

目录
- 一、写在前面:
- 二、系统准备:
- 三、系统构建
- 四、总结反思:
- 五、完整代码:
Author:qyan.li
Date:2022.6.3
Topic:借助于python构建知识图谱的电影知识智能问答系统
Reference:(13条消息) Python创建知识图谱_趋吉避凶的博客-CSDN博客_python知识图谱构建
一、写在前面:
~~~~~~~~ 最近,课程设计要求做关于知识图谱的调研工作。调研过程中,在网络上发现诸多同学自行构建知识图谱的相关内容,就考虑自己自行搭建一个。经过调研和基于自己技术的考量,最终还是打算做基于知识图谱的电影知识智能问答系统(主要是数据集比较好构建)。虽然比较简单,但是这个过程中自己也收获不少新知识,对于整个系统框架的了解也更加深入。
二、系统准备:
~~~~~~~~ 在智能问答系统构建之前,需要做部分准备工作,主要包含两个方面:
-
Neo4j软件安装:
~~~~~~~~ 知识图谱在构建和使用的过程中,需要借助于Neo4j图数据库进行可视化的管理与操作,因此实现必须配置好,Neo4j配置过程网络教程很多,但博主依旧配置的比较艰辛,下面简单列举几点博主遇到的问题以及相应的解决办法:
-
在没有改变JDK版本的情况下,安装任何版本的Neo4j都无法运行:
-
报错的关键在于JDK版本与Neo4j不相匹配,需要更改JDK版本:
参考文献:(6条消息) 【neo4j 安装问题】You are using an unsupported version of the Java runtime._vxiao_shen_longv的博客-CSDN博客
-
安装JDK8版本:
参考文献:(6条消息) JDK8.0安装及配置_我想rua熊猫的博客-CSDN博客_jdk8.0
小Tips:
认真按照教程配置环境变量,不要遗落或改变任何一个变量的配置
-
-
电影知识数据库构建:
~~~~~~~~ 电影知识数据库的构建,本质上还是网络爬虫技术的应用,被爬的对象还是我们老熟人:豆瓣250(感觉都快被大家爬烂啦!!!)。爬取的对象为电影的名称,同时带有该电影下主演,导演,上映时间,一句话评价,地区,类型,评价人数,评分八个标签内容,并存取至对应的csv文件中进行保存。
电影数据集文件部分数据展示:

~~~~~~~~ 爬虫的代码此处不做讲解,完整的代码会放置在最后,数据集文件movieInfo.csv也会放置在其中,大家可自行下载使用。
三、系统构建
~~~~~~~~ 软件配置成功,数据集构建完成,接下来就可以进入最激动人心的环节:知识图谱的系统构建。知识图谱构建核心是利用python中的py2neo模块,它可以连接neo4j数据库,借助于python语言完成对neo4j的各种操作。后续的知识图谱的构建和内容的检索均依赖此模块完成。
~~~~~~~~ 先放一下此部分的完成代码,方便后续进行讲解:
## 相关模块导入 import pandas as pd from py2neo import Graph,Node,Relationship ## 连接图形库,配置neo4j graph = Graph("http://localhost:7474//browser/",auth = ('*****','********')) # 清空全部数据 graph.delete_all() # 开启一个新的事务 graph.begin() ## csv源数据读取 storageData = pd.read_csv('./movieInfo.csv',encoding = 'utf-8') # 获取所有列标签 columnLst = storageData.columns.tolist() # 获取数据数量 num = len(storageData['title']) # KnowledgeGraph知识图谱构建(以电影为主体构建的知识图谱) for i in range(num): if storageData['title'][i] == '黑客帝国2:重装上阵' or storageData['title'][i] == '黑客帝国3:矩阵革命': continue # 为每部电影构建属性字典 dict = {} for column in columnLst: dict[column] = storageData[column][i] # print(dict) node1 = Node('movie',name = storageData['title'][i],**dict) graph.merge(node1,'movie','name') ## 上述代码已经成功构建所有电影的主节点,下面构建所有的分结点以及他们之间的联系 # 去除所有的title结点 dict.pop('title') ## 分界点以及关系 for key,value in dict.items(): ## 建立分结点 node2 = Node(key,name = value) graph.merge(node2,key,'name') ## 创建关系 rel = Relationship(node1,key,node2) graph.merge(rel)
针对于代码中几个重要的点进行说明:
-
借助于py2neo连接数据库,graph = Graph("http://localhost:7474//browser/",auth = ('*****','********')),实际调用过程中将*号换做你的用户名和密码。
此处新旧版本调用的方式有所不同,参考文献:https://blog.csdn.net/u010785550/article/details/116856031
-
之所以删除黑客帝国2和黑客帝国3是由于二者所属的八个标签中存在未知字符,构建neo4j结点时会报错,因此直接在数据读取阶段剔除。
~~~~~~~~ 下面对知识图谱构建中核心部分的代码进行解释说明:由于自己也是初步接触,代码或者讲解存在问题,还请大家批评指正。
~~~~~~~~ 知识图谱的构建中两个最重要的板块:结点的构建和结点关系的连接,因此,代码的主体也主要是围绕这两个方向进行,分别利用Node类和Relationship类以及merge函数实现结点创建以及结点间关系的连接。
-
node1 = Node('movie',name = storageData['title'][i],**dict)此代码用于构建以单个结点,node1结点属于movie这种类别,name名称设置为爬取到的电影名称,后面的dict作为结点的附加树形(此处即为每部电影下的八个标签)
graph.merge(node1,'movie','name')用于将创建的结点插入至知识图谱中,movie为类别
-
node2 = Node(key,name = value)用于为每部电影下的八个属性均创建结点,类别即为类别的column,如time,atcor,director等等,name即为每个标签下的具体内容,此处同样需要借助于merge函数将子节点插入至知识图谱中
-
rel = Relationship(node1,key,node2)借助于Relationship类实现结点间关系的连接,调用形式为Relationship(node1,relationship,node2)建立node1指向node2的relationship关系,此处即建立电影结点指向八个标签的关系,关系即为column内容
~~~~~~~~ OK,代码中的主体内容已经构建完成,运行代码,在neo4j的浏览器中即可以看到构建好的知识图谱,如下图:
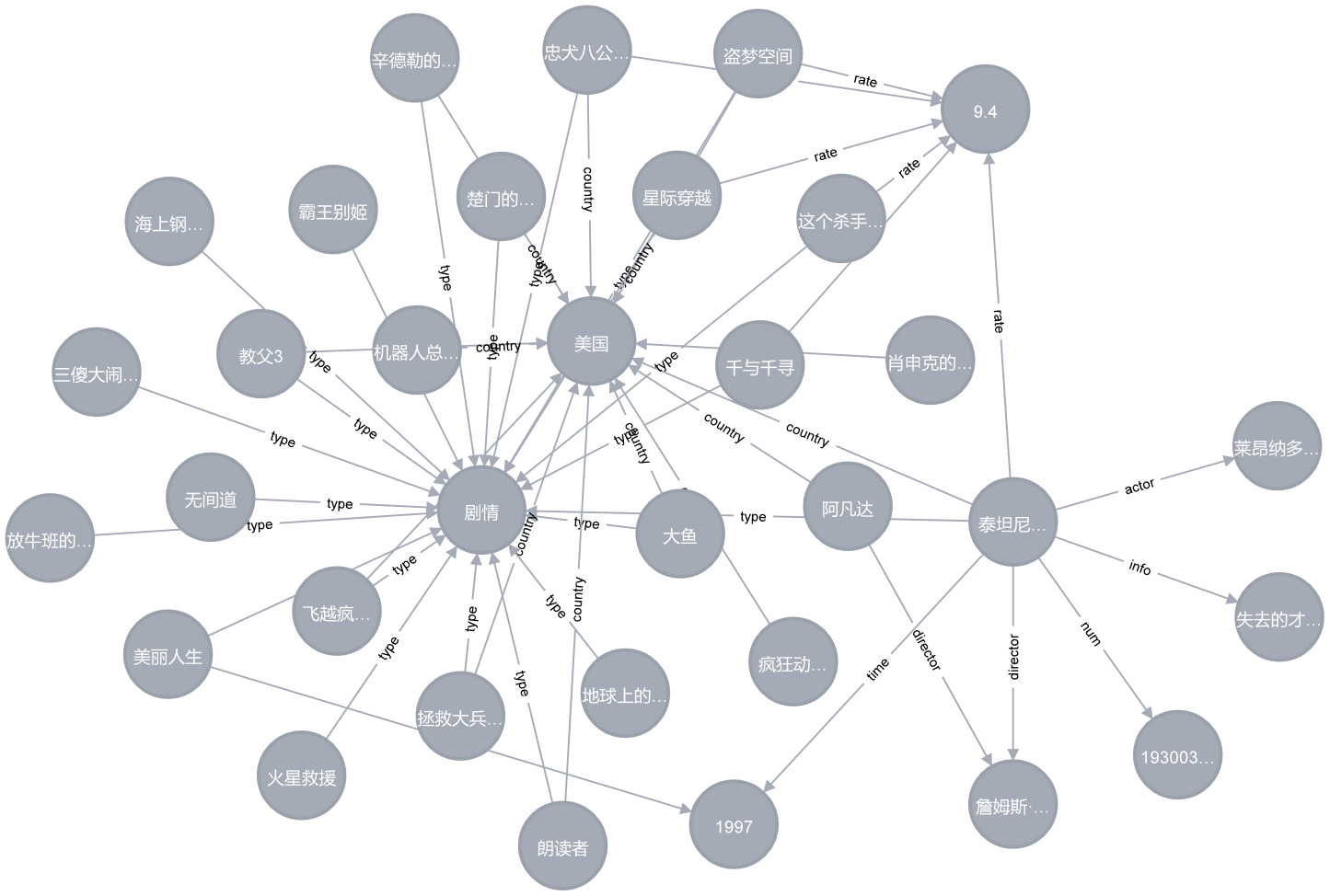
~~~~~~~~ 这里算是一条分界线,因为上面代码主要阐述如何借助于py2neo构建电影知识图谱,下面主要讲解如何借助于此知识图谱完成电影内容的检索。
~~~~~~~~ 老样子,还是先粘贴代码,方便大家参考借鉴:
# 相关模块导入 import jieba.posseg as pseg import jieba from fuzzywuzzy import fuzz from py2neo import Graph ## 建立neo4j对象,便于后续执行cyphere语句 graph = Graph("http://localhost:7474//browser/",auth = ('neo4j','999272@123xy')) ## 用户意图的判断 #设计八类问题的匹配模板 info = ['这部电影主要讲的是什么?','这部电影的主要内容是什么?','这部电影主要说的什么问题?','这部电影主要讲述的什么内容?'] director = ['这部电影的导演是谁?','这部电影是谁拍的?'] actor = ['这部电影是谁主演的?','这部电影的主演都有谁?','这部电影的主演是谁?','这部电影的主角是谁?'] time = ['这部电影是什么时候播出的?','这部电影是什么时候上映的?'] country = ['这部电影是那个国家的?','这部电影是哪个地区的?'] type = ['这部电影的类型是什么?','这是什么类型的电影'] rate = ['这部电影的评分是多少?','这部电影的评分怎么样?','这部电影的得分是多少分?'] num = ['这部电影的评价人数是多少?','这部有多少人评价过?'] # 设计八类问题的回答模板 infoResponse = '{}这部电影主要讲述{}' directorResponse = '{}这部电影的导演为{}' actorResponse = '{}这部电影的主演为{}' timeResponse = '{}这部电影的上映时间为{}' countryResponse = '{}这部电影是{}的' typeResponse = '{}这部电影的类型是{}' rateResponse = '{}这部电影的评分为{}' numResponse = '{}这部电影评价的人数为{}人' # 用户意图模板字典 stencil = {'info':info,'director':director,'actor':actor,'time':time,'country':country,'type':type,'rate':rate,'num':num} # 图谱回答模板字典 responseDict = {'infoResponse':infoResponse,'directorResponse':directorResponse,'actorResponse':actorResponse,'timeResponse':timeResponse,'countryResponse':countryResponse,'typeResponse':typeResponse,'rateResponse':rateResponse,'numResponse':numResponse} # 由模板匹配程度猜测用户意图 ## 模糊匹配参考文献:https://blog.csdn.net/Lynqwest/article/details/109806055 def AssignIntension(text): ''' :param text: 用户输入的待匹配文本 :return: dict:各种意图的匹配值 ''' stencilDegree = {} for key,value in stencil.items(): score = 0 for item in value: degree = fuzz.partial_ratio(text,item) score += degree stencilDegree[key] = score/len(value) return stencilDegree ## 问句实体的提取 ## 结巴分词参考文献:https://blog.csdn.net/smilejiasmile/article/details/80958010 def getMovieName(text): ''' :param text:用户输入内容 :return: 输入内容中的电影名称 ''' movieName = '' jieba.load_userdict('./selfDefiningTxt.txt') words =pseg.cut(text) for w in words: ## 提取对话中的电影名称 if w.flag == 'lqy': movieName = w.word return movieName ## cyphere语句生成,知识图谱查询,返回问句结果 ## py2neo执行cyphere参考文献:https://blog.csdn.net/qq_38486203/article/details/79826028 def SearchGraph(movieName,stencilDcit = {}): ''' :param movieName:待查询的电影名称 :param stencilDcit: 用户意图匹配程度字典 :return: 用户意图分类,知识图谱查询结果 ''' classification = [k for k,v in stencilDcit.items() if v == max(stencilDcit.values())][0] ## python中执行cyphere语句实现查询操作 cyphere = 'match (n:movie) where n.title = "' + str(movieName) + '" return n.' + str(classification) object = graph.run(cyphere) for item in object: result = item return classification,result ## 根据问题模板回答问题 def respondQuery(movieName,classification,item): ''' :param movieName: 电影名称 :param classification: 用户意图类别 :param item:知识图谱查询结果 :return:none ''' query = classification + 'Response' response = [v for k,v in responseDict.items() if k == query][0] print(response.format(movieName,item)) def main(): queryText = '肖申克的救赎这部电影的导演是谁?' movieName = getMovieName(queryText) dict = AssignIntension(queryText) classification,result = SearchGraph(movieName,dict) respondQuery(movieName,classification,result) if __name__ == '__main__': main() ~~~~~~~~ 首先针对上述系统进行说明:该项目中构建的电影知识智能问答系统仅能回答八个方面的问题,分别对应电影结点构建时每个电影下所对应的8个标签,分别为actor(主演),director(导演),time(上映时间),country(上映国家),type(电影类型),num(评价人数),rate(电影评分),content(一句话评价)。
问答系统构建的整体思路:
-
将用户输入与预设问题模板匹配,判断用户询问问题类别(属于上述八种中的哪一种)
-
对用户输入内容进行理解,提取语句的实体内容(本例中为提取电影的name)
-
结合问题类别和电影名称构建cyphere查询语句,调用知识图谱返回查询的结果
-
将返回的查询结果匹配至相应的回复语句,输出完成电影知识问答的整个过程
下面针对于智能问题系统的四个步骤分别进行讲解,说明实现的步骤以及主要代码:
- 用户意图匹配:
~~~~~~~~ 本部分思想较为简单,主要借助于python的模糊匹配库,将用户输入的语句和事先构建的类别列表中的每句话进行匹配,获得匹配值后计算平均值,并存入字典中,最终取出字典中匹配程度最高的类别即为用户意图。
AssignIntension()函数即事先对应的功能,接收用户输入,返回匹配列表
- 内容实体提取:
~~~~~~~~ 内容实体提取的在本项目中主要负责提取用户问题中的电影名称,这是我们后续处理的关键与核心。
