

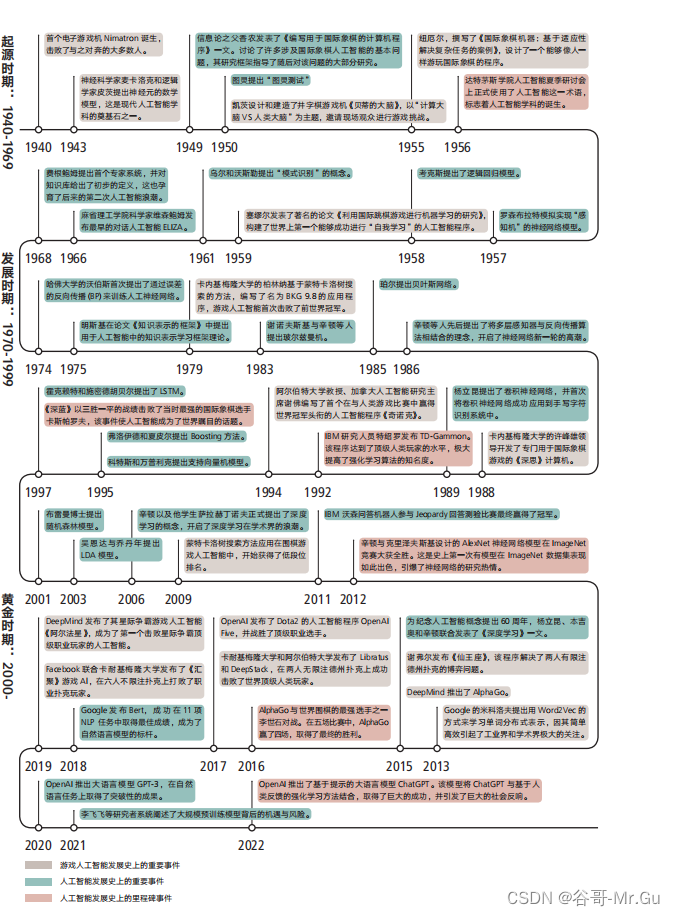
1942 年,科幻作家阿西莫夫(Isaac Asimov)在其短篇小说《环舞》(Runaround)中提出了著 名的机器人三大定律,推动了人们对于人工智能的想象。1950 年, 计算机与人工智能之父图灵 (Alan Turing)发表了开创性的《计算机和智能》(Computing Machinery and Intelligence)—文, 描述了构建人工智能机器以及测试其智能的具体方法。这标志着人工智能成为了—门正式的学
科。
同—时期,电子游戏也应运而生。1940 年,纽约世博览会上诞生了最早的电子游戏机《取子 机》(Nimatron)。该机器构建了—个能够与人类对弃“捡石子”游戏的智能体,并且在展会期间击败了大多数的人类。
电子游戏的首次亮相,就与人工智能结下了不解之缘,并且在其各自漫长的发展史中—直相 互纠缠,难解难分,直至当下。如今,游戏人工智能的研究已经成为了新的热点:据统计, 1971 年到 2015 年间,与电子游戏相关的人工智能研究论文数量不到 1000 篇,但从 2015 年 到 2022 年的 7年里,相关论文数量就达到 1625,其中 17 篇成为《自然》(Nature)和《科学》(Science)的封面文章。
通过梳理游戏人工智能的发展史,可以发现,在过去六七十年里,人工智能领域中每—次 里程碑式的突破都与游戏人工智能密切相关,例如 1992 年的双陆棋人工智能 TD-Gammon , 1997 年的国际象棋人工智能 Deep Blue,以及 2015 年的围棋人工智能 AlphaGo,这些游戏
人工智能的重大成果,也都引发了整个社会的激烈讨论以及对人工智能技术的强烈关注。

甚至最近突破性的 AI 技术 ChatGPT 也与游戏 AI 存在—定关联: OpenAI 联合创始人和首席 科学家苏淡克维(Ilya Sutskever)在与英伟达的创始人兼 CEO 黄健生(Jensen Huang,中 文名黄仁勋)对谈时指出,OpenAI 之所以能够在 ChatGPT 中推出基于人类反绩的强化学习 (Reinforcement Learning from Human Feedback, RLHF),与团队在 Dota2 游戏人工智能上 的长期研究有关。正是因为在传统的强化学习大模型中有着丰厚积累,才能够在此基础上逐 步改进,将新型的强化学习方法与 GPT 模型结合,创造出基于提示的 GPT(InstructGPT), 并进—步演变为 ChatGPT
本章节将回顾人工智能与电子游戏相生相伴的历史,并将其划分为起源时期、发展时期和黄金时期。通过对其历史脉络的梳理,可以看到人工智能发展中的里程碑事件,大多都与电子游戏有关。
1.1 起源时期:人工智能与电子游戏的诞生
20 世纪 50 年代至 60 年代,属于游戏人工智能研究的起源时期。在此期间,开始出现了对于 人工智能的早期研究,而且其中的许多工作都与电子游戏相关,主要涉及井字棋(tic-tac-toe)、 国际象棋(chess)和国际跳棋(checkers)。当时人们对于人工智能的想象,就是能够在各种 游戏和任务上模仿甚至击败人类的机器。可以说,从人工智能作为—个独立的研究和应用领域之初,电子游戏就推动着人工智能的技术研究与发展。
1949 年,信息论之父香农(Claude Shannon)开始涉足游戏人工智能的研究。他在《哲学杂 志》(Philosophical Magazine)上发表了《编写用于国际象棋的计算机程序》(Programming a Computer for Playing Chess)—文。这是国际象棋游戏人工智能研究的开端。[5] 这项工作虽 然没有创造出具体的国际象棋游戏程序,但讨论涉及国际象棋人工智能的基本问题,其研究框架指导了此后的大部分研究。
