

2023 Mask R-CNN 改進:DynaMask: Dynamic Mask Selection for Instance Segmentation 論文筆記
- 一、Abstract
- 二、引言
- 三、相關工作
- 實例分割
- 動态網絡
- 四、動态 Mask 選擇
- 4.1 雙層 FPN
- 區域水平的 FPN
- 特征聚合模塊 FAM
- 4.2 Mask Switch Module (MSM)
- 最優的 Mask 賦值
- 采用 Gumbel-Softmax 的重參數化
- 4.3 目标函數
- Mask 損失
- 邊緣損失
- 預算限制
- 五、實驗
- 5.1 實施細節
- 5.2 主要結果
- 與 Mask R-CNN 的比較
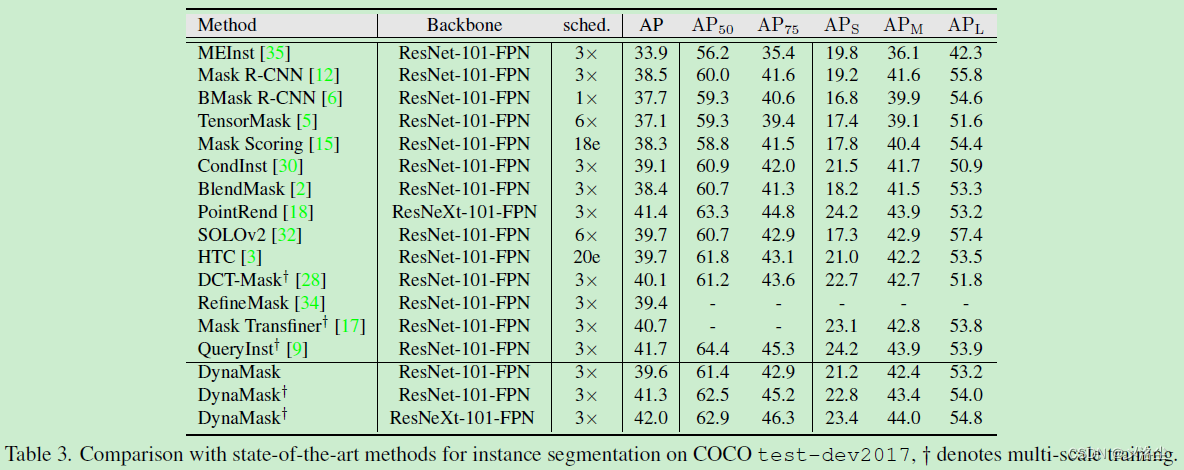
- 與 SOTA 的方法比較
- 分割結果的可視化
- 5.3 消融實驗
- Mask 分辨率預測
- 預算限制的影響
- 不同方法的速度比較
- Mask 尺寸的影響
- 基于尺寸的 Mask 選擇方法
- 六、結論
- 七、補充材料
- 7.1 關于 Mask 分辨率預測的分析
- mask 分辨率和類别之間的關聯
- Mask 選擇的結果
- 7.2 預測的 Mask 分辨率分布
- 7.3 在 LVIS 數據集上的結果
- 7.4 與其他 FPN 變體的比較
- 7.5 定性結果
寫在前面
本周更新的第二篇論文閱讀,2023年每周一篇博文,還剩5篇未補,繼續加油~
- 論文地址:DynaMask: Dynamic Mask Selection for Instance Segmentation
- 代碼地址:https://github.com/lslrh/DynaMask
- 收錄于:CVPR 2023
- 歡迎關注,主頁更多幹貨,持續輸出中~
一、Abstract
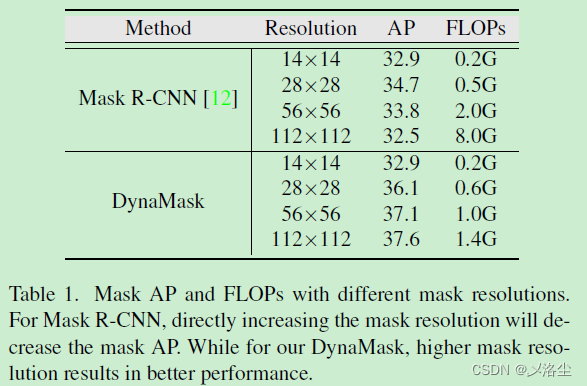
一般的實例分割通常采用固定分辨率大小的 mask,例如 28 × 28 28\times28 28×28 的網格來劃分不同的目标。然而,低分辨率的 mask 經常會丢失豐富的細節信息,而高分辨率的 mask 會使得計算量成平方增長。本文針對不同的目标 proposal 提出一種動态選擇合适尺寸的 mask 方法。首先:一個自适應特征聚合的雙端 FPN 用來逐漸地增加 mask 網格分辨率。具體來說,一個區域級别的自上而下路徑被引入來整合不同階段的圖像 FPN 層的上下文和細節信息。之後提出一種 Mask Switch Module(MSM) 從每個實例中選擇選擇最合适的 mask 分辨率。提出的 DynaMask 效果很好。
二、引言
實例分割 Instance segmentation (IS) 的目的,進展。目前的方法大緻分爲雙階段的和單階段的。雙階段精度高但是成本也高。
