

1. 背景介绍
1.1 人工智能的崛起
随着计算机技术的飞速发展,人工智能(AI)已经成为了当今科技领域的热门话题。从自动驾驶汽车到智能家居,AI技术正在逐渐渗透到我们的日常生活中。在这个过程中,大型语言模型(Large Language Models,简称LLMs)作为AI领域的一种重要技术,已经在各种应用场景中取得了显著的成果。
(图片来源网络,侵删)
1.2 大型语言模型的崛起
大型语言模型是一种基于深度学习的自然语言处理技术,通过对大量文本数据进行训练,可以生成具有一定语义理解能力的模型。近年来,随着硬件计算能力的提升和算法的优化,大型语言模型的规模和性能都得到了极大的提升。例如,OpenAI的GPT-3模型就拥有超过1750亿个参数,可以完成各种复杂的自然语言处理任务。
然而,随着大型语言模型的应用越来越广泛,人们对其可解释性和可信赖性的关注也日益增加。本文将从理论和实践的角度,深入探讨大型语言模型的可解释性与可信赖性问题,并提供一些实际应用场景和工具资源推荐。
(图片来源网络,侵删)
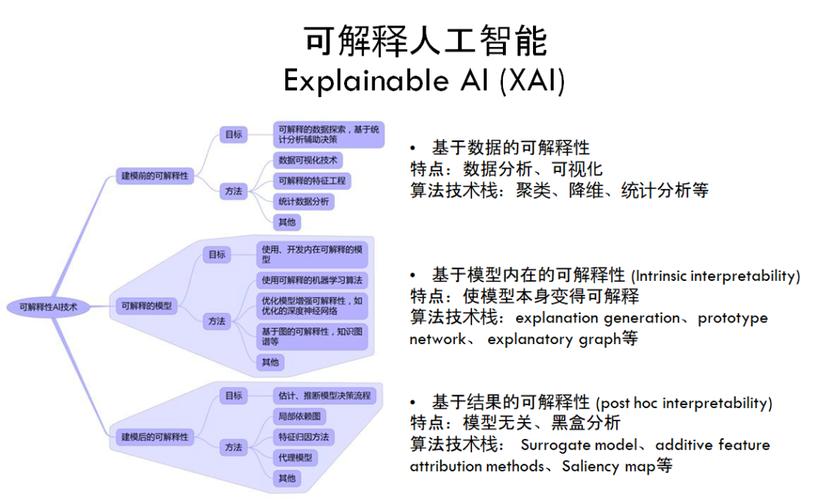
2. 核心概念与联系
2.1 可解释性
可解释性(Interpretability)是指一个模型的内部结构和工作原理能够被人类理解的程度。对于大型语言模型来说,可解释性主要体现在以下几个方面:
- 模型结构:模型的结构是否足够简单,以便人们可以理解其工作原理。
- 参数解释:模型的参数是否具有明确的语义含义,以便人们可以理解其对模型行为的影响。
- 输出解释:模型的输出是否可以通过一定的规则或逻辑进行解释,以便人们可以理解其生成过程。
2.2 可信赖性
可信赖性(Trustworthiness)是指一个模型在实际应用中的可靠性和稳定性。对于大型语言模型来说,可信赖性主要体现在以下几个方面:
- 预测准确性:模型在各种任务中的预测准确性是否达到了较高水平。
- 泛化能力:模型是否具有较强的泛化能力,能够在不同领域和场景中取得良好的性能。
- 鲁棒性:模型是否具有较强的抗干扰能力,能够在面对噪声和异常数据时保持稳定的性能。
- 安全性:模型是否具有较强的安全性,能够抵抗各种攻击和操纵。
2.3 可解释性与可信赖性的联系
可解释性和可信赖性是衡量大型语言模型性能的两个重要指标,它们之间存在一定的联系。一方面,具有较高可解释性的模型通常更容易被人们接受和信任,因为人们可以通过理解模型的工作原理来判断其可靠性。另一方面,具有较高可信赖性的模型通常也更容易被解释,因为其预测结果和行为表现更加稳定和一致。
然而,在实际应用中,可解释性和可信赖性往往是一对矛盾的指标。具有较高可解释性的模型通常结构较简单,参数较少,而这







