


目录
一.关于快速排序的总体算法思想
1.冒泡排序(交换排序) (以排升序为例)
2.快速排序的总体思想简介(以排升序为例)
二.快速排序单趟排序的算法接口设计(以排升序为例)
单趟排序实现的方法一:hoare版本(左右指针法)
代码实现:
单趟排序实现的方法二:挖坑法
代码实现:
单趟排序实现的方法三:快慢指针法
代码实现:
三. 快速排序的实现(待进一步优化的版本)(排升序)
递归函数实现:
快排时空复杂度分析(所处理的数组为逆序数极大的乱序数组的情形)
快排效率实测:
四.未经进一步优化的快速排序的缺陷
一.关于快速排序的总体算法思想
🤓我们先总览一下快速排序的思想,再去了解其中的细节:
- 快速排序是基于对交换排序(冒泡排序)的优化而产生的高效排序算法
- 其基本思想是利用分治递归算法将交换排序的时间复杂度(O(N^2))降阶为O(NlogN)
1.冒泡排序(交换排序) (以排升序为例)
🤓冒泡排序的算法思想:
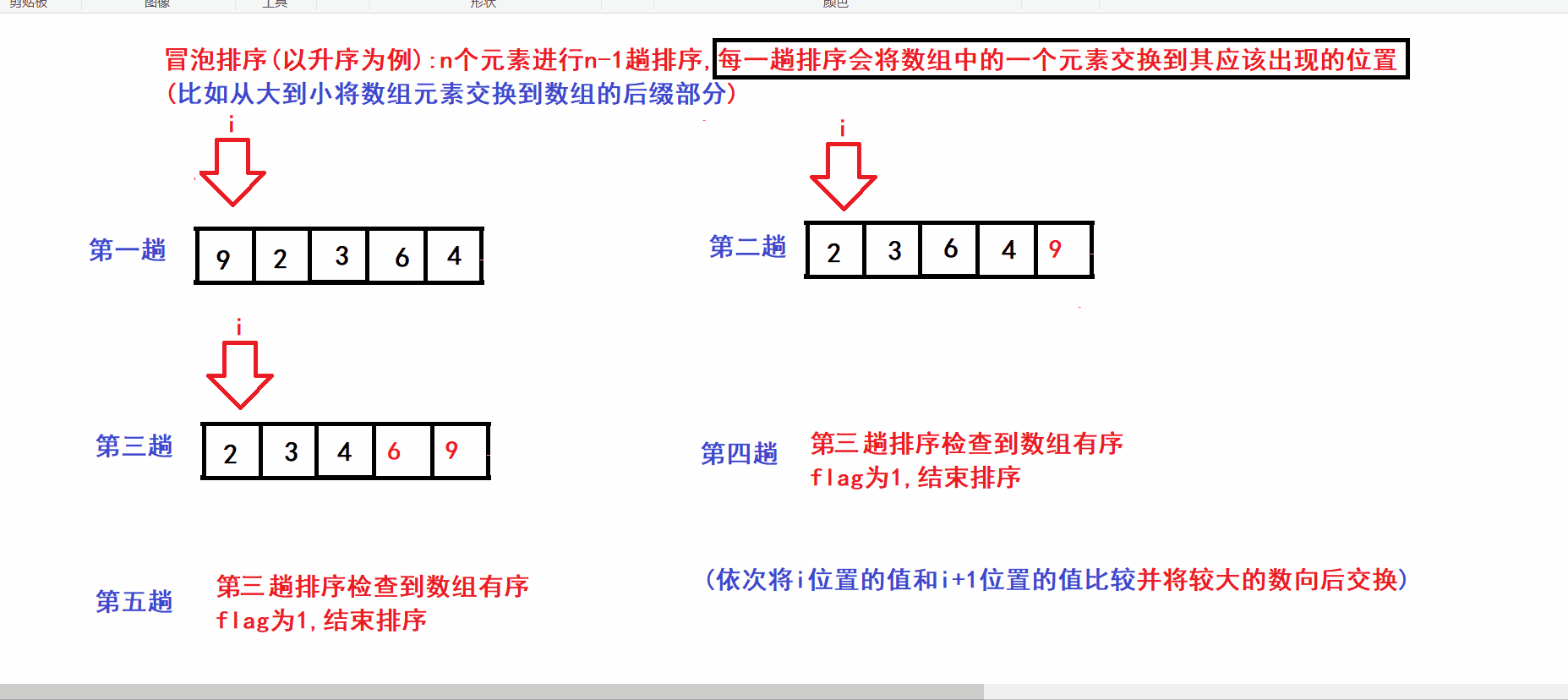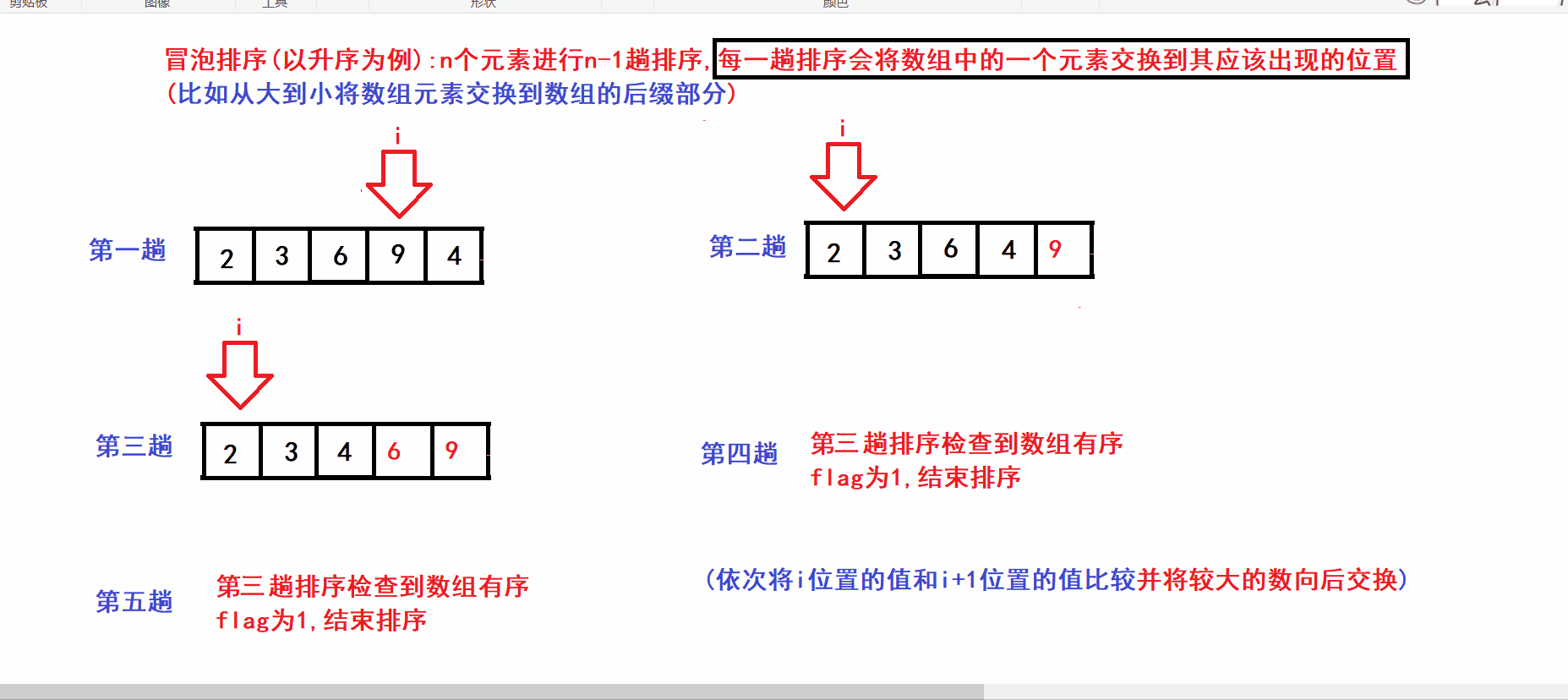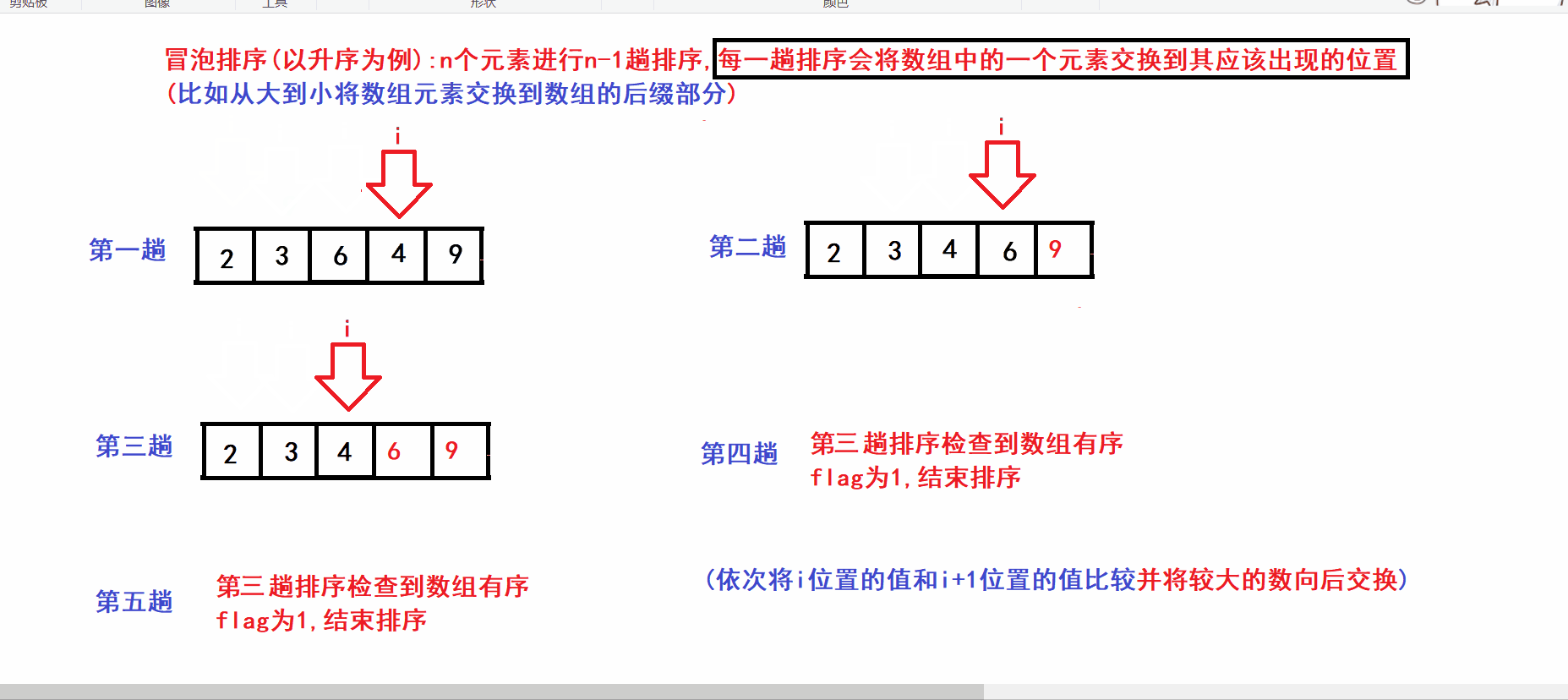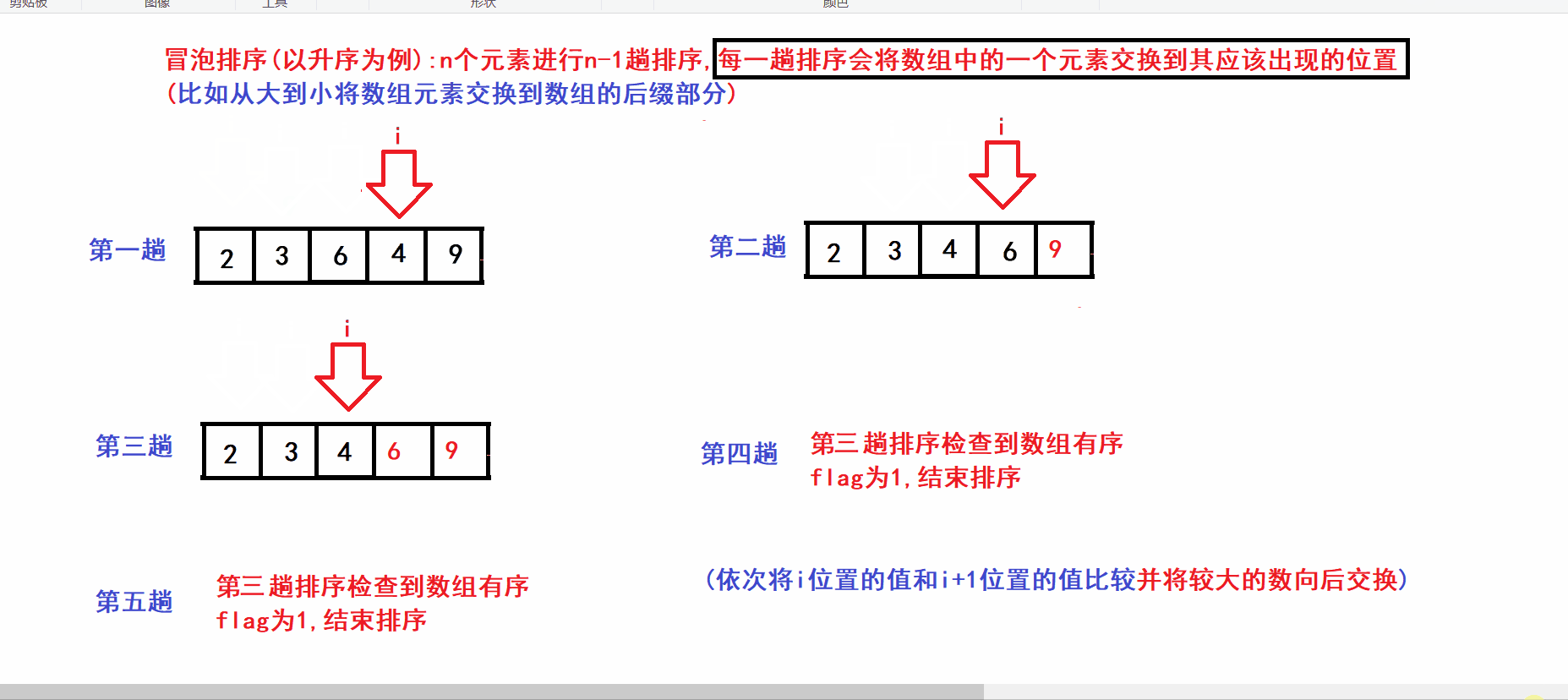
