

一、OpenCL简介
OpenCL最初由苹果公司(Apple)提出(其他合作公司有AMD,IBM,Qualcomm(高通),Intel和NVIDIA),之后交由非盈利组织Khronos维护。最初的1.0版标准,由Khronos在2008年发布。OpenCL 1.0定义了主机端的接口,以及使用C语言作为OpenCL内核书写的语言,内核就是在不同的异构设备上并行处理数据的单位。之后的几年,发布了OpenCL 1.1和OpenCL 1.2,新标准为OpenCL增加了很多特性,比如:提高与OpenGL的互动性,补充了很多图像格式,同步事件,设备划分等特性。2013年11月,Khronos组织正式发布了OpenCL 2.0标准。为OpenCL添加了更多的新特性,比如:共享虚拟内存、内核嵌套并行和通用地址空间。这些更加高级的功能会让并行开发变得越来越简单,并且提高了OpenCL应用执行的效率。
开源编程标准设计者也要面对很多的挑战,为了形成一套通用的编程标准,要对一些要求进行一定的取舍。Khronos在这方面做得很不错,其设计的API都能很好的兼容不同的架构,并且能让硬件发挥其最大的性能。只要正确的遵循编程标准,那么一套程序几乎不用做什么修改,就可以从一个硬件平台,移植到另一个硬件平台上。供应商和设备分离的编程模型给OpenCL带来了极佳的可移植性,使其能充分发挥不同平台的加速能力。
执行在OpenCL设备上的代码,与执行在CPU上的不同,其使用OpenCL C进行书写。OpenCl C遵循更加严格的C99标准,在此基础上进行了适当的扩展,使其能在各种异构设备上以数据并行的方式执行。新标准中OpenCL C编程实现了C11标准中的原子操作(其子集)和同步操作。因为OpenCL API本身是C API,那么第三方就将其绑定到很多语言上,比如:Java,C++,Python和.NET。除此之外,很多主流库(线性代数和机器视觉)都集成了OpenCL,为的就是在异构平台上获得实质性的性能提升。
二、OpenCL 标准
OpenCL标准分为四部分,每一部分都用“模型”来定义。
平台模型:指定一个host处理器,用于任务的调度。以及一个或多个device处理器,用于执行OpenCL任务(OpenCL C Kernel)。这里将硬件抽象成了对应的设备(host或device)。
执行模型:定义了OpenCL在host上运行的环境应该如何配置,以及host如何指定设备执行某项工作。这里就包括host运行的环境,host-device交互的机制,以及配置内核时使用到的并发模型。并发模型定义了如何将算法分解成OpenCL工作项和工作组。
内核编程模型:定义了并发模型如何映射到实际物理硬件。
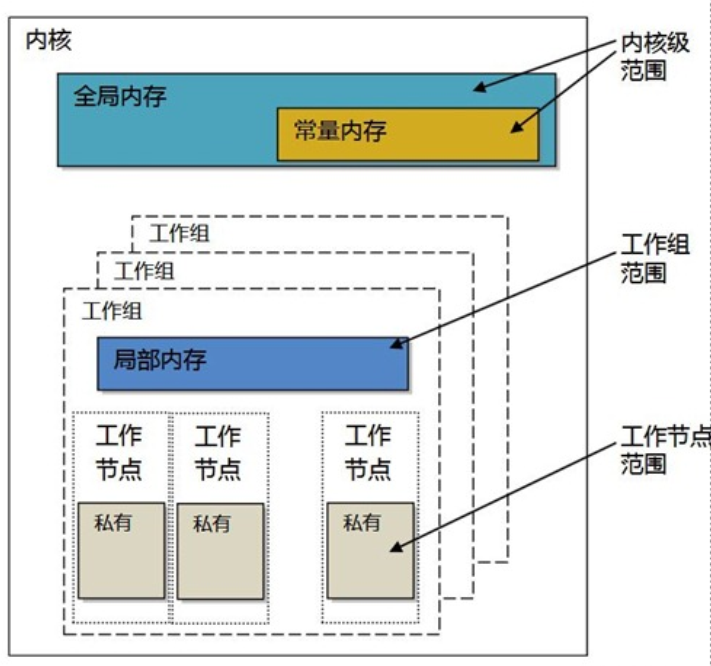
内存模型:定义了内存对象的类型,并且抽象了内存层次,这样内核就不用了解其使用内存的实际架构。其也包括内存排序的要求,并且选择性支持host和device的共享虚拟内存。
通常情况下,OpenCL实现的执行平台包括一个x86 CPU主处理器,和一个GPU设备作为***。主处理器会将内核放置在GPU上运行,并且发出指令让GPU按照某个特定的并行方式进行执行。内核使用到的内存数据都由编程者依据层级内存模型分配或开辟。运行时和驱动层会将抽象的内存区域映射到物理内存层面。最后,由GPU开辟硬件线程来对内核进行执行,并且将每个线程映射到对应的硬件单元上。
三、OpenCL基本概念
主机(Host):CPU及其内存组成的计算系统。
平台(Platform) : 主机和OpenCL管理框架下的若干个设备构成了一个平台,所有GPU操作都限定于选择的Platform上运行。OpenCL编程的第一步就是选择并初始化一个平台。
上下文(Context): 定义了整个OpenCL的运行环境,包括Kernel、Device、内存管理和指令队列等。
核函数(Kernel) : 是在设备程序上执行运算的入口函数,在主机上调用。
设备(Device) : GPU及其显存组成的计算系统。
指令队列(Command-Queue) : 一些需要在设备上执行的OpenCL指令的集合。