聊一下雙階段的方法,即先檢測後分割。先對于所有的 proposal,例如 28 × 28 28\times28 28×28 來預測一個統一分辨率的二值網格 mask,然而上采樣到原始尺寸。接下來舉出 Mask R-CNN 的例子,指出缺點:低分辨率的 mask 很難捕捉細節的信息,導緻預測結果不滿意,特别是對于過大的目标邊界,而大的 mask 會使得計算量成本上升。

如上圖所示,難樣本 “人” 需要更細粒度的 mask 來預測。而像簡單的、規則的、少信息的目标,例如 “frisbee” 則隻需粗糙的 mask 就能預測。于是提出一種針對每個實例來自适應地調整 mask 分辨率的策略。具體來說,分配給難樣本以高分辨率的 mask,而對簡單的樣本賦予低分辨的 mask。于是對于簡單樣本的計算量可以減少,而對難樣本的精度可以提高。但不能直接通過 Mask R-CNN 來預測高分辨率的 mask,這會降低 mask AP。原因:從高層金字塔層提取的大尺寸目标的 RoI 特征,由于下采樣使得 mask 特别粗糙,因此簡單地增加 RoI 的 mask 尺寸不會帶來有用的信息;其次 Mask R-CNN 的 mask 頭過于簡單,因此随着網格尺寸的增加很難做出精确的預測。
于是提出一種雙層 FPN 框架來逐漸地擴大 mask 網格。具體來說,在圖像水平的 FPN 層(i-FPN)之外增加一個區域水平的 FPN(r-FPN),其中構建一個從 i-FPN 到 r-FPN 不同金字塔層的信息流動。在這一雙水平的 FPN 中,提出一種數據獨立的 Switch Module (MSM) 來自适應地選擇每個實例的mask。提出的網絡模型名爲 DynaMask,在主流數據集上評估效果很好。
主要貢獻如下:
- 提出 DynaMask 來自适應地賦值給不同的實例以合适的 mask:賦值低分辨率給簡單樣本,而賦值高分辨率給難樣本;
- 提出一種雙端 FPN 框架用于 IS,構建從 i-FPN 到 r-FPN 多層的信息流動,用于促進信息互補和聚合;
- 實驗結果表明 DynaMask 性能和效率很好。
三、相關工作
實例分割
目前大多數方法沿着 Mask R-CNN 的套路,接下來對 Mask Scoring R-CNN、BMask RCNN、DCT-Mask、PANet 進行簡單介紹。一些工作提出通過粗糙-細膩化的精煉來提升 mask 的質量,例如 HTC、PointRend、RefineMask,缺點是增加推理時間和内存負擔。本文提出動态地爲每個實例選擇合适的 mask,使得簡單樣本被賦值小的 mask(更少的精煉階段),更難的樣本被賦值大的 mask(更多的精煉階段)。
動态網絡
動态網絡方法要麽扔掉一些 blocks 或者修剪通道數,例如 SkipNet、DRNet 等。而在不同的分辨率采用動态 mask 來分割不同的實例還未被探索過。傳統方法先預測一個固定尺寸的 mask,這一措施對簡單樣本很管用,但過于簡化難樣本的細粒度水平細節。根據分割難易,本文設計一種動态 mask 選擇框架來自适應地給不同的目标分配合适尺寸的 mask。