- N个元素的数组则进行N-1趟排序
- 每一趟排序将数组中的一个元素交换到其最终应该出现的位置(比如将第n大的数交换到数组下标为N-n的位置)
- 算法图解:
🤓代码实现:
void swap(int* e1, int* e2) { assert(e1 && e2); int tem = *e1; *e1 = *e2; *e2 = tem; } void BubbleSort(int* arr, int size) { assert(arr); int turns = 0; //记录排序的趟数 int flag = 0; //flag用于标记数组是否已经有序 while (turns arr[i + 1]) { swap(&arr[i], &arr[i + 1]); //将较大的元素向后交换 flag = 0; } } if (flag) //flag为1说明数组已经有序 { break; //数组已经有序则可以结束循环 } ++turns; //继续下一趟排序 } }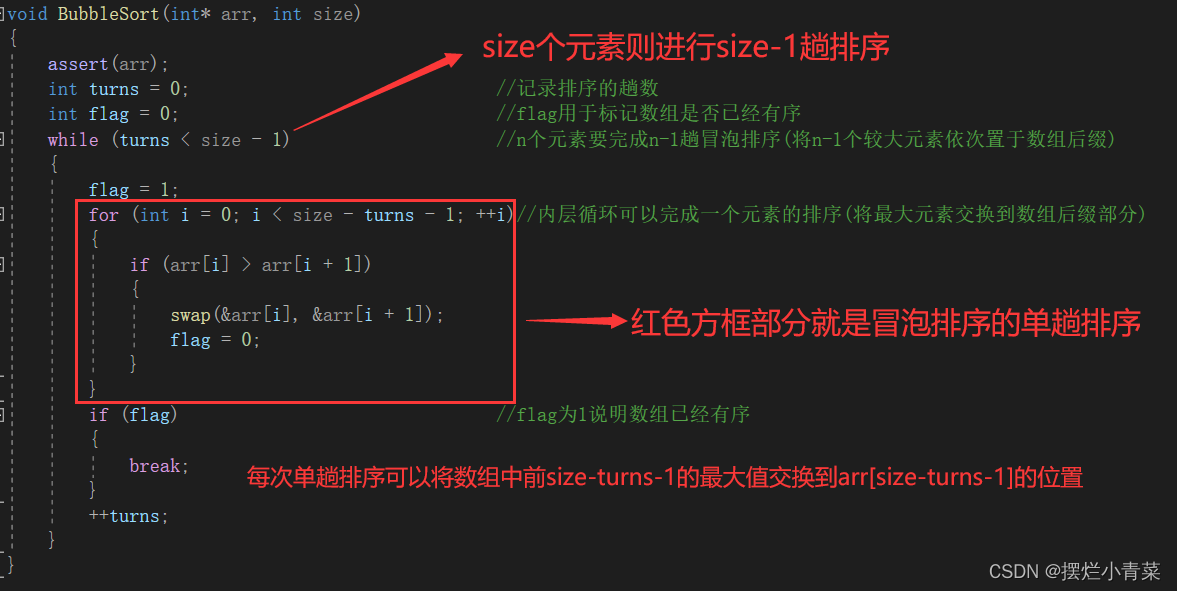