SIMT(Single Instruction Multi Thread) : 单指令多线程,GPU并行运算的主要方式,很多个多线程同时执行相同的运算指令,当然可能每个线程的数据有所不同,但执行的操作一致。
工作项(Work-item) : 跟CUDA中的线程(Threads)是同一个概念,N多个工作项(线程)执行同样的核函数,每个Work-item都有一个唯一固定的ID号,一般通过这个ID号来区分需要处理的数据。
工作组(Work-group) :跟CUDA中的线程块(Block)是同一个概念,N多个工作项组成一个工作组,Work-group内的这些Work-item之间可以通信和协作。
ND-Range : 跟CUDA中的网格是同一个概念,定义了Work-group的组织形式。
小结:
OpenCL的整个计算空间称为NDRange空间,它根据计算单元数量分为对应数量的work-group,而一个work-group在一个计算单元上执行,有多少个计算单元,就会有多少个work-group可以并行计算,同时每个work-group中又包含了多个work-item,其数量根据一个work-group可以同时运行多少个work-item决定。
四、基本用法
OpenCL在的编程上,通常是以最细粒度的并行,如对于图像来说,最细的粒度就是像素点,OpenCL可以对每一个像素点同时进行同一个核函数的处理。OpenCL的一般性体现在,接口的通用性和底层内核直接映射物理资源。
通过对比三个不同版本的向量加法例子来说明OpenCL的处理过程:
(1)串行C语言实现的版本
使用串行的方式实现向量加法(C语言),其使用一个循环对每个元素进行计算。每次循环将两个输入数组对应位置的数相加,然后存储在输出数组中。
void vecadd(int *C, int *A, int *B, int N){
for (int i = 0; i
(2)多线程C语言实现的版本
对于一个多核设备,我们要不就使用底层粗粒度线程API(比如,Win32或POSIX线程),要不就使用数据并行方式(比如,OpenMP)。粗粒度多线程需要对任务进行划分(循环次数)。因为循环的迭代次数特别多,并且每次迭代的任务量很少,这时我们就需要增大循环迭代的粒度,这种技术叫做“条带处理”。
void vecadd(int *C, int *A, int *B, int N, int NP, int tid){
int ept = N / NP; // 每个线程所要处理的元素个数
for (int i = tid * ept; i
(3)OpenCL C实现的版本
OpenCL C上的并发执行单元称为工作项(work-item)。每一个工作项都会执行内核函数体。这里就不用手动的去划分任务,这里将每一次循环操作映射到一个工作项中。OpenCL运行时可以创建很多工作项,其个数可以和输入输出数组的长度相对应,并且工作项在运行时,以一种默认合适的方式映射到底层硬件上(CPU或GPU核)。
概念上,这种方式与并行机制中原有的功能性“映射”操作(可参考mapReduce)和OpenMP中对for循环进行数据并行类似。当OpenCL设备开始执行内核,OpenCL C中提供的内置函数可以让工作项知道自己的编号。
下面的代码中,调用get_global_id(0)来获取当前工作项的位置,以及访问到的数据位于数组中的位置。get_global_id()的参数用于获取指定维度上的工作项编号,其中“0”这个参数,可获取当前第一维上工作项的ID信息。
__kernel
void vecadd(__global int *C, __global int *A, __global int *B){
int tid = get_global_id(0); // OpenCL intrinsic函数
c[tid] = A[tid] + B[tid];
}
1.clEnqueueNDRangeKernel的用法
OpenCL采用NDRange(Global Dimemsion Index Ranges)来组织所有work-item进行工作的。