四、動态 Mask 選擇
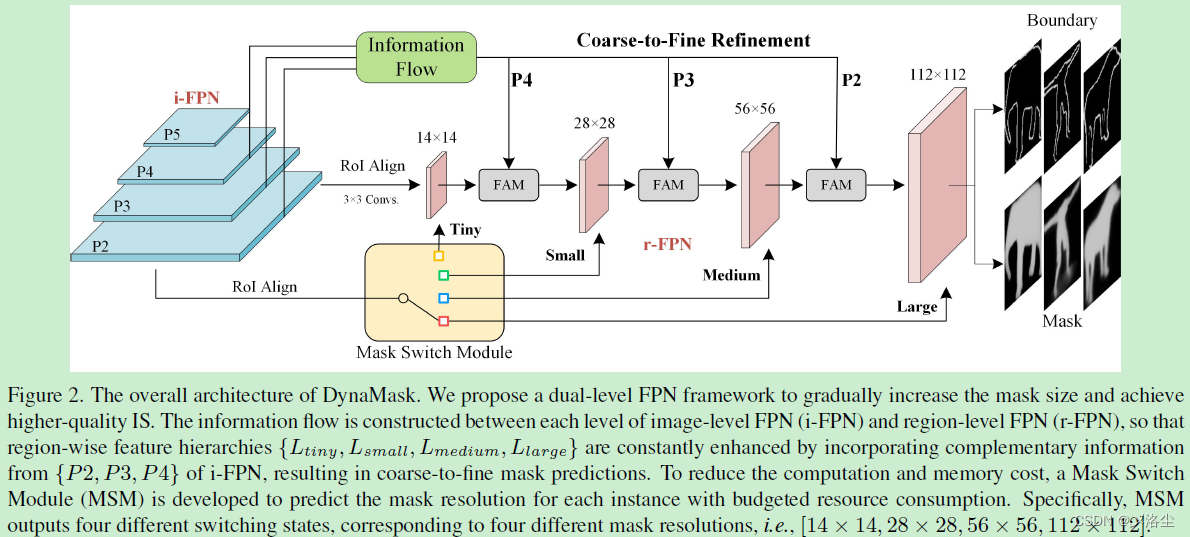
4.1 雙層 FPN
原始圖像層 FPN (i-FPN) 引入自上而下的路徑,将高層的上下文的語義信息投影到低層中。本文提出一個區域水平的 r-FPN,将 i-FPN 中的低層整合更多的信息到區域特征層級上。從 i-FPN 到 r-FPN 的信息流動上圖所示。
區域水平的 FPN
依據原始的 i-FPN { P 2 , P 3 , P 4 , P 5 } \{P_2,P_3,P_4,P_5\} {P2,P3,P4,P5} 來定義層的概念,從而産生對應于原始特征圖相同分辨率的層。r-FPN 起始于 RoI-Aligned 的區域特征,通過逐漸地融合 { P 2 , P 3 , P 4 } \{P_2,P_3,P_4\} {P2,P3,P4} 的互補信息來增強,得到一組自上而下的基于區域的特征層次,表示爲 { L t i n y , L s m a l l , L m e d i u m , L l a r g e } \{L_{tiny},L_{small},L_{medium},L_{large}\} {Ltiny,Lsmall,Lmedium,Llarge}。從 L t i n y L_{tiny} Ltiny 到 L l a r g e L_{large} Llarge,空間分辨率通過逐步地擴大兩個尺寸因子來增加。本文設計一個特征聚合模塊 Feature Aggregation Module (FAM) 來整合 r-FPN 的特征 L r L_r Lr 和 i-FPN 特征 P i P_i Pi。
特征聚合模塊 FAM
由于上采樣和 RoI 池化操作,使得現有的 L r L_r Lr 和 P i P_i Pi 之間存在空間誤對齊,這會降低對于邊界區域的分割性能。本文提出 FAM 來自适應地聚合多尺度的特征,如下圖所示:

FAM 包含兩個不同的可變形卷積:第一個 D e f o r m C o n v 1 Deform Conv1 DeformConv1 動态調整 L r L_r Lr 的位置,使其能更好地對齊 P i P_i Pi。之後拼接 L r L_r Lr 和 P i P_i Pi,然後通過一個 3 × 3 3\times3 3×3 卷積得到 offset 圖,記爲 Δ o \Delta_o Δo。最後,利用 Δ o \Delta_o Δo 将 L r L_r Lr 對齊到 P i P_i Pi,第二個 D e f o r m C o n v 2 Deform Conv2 DeformConv2 類似一個注意力機制,能夠關注目标上的顯著部分。提出的 FAM 可以插入到不同的 r-FPN 階段上從而提升 mask 的預測。
