

论文
Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks
论文链接
paper:Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks
模型结构
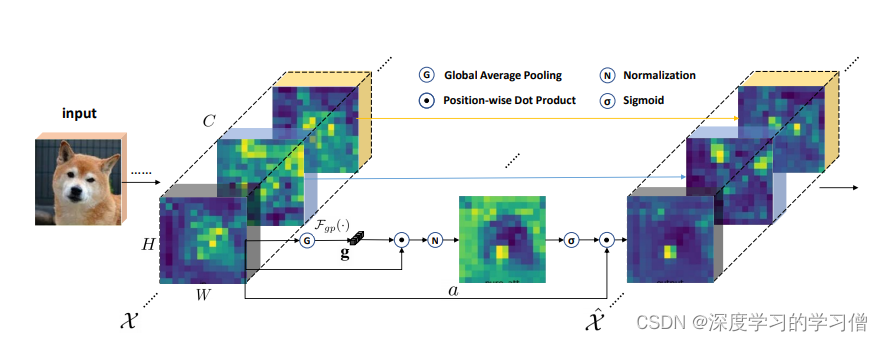
论文主要内容
卷积神经网络(CNN)通过收集不同层次和不同部分的语义子特征来生成复杂对象的特征表示。这些子特征通常可以以分组形式分布在每一层的特征向量中,代表各种语义实体。然而,这些子特征的激活往往在空间上受到相似模式和噪声背景的影响,从而导致错误的定位和识别。本文提出了一个空间组增强(SGE)模块,该模块可以通过为每个语义组中的每个空间位置生成一个注意因子来调整每个子特征的重要性,从而每个单独的组可以自主地增强其学习的表达,并抑制可能的噪声。注意因素仅由各组内部的全局和局部特征描述符之间的相似性来引导,因此SGE模块的设计非常轻量级,几乎没有额外的参数和计算。
import numpy as np
import torch
from torch import nn
from torch.nn import init
class SpatialGroupEnhance(nn.Module):
def __init__(self, groups):
super().__init__()
self.groups=groups
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.weight=nn.Parameter(torch.zeros(1,groups,1,1))
self.bias=nn.Parameter(torch.zeros(1,groups,1,1))
self.sig=nn.Sigmoid()
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, h,w=x.shape
x=x.view(b*self.groups,-1,h,w) #bs*g,dim//g,h,w
xn=x*self.avg_pool(x) #bs*g,dim//g,h,w
xn=xn.sum(dim=1,keepdim=True) #bs*g,1,h,w
t=xn.view(b*self.groups,-1) #bs*g,h*w
t=t-t.mean(dim=1,keepdim=True) #bs*g,h*w
std=t.std(dim=1,keepdim=True)+1e-5
t=t/std #bs*g,h*w
t=t.view(b,self.groups,h,w) #bs,g,h*w
t=t*self.weight+self.bias #bs,g,h*w
t=t.view(b*self.groups,1,h,w) #bs*g,1,h*w
x=x*self.sig(t)
x=x.view(b,c,h,w)
return x
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
sge = SpatialGroupEnhance(groups=8)
output=sge(input)
print(output.shape)
代码解析
该模块可以增强CNN中特征图的表达能力,并提升其性能。
在此代码块中,定义了两个变量b和c,分别表示输入x的batch size和通道数。
接着,执行了reshape操作,将每个channel划分为self.groups个group。第一行中,x经过reshape之后变成了大小为(b*groups,dim//groups,h,w)的张量。
然后,这个被划分为group的特征图通过 x n = x 1 H W ∑ x xn=x\frac{1}{HW}\sum x xn=xHW1∑x的方法,生成了加权后的特征图,其中H*W为特征图的像素点个数,由avg_pool操作保证输出特征图形状一致。
接着,执行了 x n xn xn 的加权操作。
之后,将加权后的张量 t t t进行标准化操作,即每个元素减去均值并除以方差。
在这个阶段,t被视为group的全局平均值(rolling-mean)和标准差(rolling-std)。group内的每个值被减去它们的group的rolling-mean,再除以该group的rolling-std。标准化的结果被保存在张量t中。
并且,执行了激活函数的计算,即t * self.weight + self.bias,其中self.weight和self.bias是可学习的参数。
然后,执行了x * the sigmoid of t 操作,并将结果再次分组。
将正常化之后的结果乘以原始输入“x”(第三行代码),并将结果reshape成最终输出的形式。