- 冒泡排序算法的复杂度计算公式(最坏情况下)是一个等差数列求和式,因此其时间复杂度为O(N^2)(这里只考虑最坏的情形)
- 冒泡排序的单趟排序:
for (int i = 0; i arr[i + 1]) { swap(&arr[i], &arr[i + 1]); //将较大的元素向后交换 flag = 0; //标记出数组无序 } }冒泡排序的单趟排序会把前(size-turns)个元素中的最大值交换到(size-turns-1)的位置(增加数组的有序后缀长度)
-
冒泡排序单趟排序关注的是数组无序前(后)缀中的最值,这一点限制了算法优化的思路
-
1962年Hoare大神运用双指针算法重新设计了交换排序的单趟排序,并运用分治递归实现代替了嵌套循环实现,完成了交换排序的终极优化🧐🧐
2.快速排序的总体思想简介(以排升序为例)
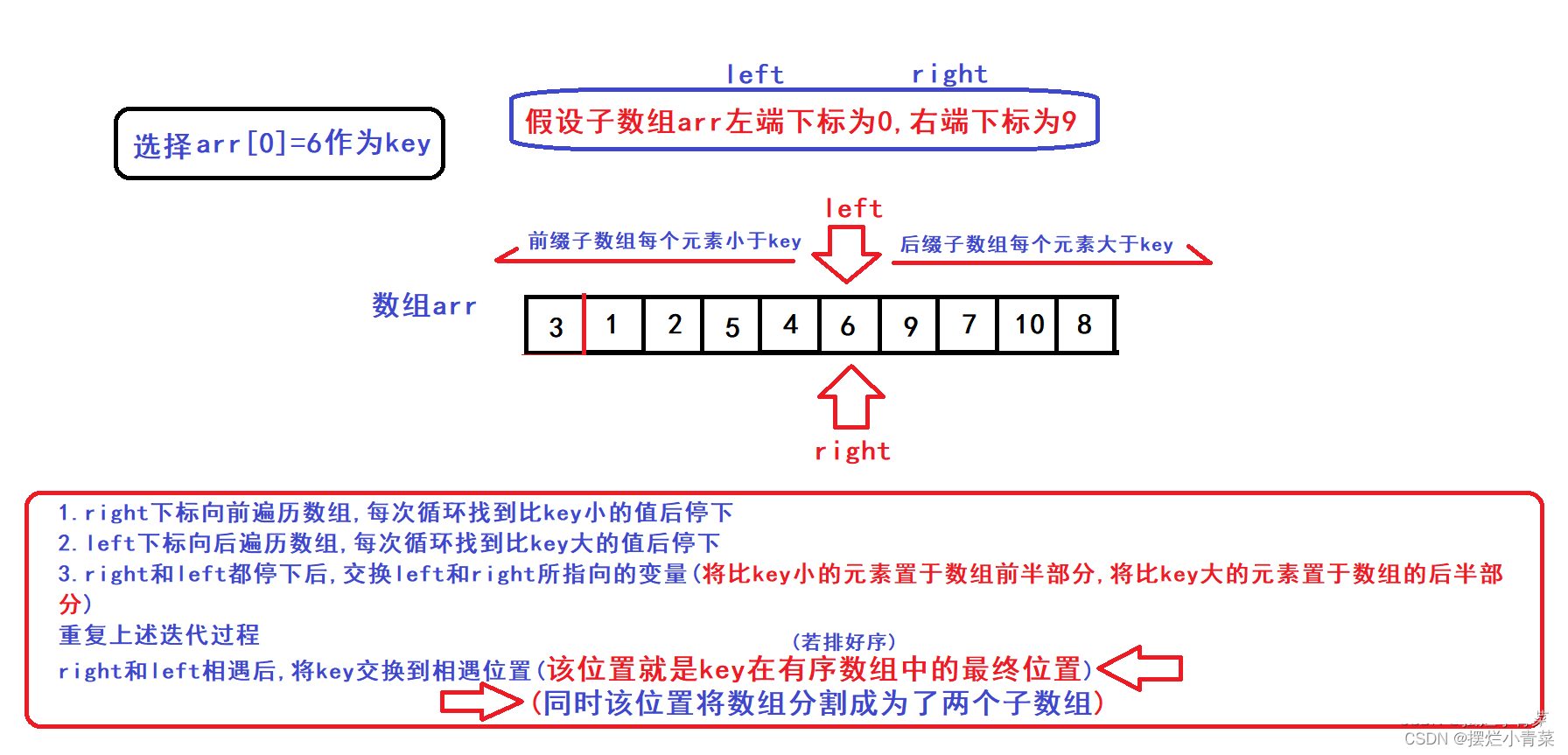
- 🤓利用双指针算法来设计单趟排序过程以达到以下目的:在数组中选取一个key元素,将比key小的元素交换到key元素的左边,将比key大的元素交换到key元素的右边

- 🤓由于key元素左边的子数组每个元素的值都比key元素小,key元素右边的子数组每个元素的值都比key元素大,因此经过单趟排序后,key元素就被交换到了其在有序序列中最终应该出现的位置),同时,左右子数组我们可以分开完成排序(这一点非常关键).图示:
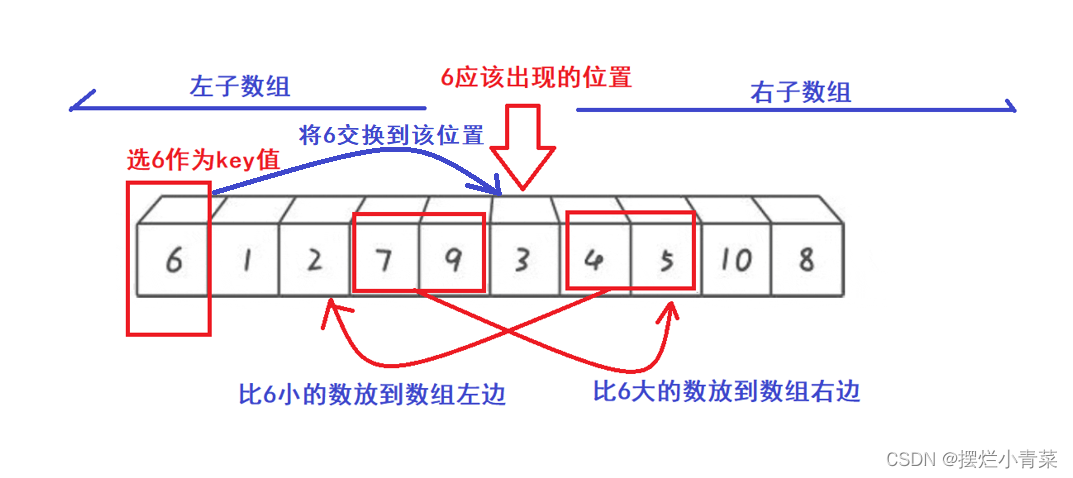 😉(算法的具体实现后面再深究)😉
😉(算法的具体实现后面再深究)😉 - 🤓根据单趟排序过程确定的key元素的最终位置(比如上图中的数组下标为5的位置)为分割点,将数组分为左右子数组(子数组中不包含key元素):
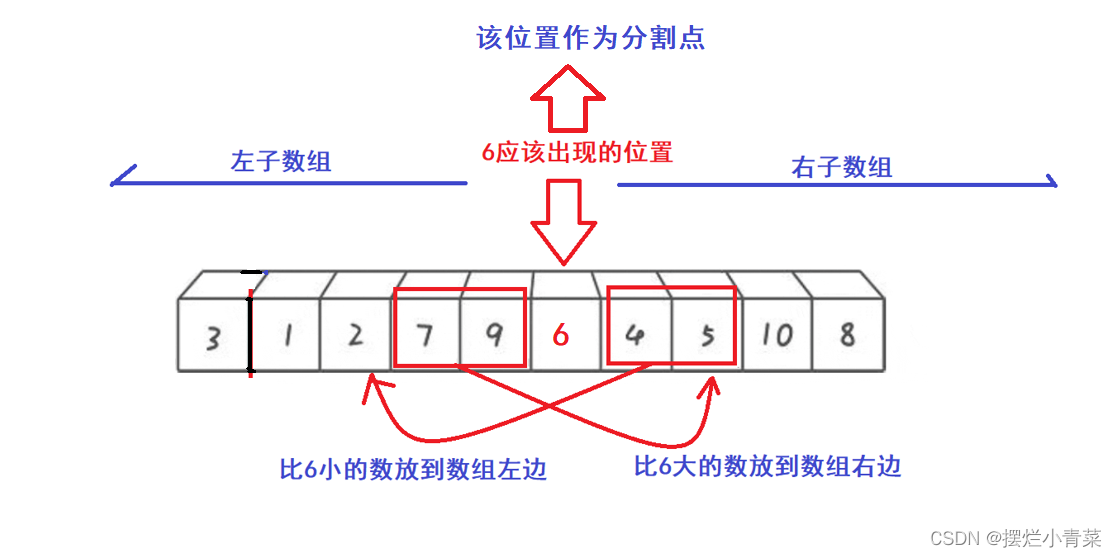
- 🤓在子数组中我们分别再进行单趟排序,并以key元素最终位置作为分割点继续分割子数组,于是便形成了递归,递归的过程中数组被逐步拆分的图示:(每一个子数组中都要进行一次单趟排序以确定数组的划分点)(当子数组元素个数为1时划分结束)(这里我们假设每次分割数组时分割点都在数组的中间位置)
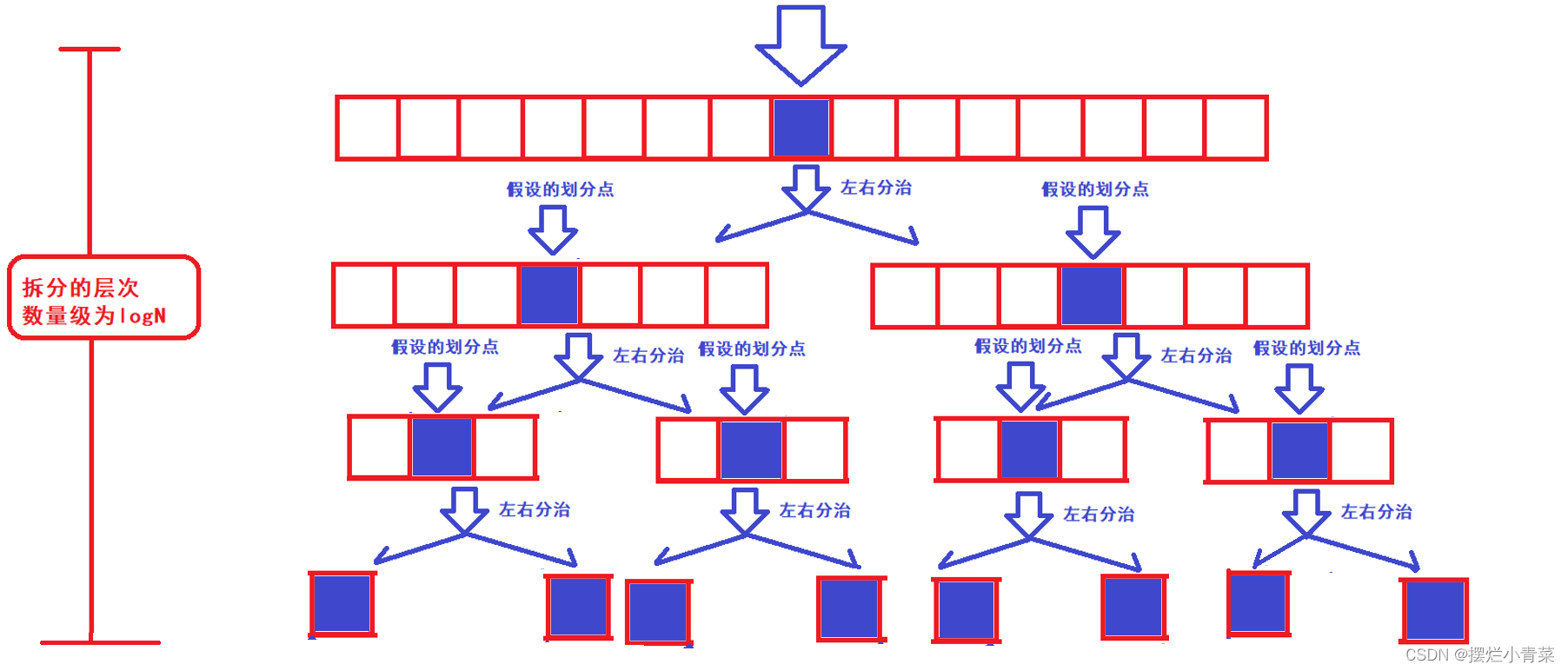
- 🤓假设数组中有N个元素,每一个子数组进行单趟排序的过程中,我们都要遍历一次子数组,根据上图可知,每一个递归层次我们都需要遍历N个元素,而递归层次的数量级为logN,因此相比于冒泡排序,快排的时间复杂度便降阶为O(NlogN).