4.2 Mask Switch Module (MSM)
不同的實例需要不同的 mask 網格來實現準确的分割,遂提出一種自适應地根據不同實例來調整 mask 網格的分辨率。确切來說,一個 MSM 用來在預算計算的假設下執行 mask 分辨率預測,從而在性能和分割準确度之間權衡。
最優的 Mask 賦值
MSM 實際上是一個輕量化的分類器,記爲 f M S M ( ⋅ ) f_{\text MSM}(\cdot) fMSM(⋅),如下圖所示:
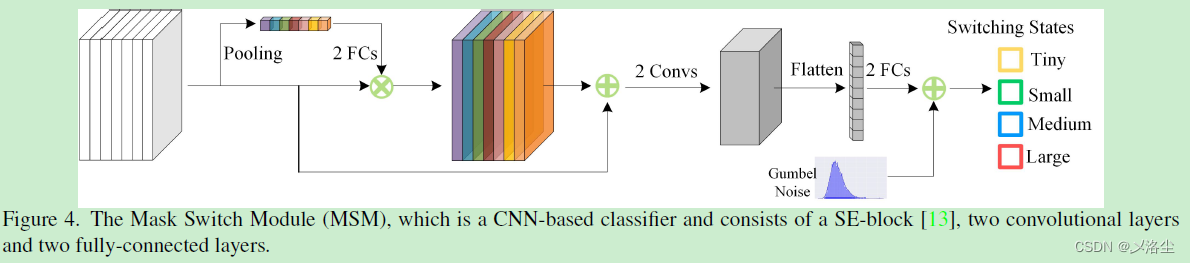
MSM 包含一個逐通道注意力模塊,後面跟着一些卷積層和全連接層。分類器旨在從一堆 K K K 個候選,如 [ r 1 , r 1 , ⋯ , r k ] [r^1,r^1,\cdots,r^k] [r1,r1,⋯,rk] 中找到最優的 mask 分辨率。具體來說,MSM 将裁剪後的逐區域 RoI 特征作爲輸入,通過 softmax 輸出一組概率向量 P = [ p 1 , p 1 , ⋯ , p k ] P=[p^1,p^1,\cdots,p^k] P=[p1,p1,⋯,pk]。向量中每個元素表示相應的被選擇到的候選分辨率概率:
p k = exp ( f M S M k ( x ) ) ∑ k ′ exp ( f M S M k ( x ) ) , k ∈ { 1 , ⋯ , K } p^k=\dfrac{\exp(f_{MSM}^k(x))}{\sum_{k'}\exp(f_{MSM}^k(x))},\quad k\in\{1,\cdots,K\} pk=∑k′exp(fMSMk(x))exp(fMSMk(x)),k∈{1,⋯,K}
其中 x x x 爲輸入到 MSM 的 RoI 特征,最大的候選分辨率概率從中選出作爲 switching state,從而決定目标的分割 mask 分辨率。
采用 Gumbel-Softmax 的重參數化
将 MSM 的軟輸出 P P P 轉化爲獨熱預測 Y = [ y 1 , y 1 , ⋯ , y k ] Y= [y^1,y^1,\cdots,y^k] Y=[y1,y1,⋯,yk], y k ∈ { 0 , 1 } y^k\in\{0,1\} yk∈{0,1},這一過程可以用分離采樣來表示,然而不能微分,因此不支持端到端訓練。
爲了使得 MSM 的梯度得以更新,引入一種重參數化方法,Gumbel-Softmax。給定一個類别分布概率 P = [ p 1 , p 1 , ⋯ , p k ] P=[p^1,p^1,\cdots,p^k] P=[p1,p1,⋯,pk],通過規則: y = one_hot ( a r g m a x k ( l o g p k + g k ) ) y=\text{one\_hot}\left(argmax_k\left(logp^k+g^k\right)\right) y=one_hot(argmaxk(logpk+gk))
