

作者·夏虫
『数据虫巢』
全文7685字
图·丽宁十八弯

“ 大模型AI,作为当红炸子鸡,而商业化广告,顶级的现金流业务,当他们碰撞在一起的时候,会产生什么样的火花呢?”
为什么要聊大模型与广告?
广告自然不用多说,系列到了第三十八篇,其实前面章节聊过了广告的业务,中间十几个章节聊了广告的整个智能化链路,包含了定向、召回、排序、重排等等。按我的规划,后面几篇依然可能会侧重于技术,但是可能就不是当下技术了,而是未来技术。
本来规划的是广告领域中的“端云协同”话题,大纲都有了。而广告与大模型也在规划中,但是要更往后了。
因为,我看不太清。其实我一直是有意的不去聊大模型跟AI话题的,因为一开始我觉得为时过早,虽然我自始至终都认可AI在实际生产中的价值空间,但不是现在,而是未来。而就是那个“未来”,我一直觉得还很远。
直到现在,发生了很多事,让我重新去审视我之前的观点。
我身边越来越多人投入其中了(有做底层LLM的,也有做应用的,也有投入其中做培训做科普的),然后一些实际出来的东西,突然发现好像也勉强能用了,而最后不巧的是,我团队里也不可避免的开启了与之直接碰撞的进程。
于是,这段时间我反复跟不少人在聊这个话题,因为我想了解的更细一些,从不同人接触大模型的不同角度,从国内到国外,从底层参与者到中间布道者,再到实际行业影响者。
关于这个话题,回头再聊,这篇核心还是广告,大模型是“加挂”的属性。
聊广告与大模型的“搞对象”的可能性之前,我们先简单做个大模型AI的科普吧。
不知根不知底,上来就来肉戏担心大伙儿消化不良。何谓大模型,何谓AI,有什么影响?


01
进化的AI
什么是人工智能?或者说如何去定义他。
其实这个概念在很早之前就有了,包括深度神经网络等模型,其实很早之前就出现在论文里了,但对于行业并没有产生一些质的影响,甚至在普通人的思考逻辑里,总会觉得这些东西里现实太远太远。
直到2016年的时候,AlphaGo横空而出,竟然干败了世界围棋冠军柯洁。原来魔法,啊不,是科技,真的可以干掉人工的,甚至是极致的“专业”。
虽然是在某个单一领域里了,但已经足以引起轰动了。科技是真的可以做到比人工更加智能的,并且是有可能取代人工的。
于是,引发一波人工智能讨论的热潮。只是说这波热潮并未持续太久,并且并未做过多的扩散,核心在于AlphaGo之后,人工智能突破领域,并未太多侵入到常规生活中,之后各家发布的一些人工智能的模型,更多还在于逻辑推演,更切确的说还在游戏领域里绕,比如AlphaGo干败了围棋,明天又出来一个说干掉了象棋。
诸如此类,整体还是在一个相对“高端”的领域里打转,所以,就算是声量传播还是在相对小众的领域,对于普通老百姓的吃穿住行并未产生过多的影响,并且之后在其他领域并未有质的突破,时长一长,自然热情消退了。
对于一些高端话题,更多普通人的热情和记忆是短暂的,本着“吃瓜”的逻辑嘛,时间一久,自然瓜已不甜,瓜已不成瓜,自然更多去关注自己的“柴米油盐酱醋茶”去了。
直到Chatgpt的横空出世,代表LLM大模型的到来。大家突然发现,电影上的“贾维斯”好像是有可能出现的。
你跟他唠嗑,他真的能跟你各种唠--真有意思!但很多人很快的就发现,不单纯是真有意思了,还有可能影响自己的生活,部分人甚至被影响了自己的“柴米油盐酱醋茶”。
Chatgpt开启了“潘多拉”魔盒,随着各类LLM模型的百花齐放,很多时候你都分辨不出来跟你对接聊天的到底是真人还是机器人,文章以及一些自媒体的内容生产效率大幅提升了,很多人已经开始依赖AI进行了生产。据说,有些自媒体的生产效率已经提升了好几倍。你说,那些不懂与时俱进的小编们不得瑟瑟发抖。