- 🤓可见分治思想有时可以将复杂度为N*N的遍历算法降阶为复杂度为N*logN的遍历算法,其原因在于,数组被划分后,左右子数组互不相关,在左右子数组中分别进行单趟操作,需要遍历的元素个数就变少了(无须每次单趟操作都遍历原数组的所有元素)
- 🤓分治优化的思想在许多其他算法设计中也是十分常见的。
二.快速排序单趟排序的算法接口设计(以排升序为例)
快速排序的单趟排序要达到的目的:
1.将数组中某个元素(key元素)交换到其在有序序列中最终应该出现的位置,即:
- 单趟排序结束后要保证key元素之前的元素都比key元素小
- 单趟排序结束后要保证key元素之后的元素都比key元素大
2.单趟排序接口返回key元素最后的位置下标(作为数组分割点)
单趟排序实现的方法一:hoare版本(左右指针法)
- hoare大神是快速排序发明者🤓🤓🤓🤓
- 算法接口首部:
int PartionV1(int* arr, int left, int right)//完成1个元素的排序,同时返回数组分割点
- left和right是待处理的子数组的下标区间(我们取开区间,即left指向子数组第一个元素,right指向子数组最后一个元素)
- 下文所谓的指针都指代数组下标
单趟排序算法实现思想:
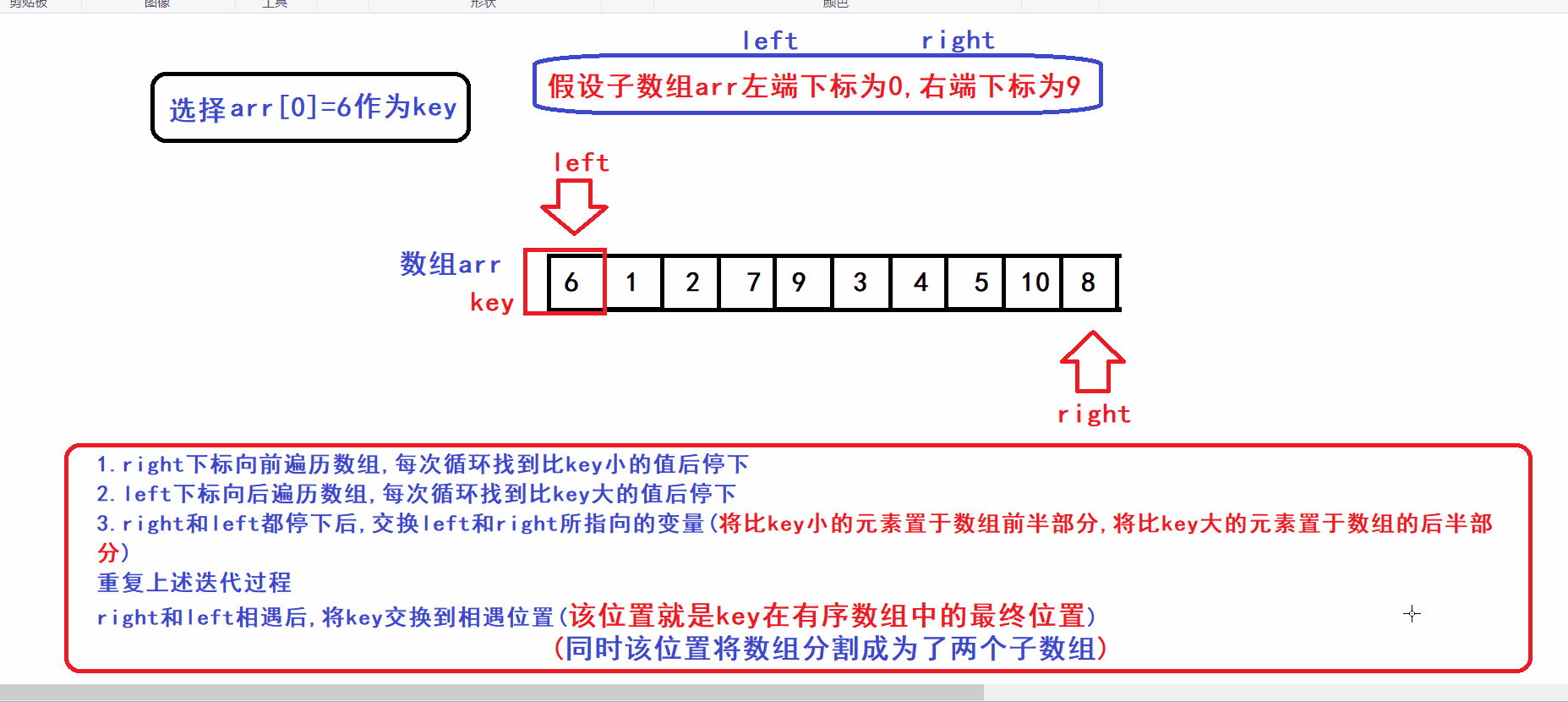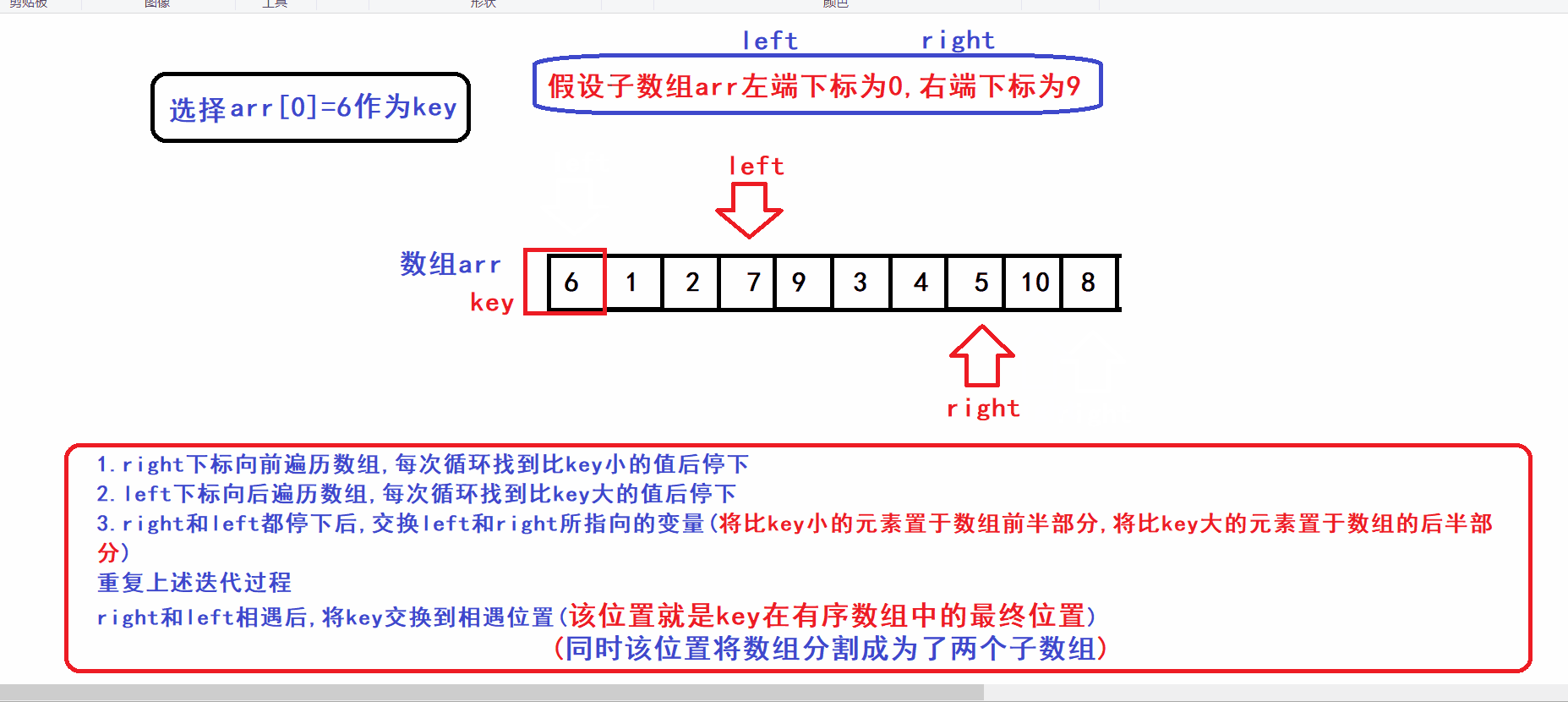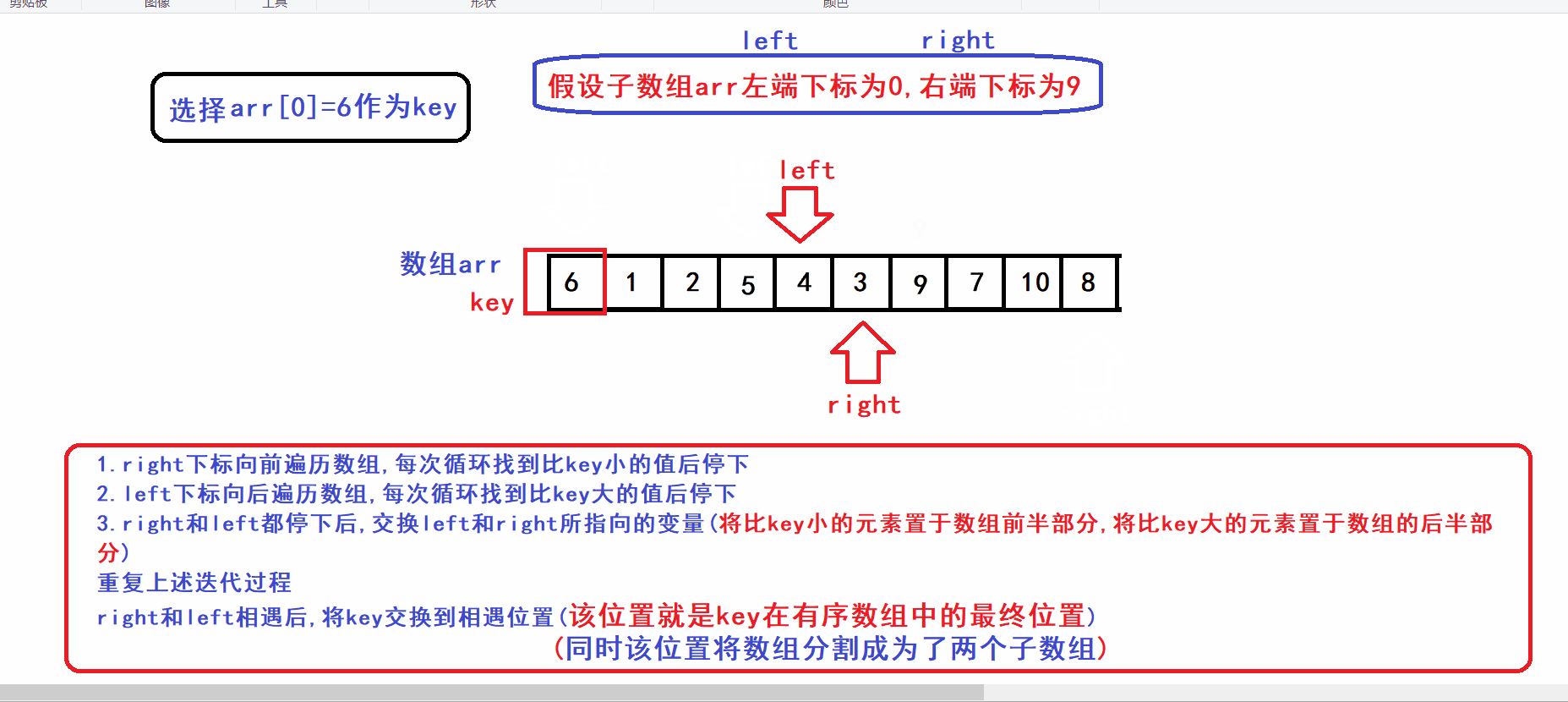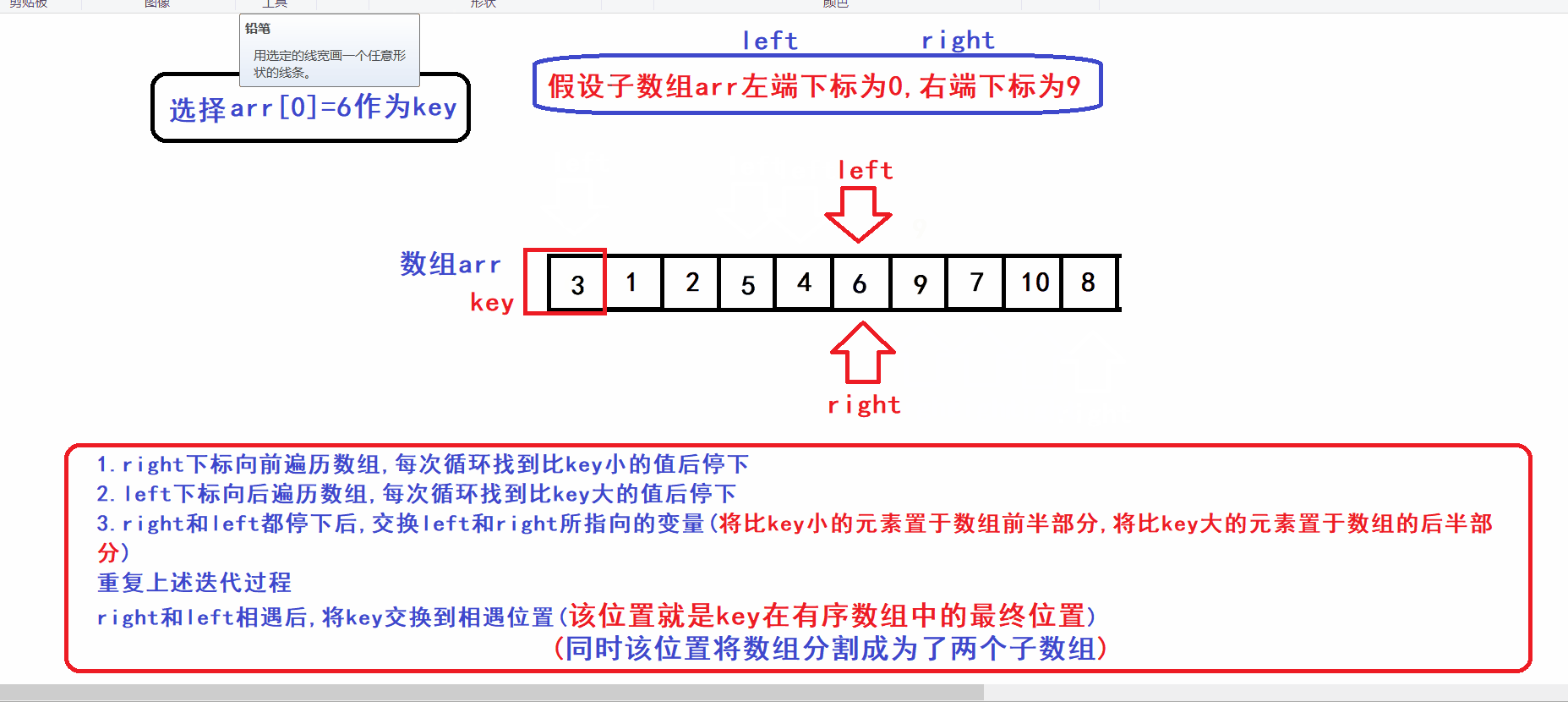