~~~~~~~~ 电影名称包含在用户输入中,所以提取电影名称首先想到的便是借助于中文分词实现语句分别,然后将电影名称的字段提取出即可,但由于电影名称的多样性和复杂性,结巴分词可能会将电影名称分开,同时也不方便确认哪个字段属于电影名称。
~~~~~~~~ 因此,简单的分词无法完成上述任务,我们需要借助于结巴分词的自定义词典功能。结巴分词支持自定义词典导入,在分词时,你自定义的这些词汇就会被认作一个词语进行保留,而不会出现上述电影名称被分开的情况。自定义词典以及构建的函数也会放在结尾的文件夹中,大家可自行参考借鉴。
代码jieba.load_userdict('./selfDefiningTxt.txt')完成自定义词典的导入。
~~~~~~~~ OK,电影名称被成功保留,但是我们如何确认哪个字段是电影名称呢?结巴分词提供词性标注,自定义词典同样支持,我们仅需在电影名称后添加特殊字段作为电影名称词语的词性(本例中使用lqy,自己姓名的缩写),在分离时提取词性为lqy的词语即可以获得电影名称。
if w.flag == 'lqy': movieName = w.word~~~~~~~~ 分词后的每一个词语都具有word和flag两个属性,分别存储词语内容和词性
参考文献:(6条消息) jieba结巴分词加入自定义词典_Am最温柔的博客-CSDN博客_jieba自定义词典
3.cyphere语句查询:
~~~~~~~~ 按照自己的理解,neo4j与mysql类似,都有自己官方的查询语言,cyphere就是neo4j的官方查询语言,cyphere作为一门单独的语言,如果需要复杂的应用,是需要花费精力单独进行查询,此处不会对cyphere的语法进行详细的讲解,需要的同学可以移步其他博文进行语法的学习,此处仅应用cyphere中最简单的查询语句:
# 查询肖申克的救赎的上映时间 match (n:movie) where n.title = '肖申克的救赎' return n.time
~~~~~~~~ 因此,借助于上文获取的电影名称和用户意图类别即可以构建cyphere语句输入至知识图谱中进行查询,返回目标结果。
cyphere = 'match (n:movie) where n.title = "' + str(movieName) + '" return n.' + str(classification)
~~~~~~~~ 上述代码即完成cyphere语句构建的任务,而后借助于py2neo运行查询语句即可以获得目标返回的内容。
- 回复语句匹配:
~~~~~~~~ 在知识图谱中查询到目标的结果后,即可以将查询结果和电影名称代入回复模板中,
~~~~~~~~ 回复的模板共有八个,需要代入和用户意图相匹配的回复模板中,输出即可完成智能问答系统的问答功能。
-
四、总结反思:
~~~~~~~~ 本项目借助于python语言构建一个最简单的知识图谱的智能问答系统,麻雀虽小,但五脏俱全,通过此项目,我们可以基本了解构建知识图谱问答系统的基本过程,但项目存在的问题也比较多,改进的空间也比较大:
-
数据集的处理简单粗暴,例如黑客帝国等不符合要求,难以处理的数据直接剔除,这在完善的项目构建中是万万不可取的
-
由于cyphere语句语法的陌生,知识图谱的作用没有被高效的利用,细心的读者会发现项目中内哦内容的检索仅仅只利用Node下的属性字典中的8个属性,而并没有应用relationship,而relationship个人认为才是知识图谱最核心的竞争力,但是这需要更加高阶的cyphere句法,这也是未来改进和和提高的重点
五、完整代码:
~~~~~~~~ 考虑到部分同学github不流畅,故提供百度网盘链接,后续也会把github链接放上来:
链接:https://pan.baidu.com/s/1E9-BQUAlfi05dyDgNxK9bQ
提取码:dbo9
~~~~~~~~ Github链接:
https://github.com/booue/Movie-Knowledge-QS-system-using-KnowledgeGraph
~~~~~~~~ 终于写完啦!!!初次接触知识图谱,若有不当之处,欢迎批评指正。
-
-
-