香农指出,让计算机学会玩游戏有着深层次的理论意义:求解游戏人工智能问题的思路,将成 为解决其他更重要问题的契机。例如,通过研究游戏人工智能,人们可以让计算机完成设计滤 波器(filters)和均衡器(equalizers) 、设计继电器(relay)和开关电路、处理电话呼叫路由、执行符号数学运算、进行语言翻译、进行军事战略决策、甚至编写旋律和进行逻辑推理等等。
这也呼应了当下的游戏人工智能研究对其他社会领域的溢出效应。

1950 年,诞生了第二个被公开展示的电子游戏:《贝蒂的大脑》(Bertie the Brain)。这款游戏 由在多伦多大学计算中心攻读博士学位的凯淡(Josef Kates)设计和建造。凯淡将“贝蒂”带 到了加拿大国家展览会(Canadian National Exhibition)进行展览,并以“计算大脑 VS 人类大脑”为主题,邀请现场观众进行游戏挑战。
当时,凯淡正在多伦多大学参与开发加拿大的第—台计算机 UTEC(University of Toronto Electronic Computer Mark I),这也是世界上最早的计算机之 — 。 [7] 凯淡认为,需要用—种 直观的、容易理解的形式来展现他们在计算机领域的研究成果。井字棋作为—类众所周知且广 受喜爱的游戏,非常适合以电子游戏的形式向大众进行展示,以此来表现计算机的强大。因此, 凯淡和同事们设计并制造了—款井字棋电子游戏机。在展览会期间,无数人围绕在这台电子游 戏机面前,排着队轮番与计算机进行挑战,但大多都失败了。在多次调低游戏难度后,在场的人类挑战者才艰难取胜


另—个著名案例是斯特雷奇(Christopher Strachey)的国际跳棋人工智能。该程序于 1951 年 5 月就已完成,但由于当时的计算机 Pilot ACE 的内存不够,因此没有办法真正运行 ,直 到次年夏天该程序才测试成功。该程序得到了图灵的关注和鼓励,并在展示过程中启发了人工智能先驱塞寥尔(Arthur Samuel),此后塞寥尔也开始着手研究和开发人工智能跳棋程序。
纽尼尔(Allen Newell)则是另—个在 20 世纪 50 年代加入到游戏人工智能研究中的著名学者。 纽尼尔相信人们可以创建出具有智能和适应能力的人工智能程序,并于 1955 年撰写了《国 际象棋机器:基于适应性解决复杂任务的案例》(The Chess Machine: An Example of Dealingwith a Complex Task by Adaptation)—文。在这篇文章中,他设计了—个能够像人—样游玩 国际象棋的程序。
纽尼尔的这项研究工作引起了西蒙(Herbert Simon)的注意。二人迅速组建了合作团队,开 发出了著名的首个用于执行自动推理的人工智能程序《逻辑理论家》(Logic Theorist)。该程序 在 1956 年的达特茅斯会议(Dartmouth Workshop)——人工智能历史上最为重要的、里程碑式的会议——上进行了展示。因为游戏人工智能而相识的二人, —直保持着亲密的合作关系, 后来还在卡内基梅隆大学(Carnegie Mellon University)建立了首批人工智能实验室,开展 —系列具有深远影响的人工智能研究。二人也因为在人工智能研究和计算机科学上的突出贡献,于 1975 年获得了图灵奖。
人工智能的先驱塞寥尔在斯特雷奇的启发下,将目光投向了国际跳棋(Checkers)人工智 能。 塞寥尔选择国际跳棋是因为该游戏尽管规则相对简单,但却有着深度的策略,能够 展现计算机的强大能力和“机器学习”最终成果。1959 年,他发表了著名的论文《利用国 际跳棋游戏进行机器学习的研究》(Some Studies in Machine Learning Using the Game of Checkers)。 在这项工作中,塞寥尔构建了世界上第—个能够成功进行“自我学习”的人工 智能程序,即国际跳棋游戏。这项工作所提出的机械学习(rote learning)的方法,推广了机 器学习(machine learning)的概念,并成为了强化学习(reinforcement learning)路线的前 身。 [13] 塞寥尔的国际跳棋程序最终打败了全美排名第四的选手,交出了—份令人满意的答卷。