还有美工们。我邻居自己有个工作室,有天我发现他发的朋友圈在感叹,AI画图真的太牛逼了。随后跟他聊才发现,他们已经在利用各种付费的AI产品,帮助他们设计工作室做输出了。当然,不是一键生成的那种,而是依赖于AI产品帮助他们快速生产素材,甚至是短动画,然后他们再在这个基础上做串联和微调--半人工智能。
哪怕是半人工智能,也能帮他们做50%左右的工作,意味着缩短他们工作室近50%的时间和人力--人还是这些人,这意味着他们可以接更多50%的活进来。
还有小红书上的AI生产的图文内容,知乎上、公众号上一些附加了“此内容为AI创作”的标记(俺们的内容,大概率当前AI还搞不太定),先不说输出内容的可用性,但从覆盖面的角度来看,已经有点影响到普通人了。
话说,还真有边上的朋友依赖于大模型的一些现有产品文字能力,去做快速创作的,了不起加点二次加工和编辑嘛,省了多少资料采编、内容调研,排版的工作。他们利用这些半AI的能力,从能干一件事,变成了能干十件事(可能还需要人工介入)。有些身边的人,真的用他批量生产内容,靠拿自媒体内容的流量广告费,一个月也有几千的外快。
这就是改变了一些局部生产力的逻辑了,不再是高高在上的“AlphaGo”了,只能在特定高高在上不接地气的一些领域里炫技,而是影响到了很大一部分普通人的生活,以及其生产效率了。
以前大伙儿调侃一些对话机器人,喜欢称之为“人工智障”,或者说有多少人工就有多少智能,但Chatgpt出来之后,不说他多智能吧,但多少不能说他是“智障”了。纯交互式语言大模型LLM来说,可能还不是那么智能,单就论他集成的资料集合,你就说谁能拼的过他吧。
所以,目前很多人将他用作一个超级无敌大型的资料库来用,将他当成资料整合工具来用,用他当作编辑来用,看着很傻,但实际上是颠覆了很多领域。
人工智能,已经从过去的单一且不接地气的领域里,逐步拓展了常规领域,并且真的让普通人能够用的上他了,可以体验了,部分人甚至已经用他来提升生产效率了。
至于说,对于行业的完全颠覆,还为时过早,但他已经在肉眼可见的进化了,并且让普通人能够触摸他,体验他,甚至利用他。
知乎上,有人向我问,说2024年政府报告上提了“人工智能+”,又是什么噱头。2015年提到的“互联网+”,如今2024年,互联网加了啥?好像说不出来,但好像现在目前生活的方方面面真的好像都离不开互联网了,最直白的来说,好像吃穿住行都可以互联网化了,哪怕是一个小县城,只不过程度的问题。
不行了,这个子话题不能再延伸下去了,我们公众号的大主题还是技术嘛,而这篇的核心主体还是商业化广告。
总之,AI真的在进化,特别是LLM大模型出来之后。但他到底怎么个进化逻辑 ,为什么可以做到这点,我们还是要去看看,不说深究,好歹不能停留在体验层。
但要从技术层面说清楚,但又不能平铺论文的逻辑和数据公式,还是有点挑战的。


02
人工智能与LLM
高深的东西往往从很浅显的地方说起,会更容易理解一些。
那我们就一下子浅到底,回到传统机器学习时代,来到LR(线性逻辑回归)这里。相信,这个基础,绝大部分人还是有的,不至于一下子听天书。
线性逻辑回归解决的是对于目标可能性的预测,并且假设一个事物的概率是受若干独立假设的(X1X2...Xn)因素影响的。
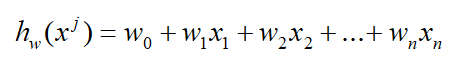
这是人工智能吗?换以前,我可能会跟绝大部分反应是一样的,这算哪门子的智能?