其中 { g k } i = k K \{g^k\}^K_{i=k} {gk}i=kK 爲 G u m b e l ( 0 ; 1 ) Gumbel(0; 1) Gumbel(0;1) 分布的樣本,定義爲:
g = − l o g ( − l o g ( u ) ) , u ∼ U n i f o r m ( 0 , 1 ) g=-log\left(-log\left(u\right)\right),u\sim Uniform\left(0,1\right) g=−log(−log(u)),u∼Uniform(0,1)
之後采用 Gumbel-Softmax 函數作爲一個連續的、可微分的原始 softmax \text{softmax} softmax 函數的近似:
y k = exp ( ( l o g p k + g k ) / τ ) ∑ k ′ exp ( ( l o g p k ′ + g k ′ ) / τ ) y^k=\dfrac{\exp\left((log p^k+g^k)/\tau\right)}{\sum_{k'}\exp\left((log p^{k'}+g^{k'})/\tau\right)} yk=∑k′exp((logpk′+gk′)/τ)exp((logpk+gk)/τ)其中 τ \tau τ 表示溫度參數,當 τ \tau τ 接近 0 0 0 時,Gumbel-softmax 接近于獨熱狀态。
4.3 目标函數
Mask 損失
給定正的樣本實例 x i x_i xi,首先通過 MSM 來預測 mask 的 switching state: Y = [ y 1 , y 2 , ⋯ , y k ] Y= [y^1,y^2,\cdots,y^k] Y=[y1,y2,⋯,yk],并将其穿過 r-FPN 的不同階段來獲得 K K K 個不同分辨率 { m ^ i 1 , ⋯ , m ^ i K } \{\hat{m}_i^1,\cdots,\hat{m}_i^K\} {m^i1,⋯,m^iK} 下的 mask 預測圖,定義損失函數如下:
L m a s k = ∑ i = 1 N ∑ k = 1 K y k ℓ ( m ^ i k , m i ) \mathcal{L}_{mask}=\sum_{i=1}^N\sum_{k=1}^K y^k\ell(\hat{m}_i^k,m_i) Lmask=i=1∑Nk=1∑Kykℓ(m^ik,mi)其中 m ^ i K \hat{m}_i^K m^iK 表示 x i x_i xi 的第 k k k 個 mask 預測, m i {m}_i mi 表示相應的 GT mask 網格。 y k y^k yk 爲是否第 k k k 個 mask 分辨率被選擇作爲輸出分辨率的索引。 l l l 爲 cross-entropy 損失。
邊緣損失
