

目录
- 一、希尔排序原理
- 1. 插入排序的问题
- 2. 希尔排序的思路
- 二、希尔排序的相关问题
- 1. 为什么插入排序那么多但效率却很高
- 2. 如何选择希尔增量
- 三、代码实现
- 1. 代码实现思路
- 2. 实现代码
希尔排序是对直接插入排序的优化,在学习之前,没有学过插入排序的童鞋们建议先学习插入排序:点击跳转到插入排序😜
一、希尔排序原理
1. 插入排序的问题
逆序有序的数组排序时,时间复杂度为 O ( n 2 ) O(n^2) O(n2),此时效率最低
顺序有序的数组排序时,时间复杂度为 O ( n ) O(n) O(n),此时效率最高
我们发现,当被排序的对象越接近有序时,插入排序的效率越高,那我们是否有办法将数组变成接近有序后再用插入排序,此时希尔大佬就发现了这个排序算法,并命名为希尔排序
2. 希尔排序的思路
希尔排序是对插入排序的优化,基本思路是先选定一个整数作为增量,把待排序文件中的所有数据分组,以每个距离的等差数列为一组,对每一组进行排序,然后将增量缩小,继续分组排序,重复上述动作,直到增量缩小为1时,排序完正好有序。
希尔排序原理是每一对分组进行排序后,整个数据就会更接近有序,当增量缩小为1时,就是插入排序,但是现在的数组非常接近有序,移动的数据很少,所以效率非常高,所以希尔排序又叫缩小增量排序。
每次排序让数组接近有序的过程叫做预排序,最后一次插入是直接插入排序
- 以3作为增量对数组进行分组,以下数组被分成3组,每组之间都是以3的等差数列

- 对每一组进行插入排序,得到如下数组
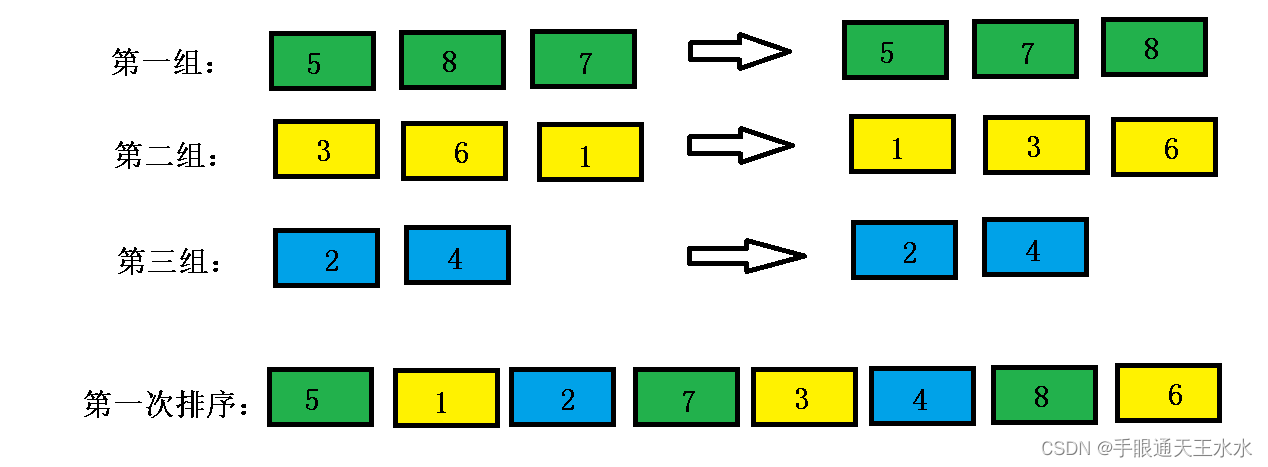
- 此时增量缩小,以2为增量对数组进行分组,数组被分成2份,每组之间都是2的等差数列