但是实际上,这个数学公式逻辑是具有一定合理性的,他假设人的思考逻辑是非常直白的,将一个事物量化成了若干影响因素,并且量化权重了。比如,假设判断一张图片上的动物是不是鸟,量化成了嘴巴形状、脚形状,是否有羽毛,是否有翅膀,会不会飞之类的若干条件。
简单事物的判断逻辑确实是这样的,几个条件下来,基本就可以做判定了。但很多时候,真实情况往往不会这么简单,并且很多时候单个条件是不可能完全互斥的。比如男女为例,大部分时候头发长度与性别是强关联的,身材也与穿衣特性强耦合。这里要表达的观点是,特征之间并不能完全的去以独立事件去看待,很多时候关联一起出现的概率,或者互斥出现的概率对于结果的预估是有很大帮助的。
从实际的推演过程也知道,对于有限的特征,假设独立事件的影响本来就不够合理,事务是复杂的,并不是单一属性所决定的,而是若干复杂的因素相互影响而产生的结论。
所以就有了类似FM之类的模型。
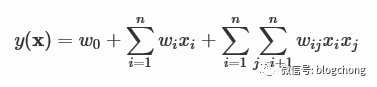
将影响因素从单一变量,扩展到了两两之间的关系,组成了若干个两两个关系对,共同对结果产生影响,底层逻辑依然是LR的逻辑,在单一影响因素的基础上,叠加了两两因素的组合影响。
本质上依然在模拟真实的决策过程,只不过这种模拟处于非常基础的程度上。我们实际决策过程,一定是叠加了非常非常多因素在里头的。如果考虑人类的思考过程,把神经元传导逻辑拿出来,这不就是深度神经网络的决策逻辑了吗。
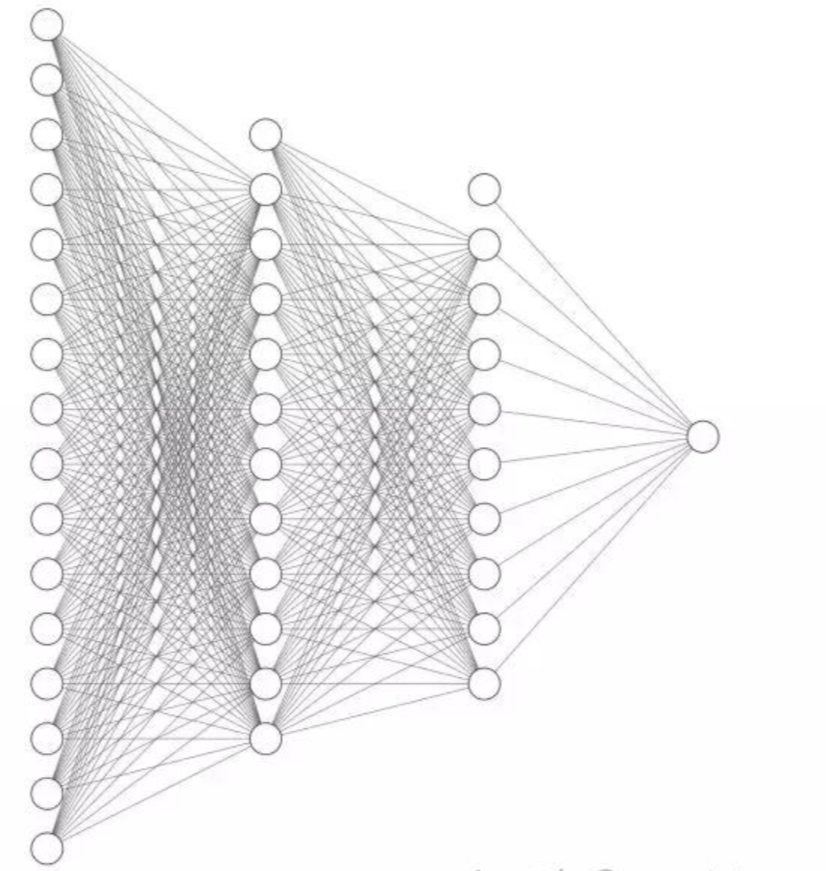 类似于这种的网状结构,每个决策节点受上游无数多的神经元的判定所影响,如果我们把上游的这些初始输入当成我们的经验,那么末端节点就是我们的决策,那么中间就经过了无数的因素考虑,无数的神经元判别,最终行程了最终的决策逻辑。
类似于这种的网状结构,每个决策节点受上游无数多的神经元的判定所影响,如果我们把上游的这些初始输入当成我们的经验,那么末端节点就是我们的决策,那么中间就经过了无数的因素考虑,无数的神经元判别,最终行程了最终的决策逻辑。
这就是深度神经网络,也是深度学习模型的假设基础。你看,离人类思考逻辑越来越近了。技术的每一次迭代,其实都在尝试让机器的决策逻辑越来越趋近于真实的人类逻辑。