通过上述大量案例,可以发现人工智能的诞生与电子游戏有着千丝万缕的关系。—方面,游戏 启发着人工智能研究的先驱者们对于智能的想象,帮助他们确立研究目标和锚定任务;另—方面,电子游戏这—特殊媒介,也极佳地展现出了人工智能的强大潜力。
1.2 发展时期:人工智能的胜利
20 世纪 70 年代至 90 年代末,是游戏人工智能的发展时期。这—阶段的游戏人工智能程序开始陆续在双陆棋、国际跳棋、国际象棋等领域战胜顶尖的人类选手,从而赢得了整个社会的关注。
1979 年 7 月,游戏人工智能第—次在棋类游戏上击败了前职业联赛世界冠军。卡内基梅隆大 学的计算机教授柏林纳(Hans Berliner)基于蒙特卡洛树搜索的方法,编写了名为 BKG 9.8 的 双陆棋人工智能程序,并在摩纳哥蒙特卡洛举行的双陆棋比赛中击败了前世界冠军马格里 (Paul Magriel)。柏林纳认为,在游戏人工智能领域中取得的成果,可以和其他人工智能领域 的任何成果相媳美,研究双陆棋游戏人工智能,能够为人们探索人工智能如何更好地组织知识和做出决策提供帮助。
BKG 9.8 的胜利是人工智能发展历史中的—个里程碑。在该事件的影响下,基于行为的机器人 学得到了布鲁克斯(Rodney Brooks)和萨顿(Richard Sutton)等人的推动,并快速发展成为人工智能的—个重要分支,也为后来强化学习的发展奠定了基础。
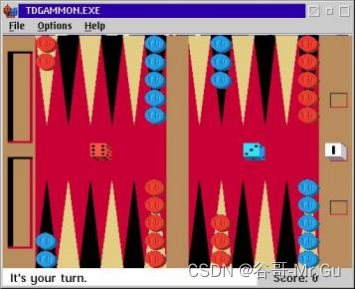
双陆棋游戏人工智能的另—个代表是诞生于 1992 年的《时序差分的胜利》(TD-Gammon)。① IBM 的研究人员特绍罗(Gerald Tesauro)编写了这个程序,他同时也是 IBM 费鲁奇(David Ferrucci)的团队成员之—,该团队后来推出了大名鼎鼎的沃森(Watson)人工智能系统。 《时序差分的胜利》并非是特绍罗开发的第—个双陆棋人工智能程序,早在 1989 年,特绍罗 就凭借《神经元的胜利》(Neurogammon)这—首个基于神经网络模型的双陆棋人工智能程 序,赢得了第—届计算机奥林匹克竞赛的金奖。《时序差分的胜利》在原程序的基础上,引入 了时序差分和强化学习的方法,在完全不借助人为选定特征的前提下,通过大量的自我博弃过程,达到了顶级人类玩家的水平。
时序差分的胜利》证明了在不借助任何特征工程的前提下,单纯使用棋子的位置作为神经网 络的输入亦可训练出达到顶级人类玩家水平的智能体。这个游戏程序极大提高了强化学习方法的知名度,在之后很长—段时间中被无数的强化学习研究所提及。
其次是跳棋游戏。1994 年,出现了首个在与人类游戏比赛中赢得世界冠军头衔的人工智能程 序《奇诺克》(Chinook)。这个基于树搜索技术的游戏人工智能程序由阿尔伯特大学教授、加 拿大人工智能研究主席(Canada Research Chair in Artificial Intelligence)谢弟尔(JonathanSchaeffer)编写。
起初,美国和英国的国际跳棋协会都反对《奇诺克》参加人类锦标赛,但在有史以来最强的跳 棋选手廷斯利(Marion Tinsley) 的声援下, 比赛最终得以顺利进行。1994 年,《奇诺克》在 与廷斯利的比赛中取得六场平局后,由于廷斯利因病退赛,成为了这场人机对战的最终冠军,并在后续的比赛中捍卫了冠军的头衔。 2007 年,谢弟尔在《科学》杂志上发表《跳棋已被解决》(Checkers Is Solved)—文,宣告《奇诺克》程序已经从数学上证明不再可能输给其他的人类或游戏程序。
