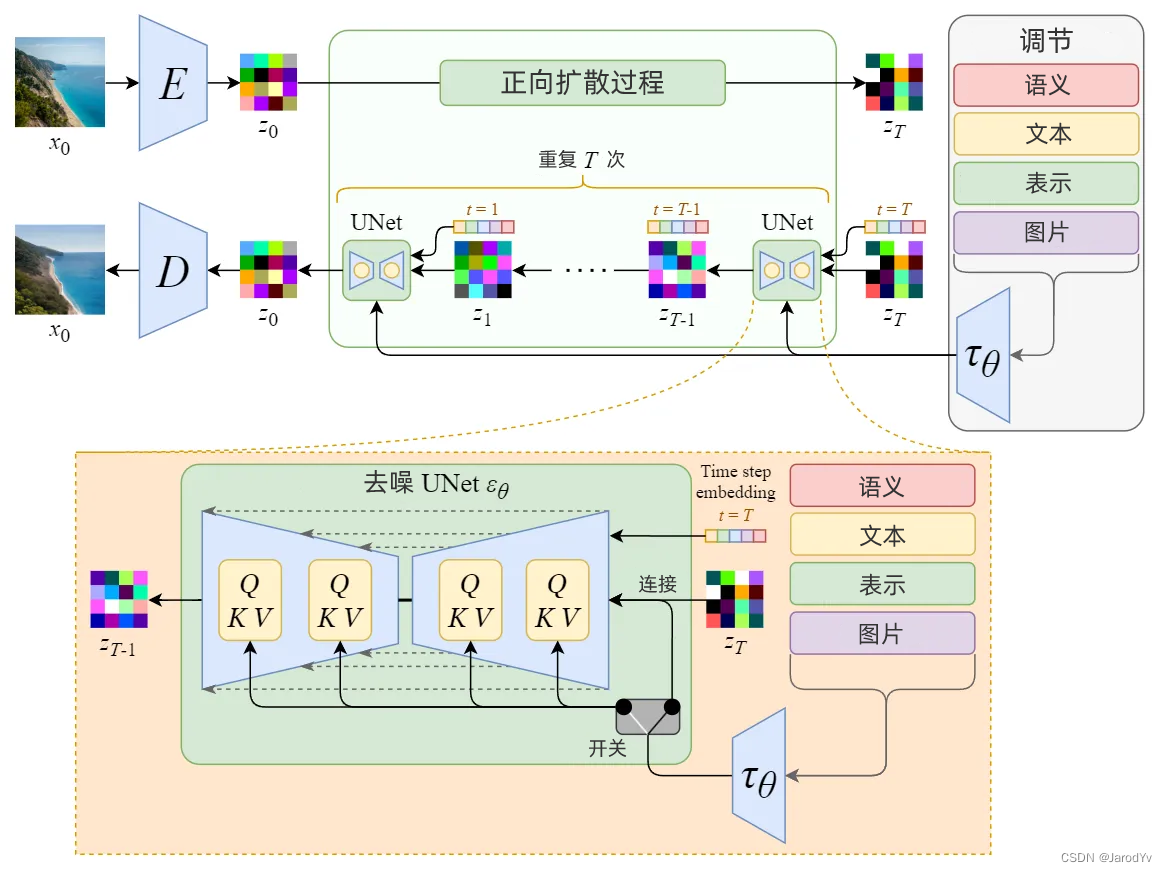
总结
- Stable Diffusion(潜在扩散模型)在潜在空间中进行扩散过程,因此它比纯扩散模型快得多。
- 扩散模型核心被修改为接受条件输入,如文本、图像、语义图等。