这不是人工智能是什么?只不过其智能的程度逐步的在提升而已,以及哪怕是我们所遇到的常规深度学习的网络,虽然较之于传统机器学习,典型如LR之类的,已经进化太多太多了,但是离真实的人类判定能力,还是有差距。
虽然,硬件的迭代已经能够支持复杂的神经网络结构进行推演,但是离真实的决策逻辑还是有点差距,哪怕是AlphaGo,其本质逻辑依然离不开常规深度学习的逻辑范畴。本质上依然是对于历史所有的棋局作为输入,当前输入的下一步作为前置变量,去预估下一步动作对输赢的最大概率的预估。
所以,他依然是一个高度抽象出来的逻辑,在类似于游戏这种高度垂直纵向的领域,约束住了问题求解的范围,所以表现相对还好。但是,离真实的常规日常场景的决策逻辑依然差太远。
直到Transformer的出现,更具体的来说是利用这种机制的BERT模型,这才是一个划时代的东西。这东西出现在2017年,但实际上Chatgpt开始引起热潮的时间节点是2022年,但实际来说,从技术角度,真正的变化是2017年Transformer的出现。
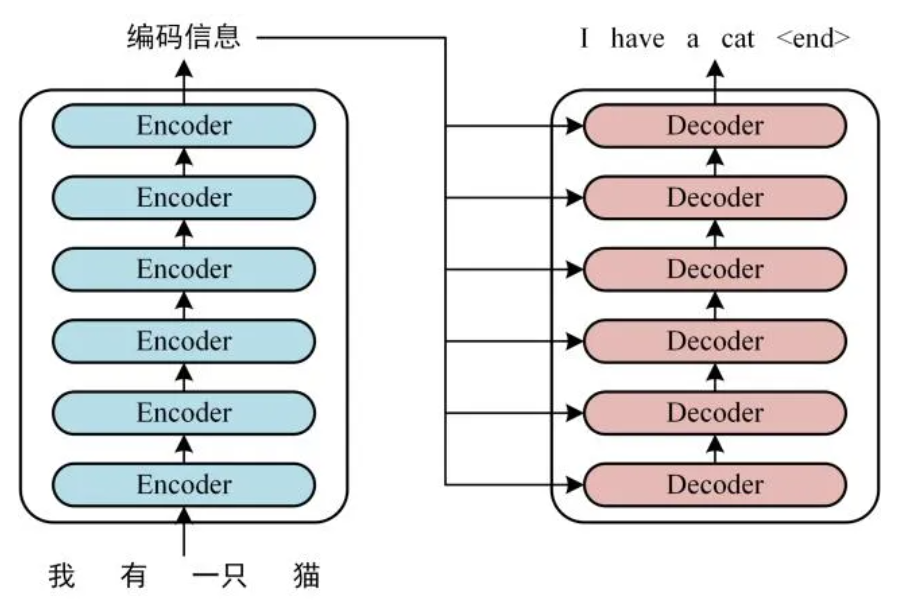
如上是Transformer典型的Encoder和Decoder结构。
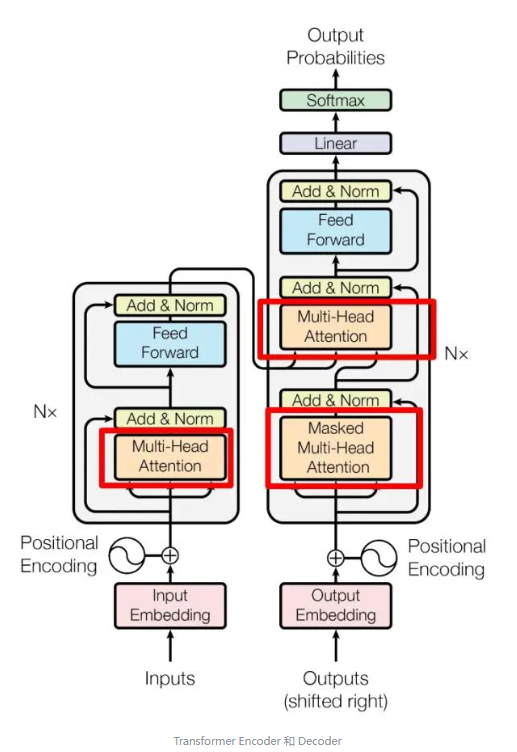
跟普通的DNN比较,最核心的前向反馈机制传播,激活函数逻辑,即最底层的神经网络的东西其实并没有不同。但是他独有的Self-Attention机制,以及上下文中的一些Mask机制,可以让模型学习到上下文潜在的一些局部特征,并且Mask机制原理可以让自监督学习这个事成为闭环(Mask掉序列输入中的部分,从而构建因果关系对)。两个不一样的机制和动作,让Transformer这个东西,可以在不断学习的过程中,逐步让模型输入的上下文非常敏感,各种潜在的输入变化因素对于输出的影响。
即,这个模型对于输入的上下文变化是非常敏感的。
看着好像也没啥,只是对学习的机制做了一些改动,但就是这些改动,让模型对于上下文,对于输入的细微差异理解有了质的提升。当然,这里质的提升的前提是海量的灌数据,有了海量的数据,并且结合注意力机制(Attention)让模型学习到这种上文的差异,并对输出产生差异影响,变得更“智能”。