- 对每一组进行插入排序,得到如下数组
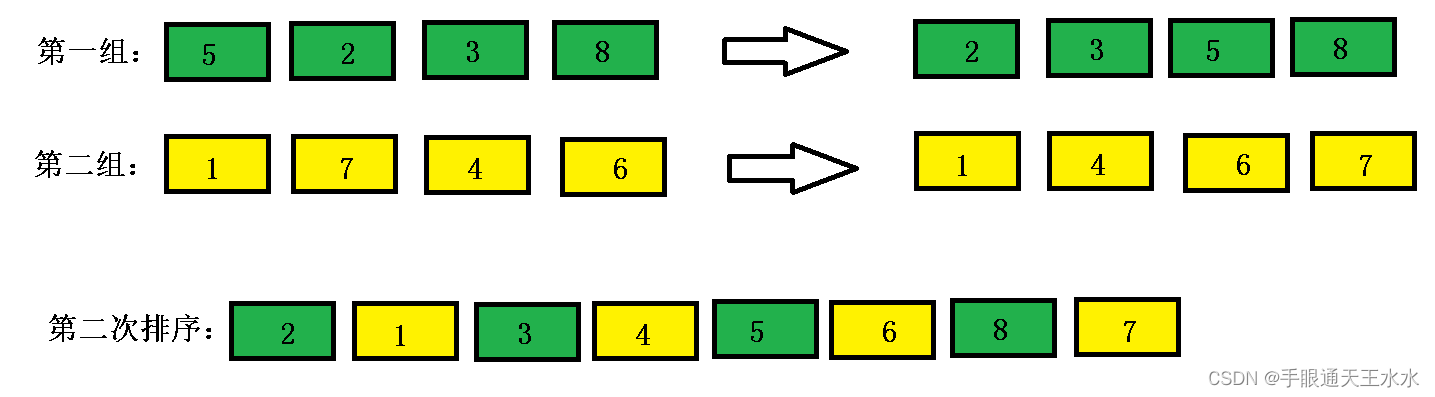
- 最后增量为1,分为1组(其实就等于没分),对其进行插入排序,数组变得有序

二、希尔排序的相关问题
1. 为什么插入排序那么多但效率却很高
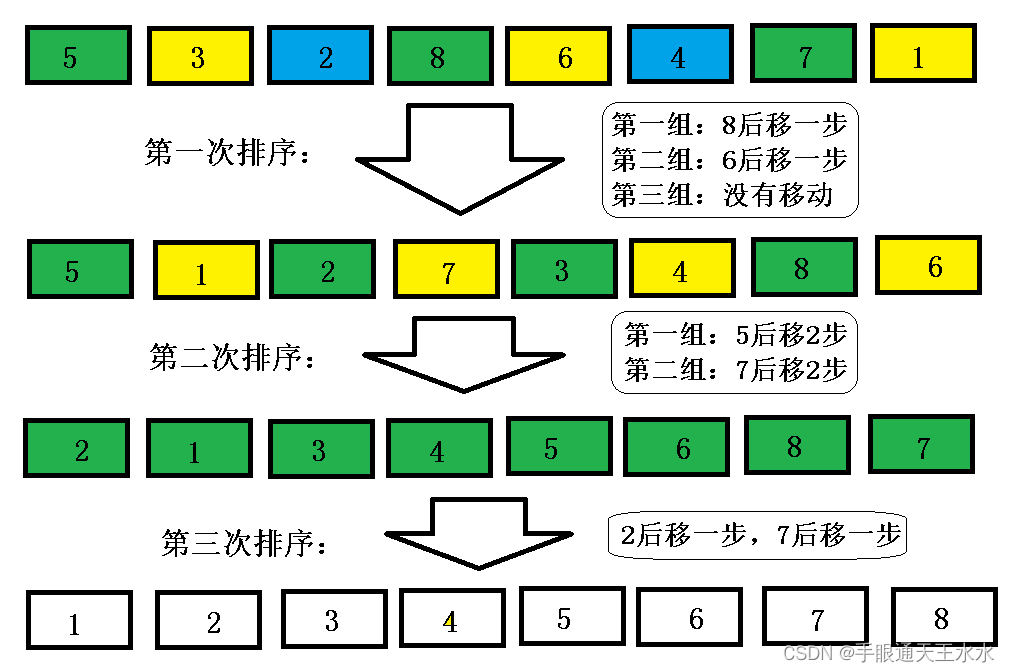
- 希尔排序中待排数据每次是以增量的移动步数空出插入位置,所以效率比普通插入一次一步的移动方式要快