Mask 損失中,假設 mask 産生非常小的損失應該有着很高的質量。因此通過最小化 mask 損失可以得到準确的 mask,然而實驗結果表明 mask 損失在不同的 mask 上非常接近,很難區分 mask 質量。相比之下,由不同分辨率産生的 mask 在邊緣損失上變化巨大,這能很好的揭示 mask 質量。

對于 MSM 的輸出 Y = [ y 1 , y 2 , ⋯ , y k ] Y= [y^1,y^2,\cdots,y^k] Y=[y1,y2,⋯,yk] 及不同分辨率的邊緣圖 { e ^ i 1 , ⋯ , e ^ i K } \{\hat{e}_i^1,\cdots,\hat{e}_i^K\} {e^i1,⋯,e^iK},邊緣損失定義如下:
L e d g e = ∑ i = 1 N ∑ k = 1 K y k ℓ ( e ^ i k , e i ) \mathcal{L}_{edge}=\sum_{i=1}^N\sum_{k=1}^K y^k\ell(\hat{e}_i^k,e_i) Ledge=i=1∑Nk=1∑Kykℓ(e^ik,ei)其中 e i e_i ei 爲 GT 邊緣。
首先應用拉普拉斯算子在 GT mask 上獲得一個軟邊緣圖 m i m_i mi,然後通過阈值将其轉化爲二值化邊緣圖。上圖所示的邊緣損失能夠更好地揭示 mask 質量,即高分辨率的 mask 參數更接近于 GT 的邊緣(小損失),而低分辨率的 mask 與 GT 有着更大的差異(大損失)。
預算限制
通過優化邊緣損失,模型傾向于收斂到次優的結果:所有的實例都采用最大的 mask 來分割,即 112 × 112 112\times112 112×112,這整合了更多的細節信息且擁有最小的預測損失。而實際上,并不是所有的樣本都需要最大的 mask,對于簡單樣本能夠節省冗餘的計算量。爲了降本增效,提出帶有預算限制的 MSM。令 C \mathcal{C} C 表示對應于選擇的 mask 分辨率損失,當前 batch 數據所産生的期望 FLOPs 記爲 E ( C ) \mathbb{E}(\mathcal{C}) E(C),而超出目标 FLOPs 的部分記爲 C t \mathcal{C}_t Ct,預算限制定義爲:
L b u d g e t = max ( E ( C ) C t − 1 , 0 ) \mathcal{L}_{budget}=\max(\dfrac{\mathbb{E}(\mathcal{C})}{\mathcal{C}_t}-1,0) Lbudget=max(CtE(C)−1,0)
進一步引入信息 entropy 損失來平衡 MSM 的分辨率預測。給定一組輸出概率向量 P 1 , P 2 , ⋯ , P N P_1,P_2,\cdots,P_N P1,P2,⋯,PN,其中 N N N 爲當前 batch 内的實例數量,第 k k k 個分辨率的頻率計算爲: f k = 1 N ∑ i p i k f^k=\frac{1}{N}\sum_i p_i^k fk=N1∑ipik。