而人的决策逻辑中,也同样,历史的经验对于当前事务的判断。我家有2个小孩,大的小学了,一点一点的去灌输他一些做事逻辑,知识,认知,其实是一个漫长的过程。你可以认为是人去不断建立自己的一个认知模型的过程,对于他来说,之前成长的每一件事可能都会对下接下来发生任何一件事做的反馈,产生影响。
只不过说,之前的一个事,一个动作到底产生多大的影响,但通常一个反馈动作一定是有重要的一些影响经历和不重要无关的经历所组成的,并且在人的行为决策逻辑里是很难去量化的,只是不断沉淀为经验和建立起情景反馈与某些经历特征之间的关联性(这就是说历史经历过的场景对于我们来说是可借鉴的本质逻辑)。
而机器和数学要做的事则是学习这种行为模式,并且尝试去建立起这种历史数据对于真实情景(最近的上文)的反馈逻辑。而这里的历史行为经验,对于人来说可能是10年20年的所见所闻所想所行,那么对于GPT来说,如果有了一套量化和反馈的逻辑,接着就是灌数据了。
所以,核心点来了--海量的数据。现实确实如此,以第一个集Transformer大成的框架BERT为例,吃的可是维基百科历年攒下来的数据呀。目前大部分基于BERT做的衍生,都是基于开源BERT之后的微调,底座模型的那个数据量跟算力并不是一般公司可以承受的。
所以说,Transformer才是弯道转弯的拐点,后来的LLM模型,以GPT为例,本质上并没有超出Transformer框架的范畴,只是改动了Decoder部分的逻辑,更加关注上文对于下文的推理,比如通过大量的Mask上文,从而构建对下文的推导逻辑。
其实BERT的mask中间随机或者一些其他机制更偏向于让模型去学习整体的理解,实际上是有点像做完形填空题
而GPT的逻辑其实更偏向于对未知推导的,所以根上并没有拉开质的差距,所以我说2022年是人工智能再次爆发的一年,但从技术的角度上说,2017年Transformer结构的出现才是转折点。
在原有的Transformer框架上做微调,更加侧重于基于上文对于下文的推导,并更关注上文输入的校准,另外更核心的就是算力的迭代和堆数据了,GPT领域真的诠释了什么叫量变产生质变。
你看,从技术的角度上看,从LR时代开始,其实技术从业者(包括数学家)都一直在致力于让数学和机器去模拟人的思考过程,而在GPT时代,越来越贴近于他了而已。
那么未来呢?