cl_int clEnqueueNDRangeKernel ( cl_command_queue command_queue,
cl_kernel kernel,
cl_uint work_dim,
const size_t *global_work_offset,
const size_t *global_work_size,
const size_t *local_work_size,
cl_uint num_events_in_wait_list,
const cl_event *event_wait_list,
cl_event *event)
参数:
[command_queue] 一个有效的命令队列。内核将在与command_queue关联的设备上排队执行。
[kernel] 一个有效的内核对象。与kernel和command_queue关联的OpenCL上下文必须是相同的。
[work_dim] 用于指定全局工作项和工作组中的工作项的维数。Work_dim必须大于0且小于或等于3。
[global_work_offset] 当前必须是NULL值。在OpenCL的未来版本中,global_work_offset可以用来指定一个work_dim无符号值数组,用来描述用于计算工作项全局ID的偏移量,而不是让全局ID总是从offset(0,0,…0).
[global_work_size] 指向一个work_dim无符号值数组,该数组描述work_dim维度中将执行内核函数的**全局工作项的数量。**全局工作项的总数被计算为global_work_size[0] … global_work_size[work_dim - 1]。global_work_size中指定的值不能超过内核执行将在其上排队的设备的sizeof(size_t)给出的范围。设备的sizeof(size_t)可以通过使用clGetDeviceInfo的OpenCL设备查询表中的CL_DEVICE_ADDRESS_BITS来确定。例如,如果CL_DEVICE_ADDRESS_BITS = 32,即设备使用32位地址空间,则size_t是32位无符号整数,global_work_size值必须在1范围内。2 ^ 32 - 1。超出此范围的值将返回CL_OUT_OF_RESOURCES错误。
[local_work_size] 指向work_dim无符号值的数组,该数组描述组成工作组的工作项的数量(也称为工作组的大小),这些工作项将执行由kernel指定的内核。工作组中工作项的总数计算为local_work_size[0] … local_work_size[work_dim - 1]。工作组中工作项的总数必须小于或等于在OpenCL设备查询clGetDeviceInfo表中指定的CL_DEVICE_MAX_WORK_GROUP_SIZE值和在local_work_size[0],…local_work_size [work_id]。实际情况由于设备和内核的不同,导致该参数在设置时候不同,要根据硬件配置来设置。尝试clGetKernelWorkGroupInfo(),获取local_work_size
[event] 返回标识此特定内核执行实例的事件对象。事件对象是惟一的,以后可以用来标识特定的内核执行实例。如果event为NULL,则不会为这个内核执行实例创建任何事件,因此应用程序将不可能查询或排队等待这个特定的内核执行实例。一般用于GPU 运算耗时统计。
下面举一个NDRange为二维的例子
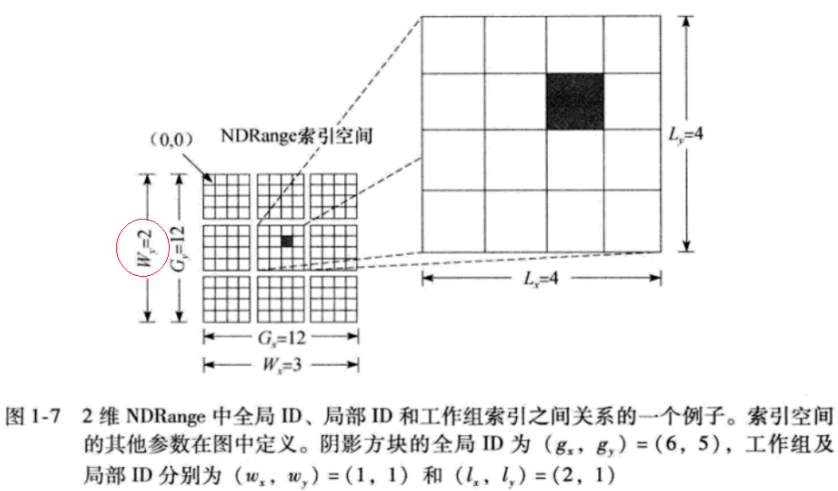
从该图可知:
- 每一个小方格代表了一个工作项work-item
- 每个4×4的中方格代表了一个工作组work-group
- 整个12×12的大方格代表了整个NDRange空间
该图中可以通过以下代码得到相应的数据:
uint dim=get_work_dim();//dim=2 size_t global_id_0=get_global_id(0);//从参数global_offset(0,0)第一个参数0开始,个数为global_size(12,12)的第一参数12 size_t global_id_1=get_global_id(1);//从参数global_offset(0,0)第二个参数0开始,个数为global_size(12,12)的第二个参数12 size_t global_size_0=get_global_size(0);//大小为global_size(12,12)的第一个参数12,即全局空间第一个维度的大小 size_t global_size_1=get_global_size(1);//大小为global_size(12,12)的第二个参数12,即全局空间第二个维度的大小 size_t offset_0=get_global_offset(0);//获取global_offset(0,0)的第一个参数0 size_t offset_1=get_global_offset(1);//获取global_offset(0,0)的第二个参数0 size_t local_id_0=get_local_id(0);//获取local_size(4,4)的第一个参数个数4,即局部空间(组内空间)第一个维度的大小 size_t local_id_1=get_local_id(1);//获取local_size(4,4)的第二个参数个数4,即局部空间(组内空间)第二个维度的大小
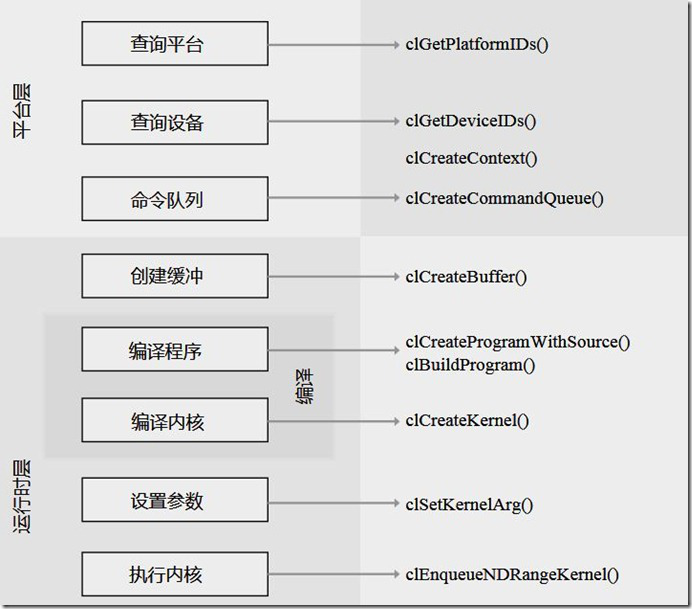
2.创建并执行一个简单的OpenCL应用大致需要以下几步:
- 查询平台和设备信息
- 创建一个上下文
- 为每个设备创建一个命令队列
- 创建一个内存对象(数组)用于存储数据
- 拷贝输入数据到设备端
- 使用OpenCL C代码创建并编译出一个程序
- 从编译好的OpenCL程序中提取内核
- 执行内核
- 拷贝输出数据到主机端
- 释放资源
OpenCL向量相加的例子:
// This program implements a vector addition using OpenCL // System includes #include #include #include // OpenCL includes #include // OpenCL kernel to perform an element-wise addition const char* programSource = "__kernel \n" "void vecadd(__global int *A, \n" " __global int *B, \n" " __global int *C) \n" "{ \n" " \n" " // Get the work-item’s unique ID \n" " int idx = get_global_id(0); \n" " \n" " // Add the corresponding locations of \n" " // 'A' and 'B', and store the result in 'C'. \n" " C[idx] = A[idx] + B[idx]; \n" "} \n" ; int main() { // This code executes on the OpenCL host // Host data int *A = NULL; // Input array int *B = NULL; // Input array int *C = NULL; // Output array // Elements in each array const int elements = 2048; // Compute the size of the data size_t datasize = sizeof(int)*elements; // Allocate space for input/output data A = (int*)malloc(datasize); B = (int*)malloc(datasize); C = (int*)malloc(datasize); // Initialize the input data int i; for(i = 0; i