信息 entropy 損失定義如下:
L e n t r o p y = 1 K ∑ k f k l o g f k \mathcal{L}_{entropy}=\dfrac{1}{K}\sum_k f^klog f^k Lentropy=K1k∑fklogfk上面的 entropy 損失将每個元素 f k f^k fk 推向 1 K \frac{1}{K} K1,以使 MSM 能夠從相似概率中選擇不同的分辨率。
最後,mask 分支的總體目标函數:
L t o t a l = L m a s k + λ 1 L e d g e + λ 2 L r e g \mathcal L_{total}=\mathcal L_{mask}+\lambda_1\mathcal L_{edge}+\lambda_2\mathcal L_{reg} Ltotal=Lmask+λ1Ledge+λ2Lreg其中 λ 1 \lambda_1 λ1、 λ 2 \lambda_2 λ2 爲平衡超參數, L r e g \mathcal L_{reg} Lreg 表示結合了預算限制的正則項,即 L r e g = L b u d g e + L e n t r o p y \mathcal L_{reg}=\mathcal L_{budge}+\mathcal L_{entropy} Lreg=Lbudge+Lentropy。
五、實驗
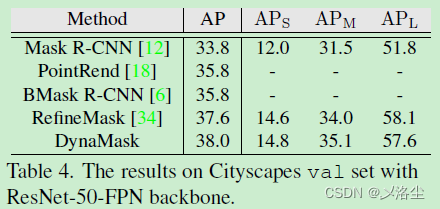
數據集:COCO、Cityscapes,評估指标:标準的 mask AP。
5.1 實施細節
Backbone:Mask R-CNN,預訓練在 ImageNet 上。部署在 MMDetection 上。MSM 有四個 switching states,對應于四組分辨率 [ 14 × 14 , 28 × 28 , 56 × 56 , 112 × 112 ] [14\times14,28\times28,56\times56,112\times112] [14×14,28×28,56×56,112×112], λ 1 = 0.1 \lambda_1=0.1 λ1=0.1。首先使用 mask 損失在所有分辨率下訓練沒有 MSM 的網絡一個 epoch。初始學習率 0.02 0.02 0.02,batch_size 16,8 GPUs,之後訓練所有模塊 12 個 epochs,SGD,相同的初始學習率及 batch_size,在第 8 和 11 個 epochs 時分别 × 0.1 \times0.1 ×0.1,多尺度訓練策略,短邊随機從 [ 640 , 800 ] [640,800] [640,800] 中采樣,而在推理時,短邊調整至 800。消融實驗中采用 1 × 1\times 1× 訓練計劃,數據增強采用 MMDetection 定義的方式。