03
AI化的原生广告
知乎上有人问我,今年政府工作报告提到的“人工智能+”是什么东西?是不是又是什么噱头。
这让我想起了这15年的政府工作报告提过的“互联网+”概念,回想一下,时间已经是9年过去了。最起码在中国,整个吃喝住行逻辑,基本上都被互联网的逻辑所覆盖了。当然,你可以说还有线下实体、各种工业之类的。虽然不那么全面,但不可否认的是也都在或多或少进行数字化转型,或者某些维度跟互联网进行了挂钩。
回到2024年的今天,这个概念的出现。有人会说中国没有AI底层的研发能力,或者说GPU没有自主权之类的。我觉得都是现存的问题,但从我身边很多CASE可以看到,实际上AI真的已经在影响到一些普通人的生活,甚至影响了某些人职业,或者或多或少的提升了不少生产效率(关于这个话题,我们再开篇再聊,都是身边的实际例子,之前的我也没有意识到实际上已经侵入了)。
扯太远了。人工智能已经已经在路上了,自然不能落了商业化广告领域。
我们所经常听到的所谓大模型的参数量,好像参数比输了就更low似得。但也不尽然,比如传闻说GPT4.0参数量已经4.0的参数已经是二十几个亿了,国内某某厂发个大模型,怎么也得翻个什么倍啥的,但用起来也确实跟Chatgpt比傻傻的有代差感。
但总的来说,参数代表的确实是对于所有状况的模拟能力,本质跟LR的特征权重的个数没有根上的差别,都是量化了对于事物的拟合能力。
但想个问题,稍微复杂一些的常规NN网络,如果叠加了一些特殊的推理网络结构,比如多交叉几次,再多来几个线性层,再来点Atention机制啥的,都会让你的在线实时推理慢的不要不要的。所以,很多精排模型真实上线的时候都要一顿裁剪网络,而所谓的裁剪网络本质上就是减少参数量,让在线的业务在真实过模型的时候少做一点推理逻辑的执行。
回到LLM的参数量,哪怕真实在线部署的推理端,做了很多裁剪和工程优化动作,实际上在在线的实时大规模预估推理这块依然不是他的强项,所以在当前商业化广告的核心链路里,比如召回、精排之类的是有点难产生影响的。
但是,从实际的一些案例角度上来说,以目前半AI的图文表达能力,以及生产能力,实际上已经有不少人在做广告的加速了。核心在于广告的素材生成上。比如主动生成更具有转化效应的广告标题,投手用他来快速生成各种投放素材等。
这是已经在发生的事,并且对于整个广告的投放端的效率甚至是效果来说,是真的能产生一定的生产效率的。
但是他没办法改变广告这种生态结构--即可以提效,但是没法根上改变广告这种模式,只能起到辅助的作用。没办法说在整个广告生态逻辑里,对广告行业产生巨大的变革性的东西。
其实也不尽然。
很久之前说过,广告最大的问题在于打破了原有内容的逻辑,导致了这种模式产生的内容会很突兀,让用户不适,这是广告诞生了多少年以来都存在的一个问题。