-
每一次排序之后数组就会变得接近有序,插入排序的移动次数就会越来越少,效率也不是普通的插入排序能比的了
-
希尔排序移动次数:共移动8步
- 直接插入排序移动次数:共移动15步
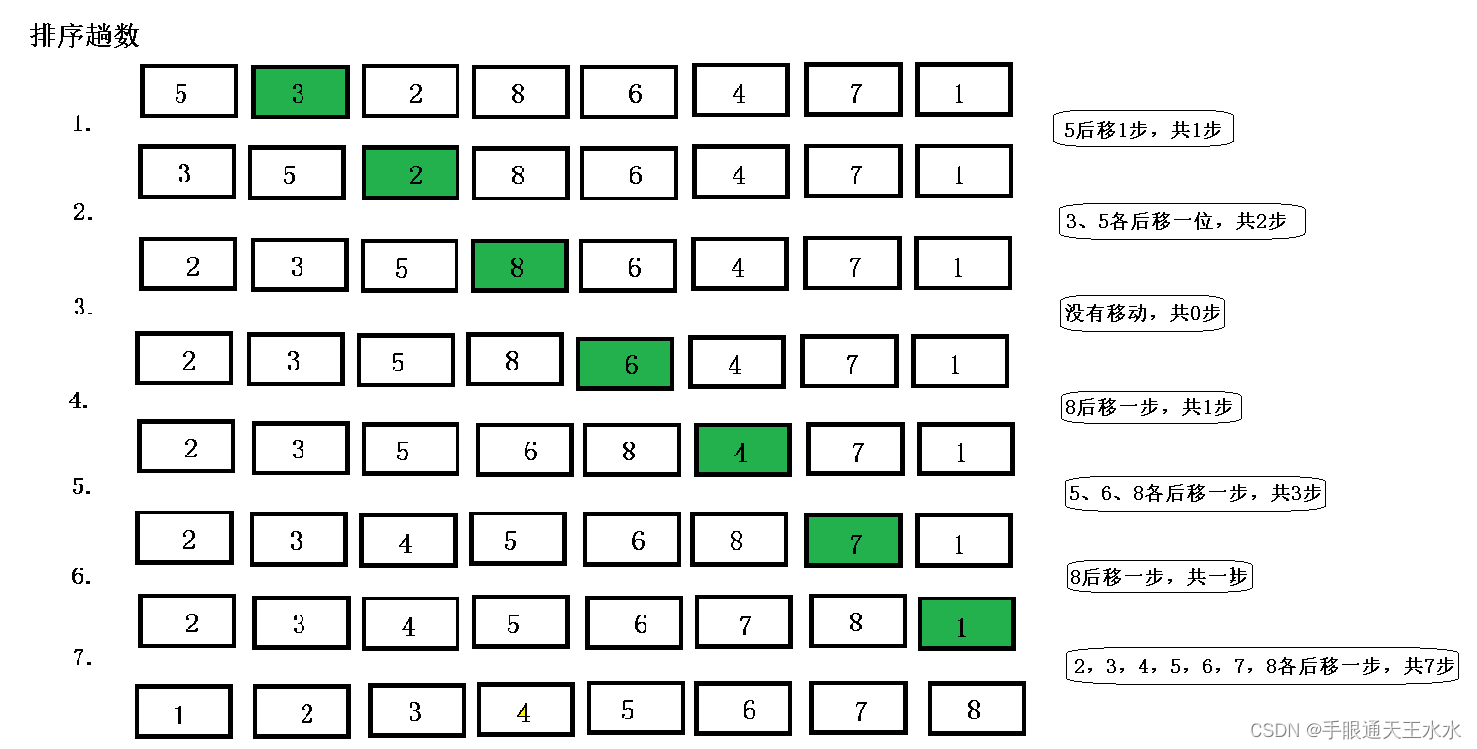
综上所述:希尔排序在越大的数组上更能发挥优势,因为步子迈的更大,减少插入排序的移动次数更多
2. 如何选择希尔增量
希尔排序的分析是一个复杂的问题,它的时间是一个关于增量序列的函数,这涉及到一些数学上未能攻克的难题,所以目前为止对于希尔增量到底怎么取也没有一个最优的值,但是经过大量研究已经有一些局部的结论,在这里并不展开叙述。
最初希尔提出的增量是 gap = n / 2,每一次排序完让增量减少一半gap = gap / 2,直到gap = 1时排序变成了直接插入排序。直到后来Knuth提出的gap = [gap / 3] + 1,每次排序让增量成为原来的三分之一,加一是防止gap int gap = size; while (gap 1) { gap = gap / 3 + 1; //调整希尔增量 int i = 0; for (i = 0; i = 0) { if (arr[end] > temp) { arr[end + gap] = arr[end]; end -= gap; } else { break; } } arr[end + gap] = temp; //以 end+gap 作为插入位置 } } }