5.2 主要結果
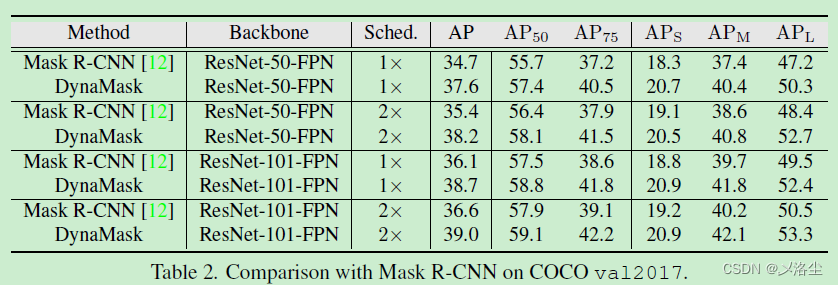
與 Mask R-CNN 的比較
與 SOTA 的方法比較
分割結果的可視化

5.3 消融實驗
Mask 分辨率預測

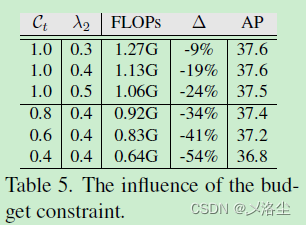
預算限制的影響
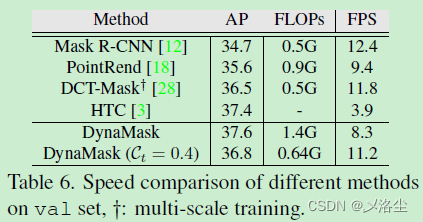
不同方法的速度比較
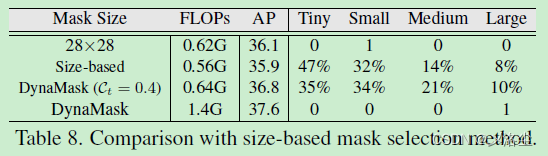
Mask 尺寸的影響
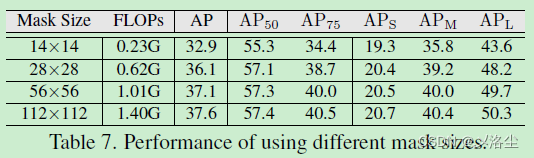
基于尺寸的 Mask 選擇方法
基于尺寸的方法表示根據目标尺寸來賦值 mask,具體來說,采用下列規則賦值給寬 w w w、高 h h h 的實例一個 mask:
k = ⌊ k 0 + l o g 2 ( w h / w 0 h 0 ) ⌋ k=\left\lfloor k_0+log_2(\sqrt{wh}/\sqrt{w_0h_0})\right\rfloor k=⌊k0+log2(wh /w0h0 )⌋其中 w 0 w_0 w0、 h 0 h_0 h0 分别表示輸入圖像的寬、高。 k 0 k_0 k0 表示最大的 mask 分辨率,例如 k 0 = 4 k_0=4 k0=4。這一式子意味着更大的目标将會賦值更大分辨率的 mask。實驗結果如下表所示:
六、結論
設計了一種雙層 FPN 結構來充分利用金字塔的多層中互補的上下文細節信息。具體來說,除一般的圖像水平金字塔 i-FPN 外,利用一組區域水平的自上而下的路徑來逐漸擴大 mask 的尺寸并整合更多的 i-FPN 細節。此外,引入了 Mask Switch Module (MSM) 來自适應地爲每個 proposal 選擇合适的 mask,從而減小簡單樣本的冗餘計算量。大量的實驗表明本文提出的方法很有用。
七、補充材料
7.1 關于 Mask 分辨率預測的分析
mask 分辨率和類别之間的關聯
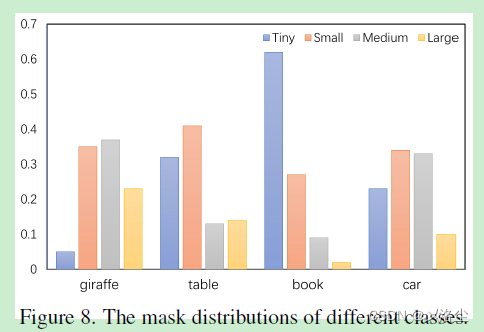
Mask 選擇的結果

7.2 預測的 Mask 分辨率分布
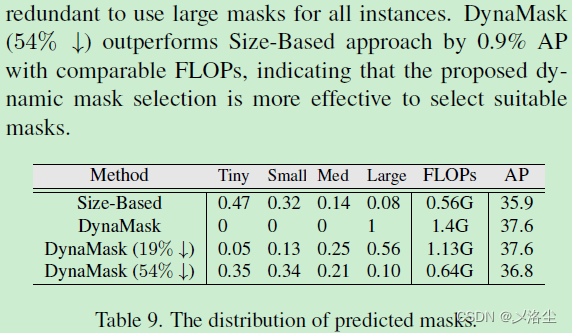
7.3 在 LVIS 數據集上的結果
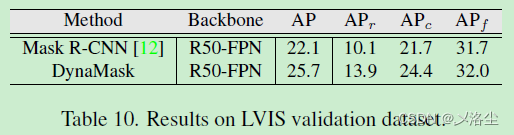
7.4 與其他 FPN 變體的比較
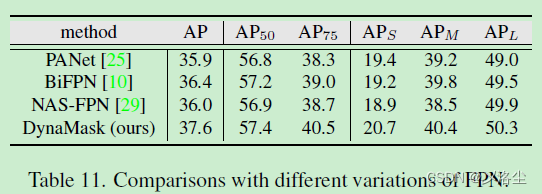
7.5 定性結果



寫在後面
本文框架以及寫作手法都值得借鑒,在當今 Mask R-CNN 都快被挖的啥都沒有的情況下,還能有如此創新性想法的文章屬實難得一見了。
愉快的周末就要過去啦,下一周繼續加油哇~