但有一种广告,会让用户觉得“赏心悦目”一些--原生广告。
原生广告是从网站和App用户体验出发的盈利模式,由广告内容所驱动,并整合了网站和app本身的可视化设计(简单来说,就是融合了网站、App本身的广告,这种广告会成为网站、App内容的一部分,如Google搜索广告、Facebook的Sponsored Stories以及Twitter的tweet式广告都属于这一范畴)。
这段话是我从百科上抄的,但大差不差。从字面上都好理解,所谓原生即对于原有媒体的内容的侵入性很低,并且对于用户的吸引力也不低。从字面上也透露出了满满的高端大气上档次的铜臭味。
是的,熟悉广告业务的人都知道,原生广告是所有广告类型中单价最高的,投放成本也高--整个制作以及对于上下文环境的要求是非常之苛刻的。所以,很好用的广告模式,但很小众。
有没有一种低成本的方式去构建他,让广告的侵入性更低一些,让广告转化更高,让媒体觉得整个调性是一致的,让用户觉得看广告貌似也不那么难受?实现一个三方共赢的局面。
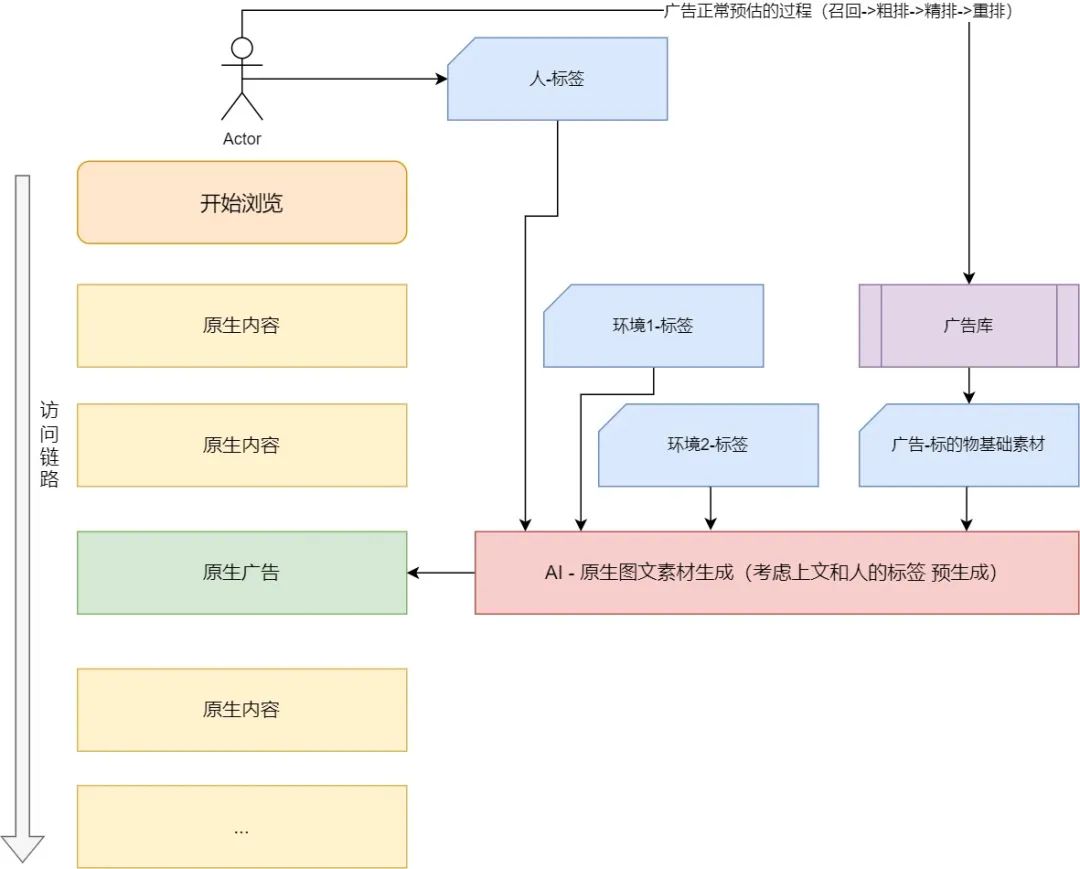
LLM擅长的就是上文输入,下文的图文输出。广告的选择逻辑依然不变,走的还是传统的召回粗排精排三连发,选择一个eCPM最高的广告。剩下的包装就交给AI引擎吧。
从入口处捕获用户的标签,随着用户浏览的原生内容不断抽取出来的关键标签(来表征上文),再结合广告库最终的Ad选择(核心标的物),生成一个“真假难辨”的原生广告出来。
试着想想下,你在刷视频流,点开一个广告短动画,发现跟之前的信息完全没有违和感(视频流广告);在看文章,点开一个广告,发现里面富含了前文类似的丰富内容,里面的图片,文字都没有任何的违和感(信息流广告);试想下,你在用阅读器看小说,上一章刚完描绘的是霸道总裁开着他的大米汽车,下一页跳出来的广告动画完全把刚才的情形给重现了,只不过汽车换成了“比油低”的“春秋战国”,是不是也蛮有画面感的(联盟广告中小说APP的场景)。
这样一想,其实广告也没有那么讨厌了,甚至还可以带来一点点小惊喜,看个广告都跟猜盲盒似得。
以现在大模型以及人工智能的能力,估计也就只能帮助小编或者投手做做素材,并且做完了还得让美工微调的那种。
但是不可否认的事,如果我们把时间线拉长点,也不用太长,3年5年,我相信类似上面的逻辑场景不会远的,因为其实也并不复杂,只需要让AI的模型稍稍再进化一下。
就能带来商业化广告领域根子里的那种变化,让相互引流变得更顺其自然,甚至是毫无违和感,对用户是一种信息放大,对于媒体渠道是一种内容加强,对于广告来说自然而然的是转化提升。
我们拭目以待,以此文为证。
夏虫评说