- 选取arr[left]作为key元素(key变量作为下标指向key元素)
- right指针向前遍历寻找比key小的数,找到后停下
- left指针向后遍历寻找比key大的数,找到后停下
- 交换left和right指向的元素,重复上述迭代过程,直到left指针和right指针相遇
- left指针和right指针相遇后,将key元素交换到两指针相遇位置(此时保证了两指针相遇的位置之前的元素都比key小,相遇位置之后的元素都比key大)
- 算法流程中相当于用left下标来维护由比key小的元素构成的数组前缀,用right下标来维护由比key大的元素构成的数组后缀
- 算法gif:
代码实现:
//hoare版本的左右指针法 //取数组首元素作为key则必须让右指针先找比key小的变量 //取数组尾元素作为key则必须让左指针先找比key大的变量 //left下标用来维护由比key小的元素构成的数组前缀 //right下标用来维护由比key大的元素构成的数组后缀 //以key最终位置为分割点将数组分为两个子数组,前半部分(前缀)数组中每个元素都比key小,后半部分(后缀)数组中每个元素都比key大 int PartionV1(int* arr, int left, int right) //完成1个元素的排序,同时分割数组 { assert(arr); int key = left; //取子数组首元素(下标为left)作为key while (right > left) { while (right > left && arr[right] >= arr[key]) //right下标寻找比key小的值 { --right; } while (right > left && arr[left] left的条件防止两指针错位 - 选择arr[left]作为key元素一定要先让right指针向前找比key小的值,不然会出现以下情况:
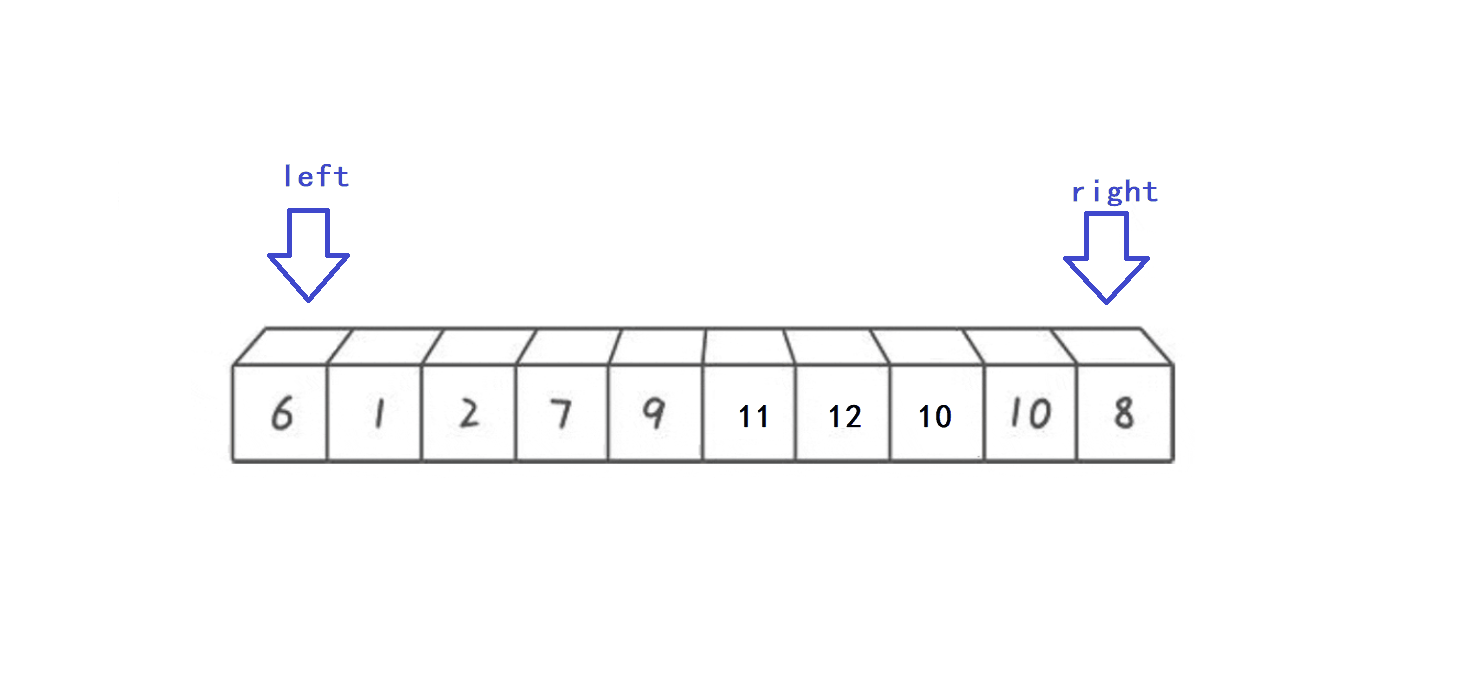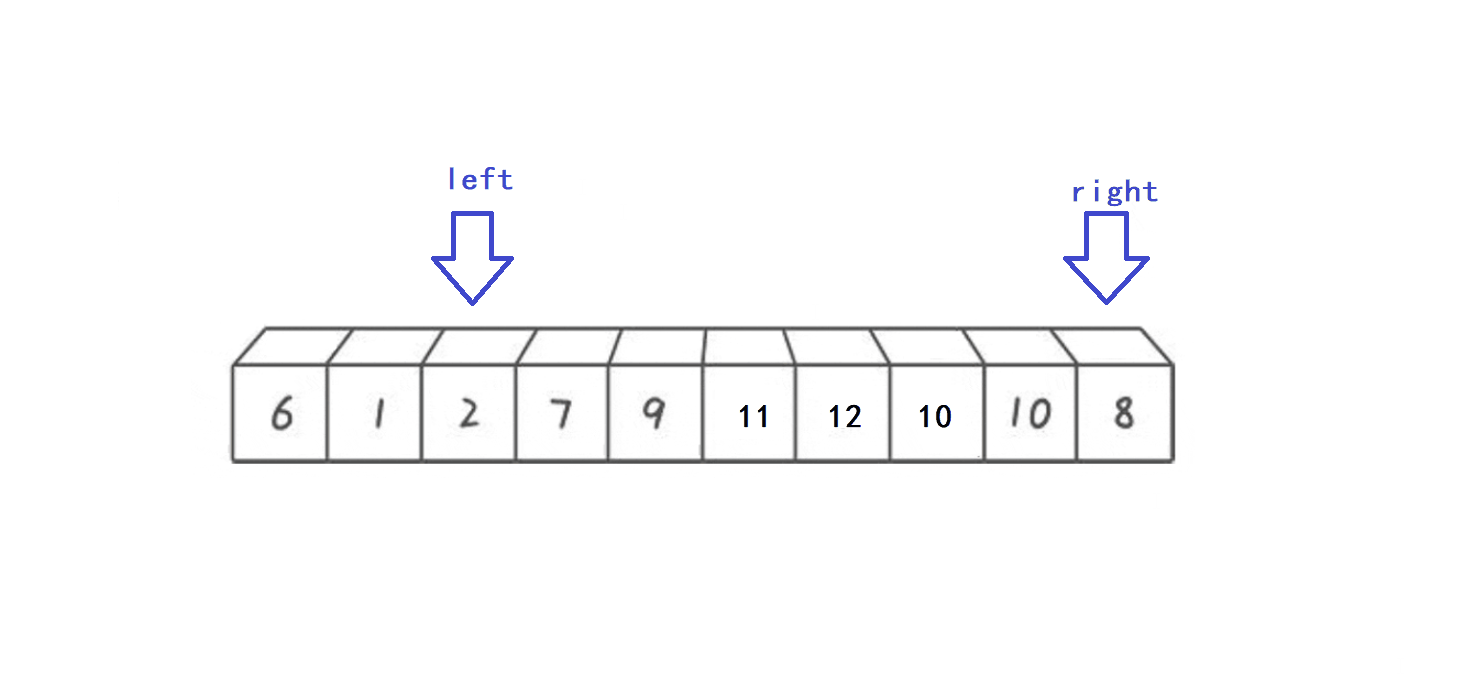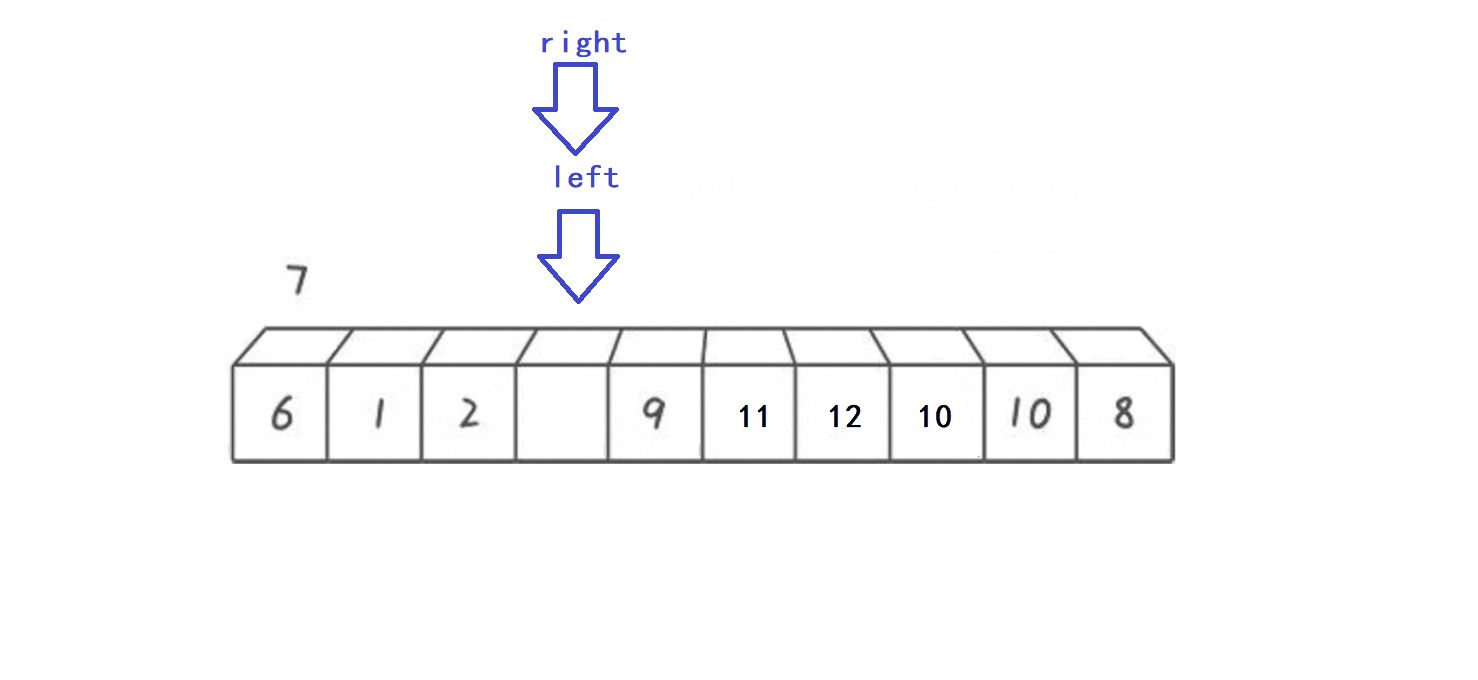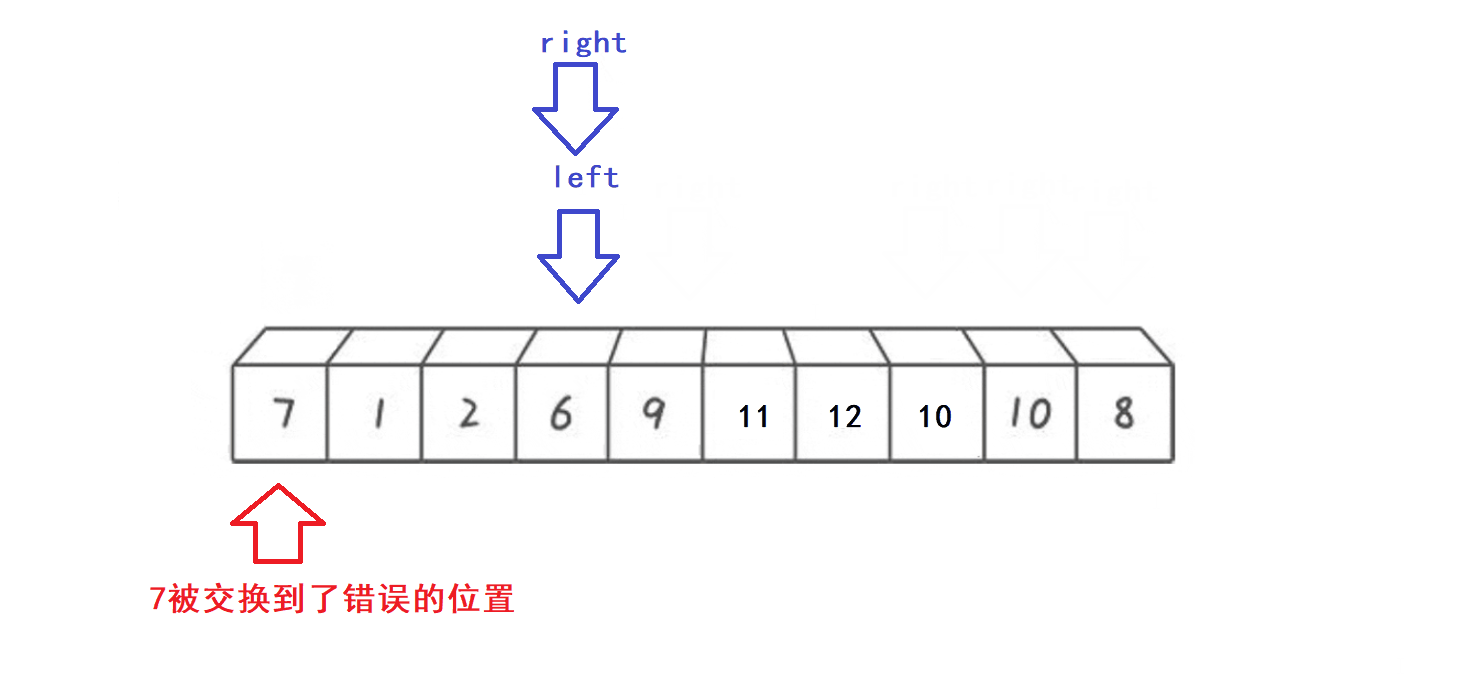
- 算法接口首部:
int PartionV2(int* arr, int left, int right)//完成1个元素的排序,同时分割数组
-
left和right是待处理的子数组的下标区间(我们取开区间,即left指向子数组第一个元素,right指向子数组最后一个元素)
单趟排序算法实现思想:
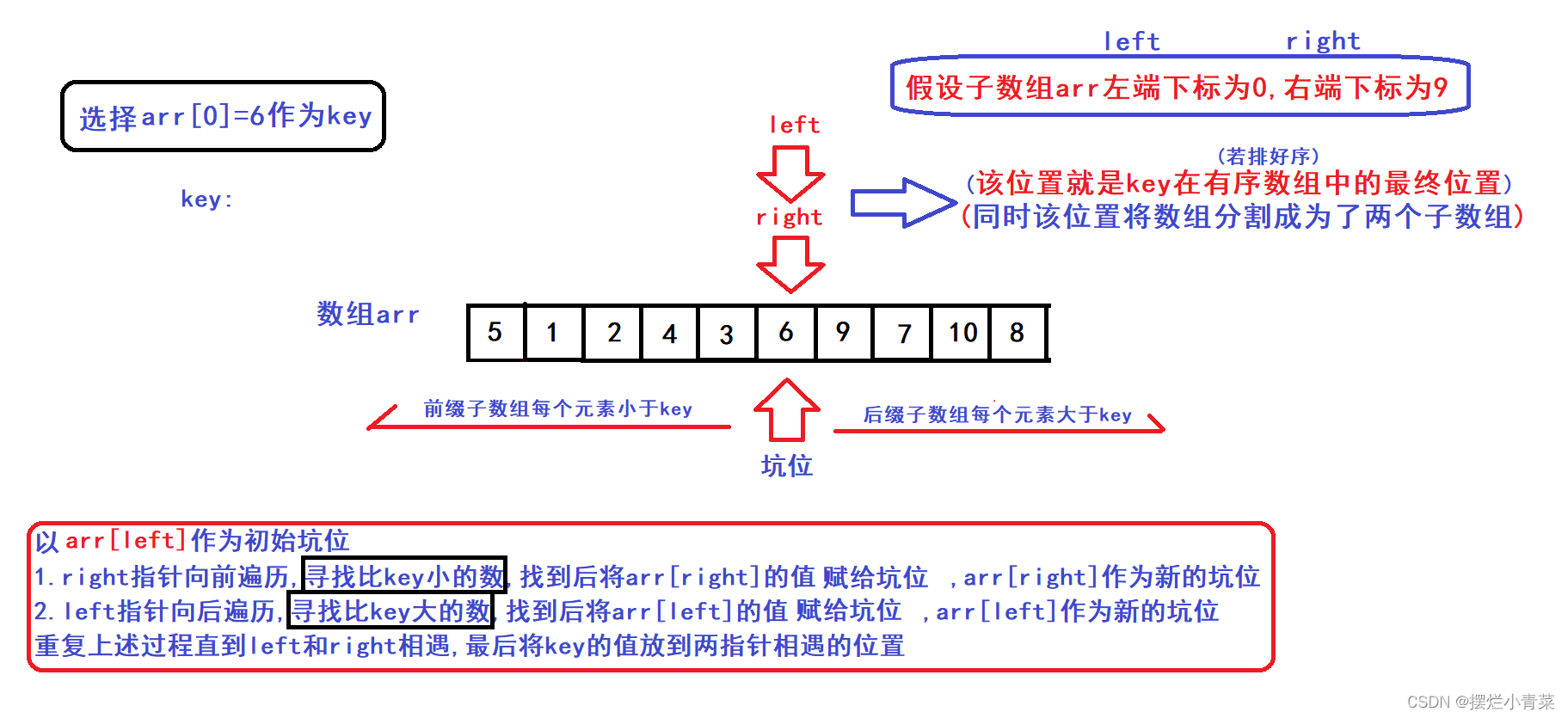
- 选择arr[left]作为key元素(key变量存储key元素的值)
- 以初始left指向的位置作为初始坑位(坑位下标用hole变量来记录)
- right指针向前遍历寻找比key小的数,找到后将right指向的元素赋值到坑位上,将right下标值赋给hole(更新坑位)
- left指针向后遍历寻找比key大的数,找到后将left指向的元素赋值到坑位上,将left下标值赋给hole(更新坑位)
- 重复上述迭代过程直到left指针和right指针相遇
- left指针和right指针相遇后,将key元素放到相遇位置处完成单趟排序(此时保证了两指针相遇的位置之前的元素都比key小,相遇位置之后的元素都比key大)
- 同样地,算法流程中相当于用left下标来维护由比key小的元素构成的数组前缀,用right下标来维护由比key大的元素构成的数组后缀
- 算法gif:

代码实现:
int PartionV2(int* arr, int left, int right)//完成1个元素的排序,同时分割数组 { assert(arr); int key = arr[left]; //取数组左端元素为key int hole = left; //取数组左端位置为初始坑位 while (right > left) { while (right > left && arr[right] >= key) //right下标寻找比key小的值 { --right; } arr[hole] = arr[right]; //将right位置的变量放到hole位置上 hole = right; //更新坑位 while (right > left && arr[left]
单趟排序实现的方法二:挖坑法
- 🤓利用双指针算法来设计单趟排序过程以达到以下目的:在数组中选取一个key元素,将比key小的元素交换到key元素的左边,将比key大的元素交换到key元素的右边