整个这篇的逻辑还是非常清晰的,广告老夏我自然是熟的,而对于人工智能,不说很熟,但是最起码不陌生吧。只不过之前一直很少很认真的去思考过AI的问题--我一直觉得还为时过早。
直到有一天,我身边的普通的人在问我AI是怎么回事,做大模型的选手在问我业务如何落地,朋友圈有人在做培训,隔壁的邻居做设计工作室的50%内容已经承包给AI引擎,朋友圈都在聊李一舟(关于这块,后面会专门聊一聊这个过程和经历)。
我突然发现,我落伍了。
我好歹得去了解下吧,不能再像之前那样闷头不理会了--世界在变化。一番了解,看信息,找人聊请教之后。我突然发现,人工智能这东西并不是李一舟说的那样高端大气上档次,但也绝对不是说对社会没啥卵用都在炒概念。
你可以说他至今为止还没有对社会产生变革性的影响,但不能说没有影响。可以说现在聊AI能翻天为时过早,但不能不预估未来的可能性。
最起码,我看到了这种可能性,我说的这种可能性是以5年10年的角度去看的,并且已经逐步对社会部分领域开始“蚕食”的逻辑。
你可以不参与他,但是得正视他和了解他,这就是我目前对他的态度。
笔名“夏虫”,源自于我的另一个非技术公众号【夏虫悟冰】:以敬畏的眼光看待世界,在思考中成长自己。当然,笔者还有另一层身份,10年互联网大数据以及算法经验,创过业,也有日均数十亿分发流量的商业化广告经验,专注于搜推广以及企业数据化、智能化建设,目前在一家还算行的上市电商公司做海外业务,负责中台能力建设,目前更多关注点在国际化电商的大数据、搜推以及商品、运营、人中台等底层能力的建设。
与不同的人交流,才有会进步。三人行则必有我师,最近开始关注AI以及大模型相关的话题,也欢迎一起交流(微信:mute88,添加请注明来意)。另外,团队在在寻求一名资深中台产品,需要有国际化电商产品的经验,岗位有带产品团队的诉求。
技术主公众号当然是【数据虫巢】,之前有整个《数据与广告系列》,目前逐步趋近于收尾,关于这个系列后续更大想法是逐步整理成更为体系的书籍,这个后面再说了。后续这个号,会逐步关注于大模型与人工智能,以及国际化业务大数据、搜推以及智能化中台建设的内容。
而非技术公众号【夏虫悟冰】,也会继续更新,关注更多非技术的输出,保持对这个世界的思考,偶尔发发文青梦。欢迎大家关注,或者推荐给朋友。技术之余,依然要有“诗与远方”,一起努力和加油。
【夏虫悟冰】上之前的一些文章:
《2024:守刻缓本心驻足,持信仰之刃狂奔》-- 一年一度的总结和思考。
《互联网的落日余晖》-- 虎嗅文体,描绘当下。
《乌克兰:散装的历史与撕裂的未来》--历史文,感受那种剧烈的历史冲突感。
《爷爷与侠客行》--新文风,人物小传,时代的感叹。

文章都看完了,还不点个赞来个赏~