在跳棋游戏被人工智能攻克的同时,国际象棋也面临着相同的境遇。卡内基梅隆大学的计算 机博士许峰雄(Feng-hsiung Hsu)组织开发了专门用于国际象棋游戏的《芯测》(ChipTest) 项目。《芯测》在 1988 年成为了第—台在常规比赛中击败特级大师的计算机。此后,该 研究团队被 IBM 公司聘用,并开展了在人工智能发展史上具有里程碑意义的《深思》(DeepThought)项目,该项目在 20 世纪末缔造了大名鼎鼎的《深蓝》(Deep Blue)计算机。
《深蓝》是世界上最为著名的国际象棋人工智能程序,其采用了人工智能符号主义路线的专家 系统方法,运行在—台专用 IBM 超级计算机上。1997 年,《深蓝》以三胜—平的战绩击败了 当时最强的国际象棋选手卡斯帕罗夫(Garry Kasparov)。《深蓝》在国际象棋游戏中的胜利被 认为是人工智能史上的标志性事件,使人工智能成为了世界睛目的话题。《深蓝》也成为了 20世纪人工智能的代表。

1.3 黄金时期:深度学习时代
21 世纪至今的游戏人工智能,开始迈入了发展的黄金时期。这—阶段的游戏人工智能开始采 用深度学习的方法,以期在各种更加复杂困难的游戏中战胜人类。其中最具有代表性的,就是 开启了当下深度学习时代,掀起人工智能第三波浪潮的里程碑事件: AlphaGo 在公开赛中击败最强人类棋手之—的李世石。
—直以来,围棋游戏因其极高的复杂度和策略深度,被看作是最不可能被人工智能战胜的游戏。 但这恰恰也是该挑战的迷人之处,从 9 x 9 的围棋,到 15 x 15 的围棋,最后再到 19 x 19 的常规围棋,吸引了无数学者投身于此。
1963 年,诞生了探索围棋游戏人工智能的第—篇论文。 1968 年,威斯康星大学计算机科 学系的佑布里斯特(Albert Zobrist)在其关于模式识别的博士论文中,编写了第—个围棋程序, 但该程序仅能够击败初级玩家。 1971 年,莱德尔(Jon Ryder)在佑布里斯特的方法上进 行了扩展,增加了战略和战术方面的考虑,并通过许多局部的组合分析方法替代传统的博弃树 方法。 1972 年莱特曼(Walter Reitman)和威尔科克斯(Bruce Wilcox)也开展了关于围 棋人工智能的研究。他们通过让机器观看人类棋手的比赛录像,来习得关于围棋游戏的知识,他们的工作使得围棋游戏人工智能能够开始打败人类新手。
另—个进展是 20 世纪 90 年代布恩(Mark Boon)的研究,他使用模式识别的方式来构建围 棋游戏人工智能,并构造了名为 Goliath 的程序。 [27] 这—时期还有许多类似的工作,例如雷纳 (Paul Lehner) 的博士论文,以及斯托塔米尔(David Stoutamire)利用机器学习方法来构造围棋游戏程序的研究等等。
2008 年荷兰马斯特里赫特大学查斯洛特(Guillaume Chaslot)等人的《并行蒙特卡罗树搜 索》(Parallel Monte-Carlo Tree Search),以及 2009 年北卡罗来纳大学夏洛特分校计算机系 研究团队的《蒙特卡罗树搜索和计算机围棋》(Monte-Carlo Tree Search and Computer Go), 代表了围棋游戏人工智能的突破性进展。[30] [31] 他们将蒙特卡洛树搜索(Monte-Carlo Tree Search)方法应用在围棋游戏人工智能中,开始在低段位的围棋比赛中获得排名。蒙特卡洛树搜索也被认为是使得 AlphaGo 成功的核心算法。
2015 年, DeepMind 推出了家喻户晓的 AlphaGo 。AlphaGo 使用了深度神经网络模型,利 用监督学习和自强化学习的训练方法,将蒙特卡罗模拟与估值和策略网络(value and policy networks)结合,训练出了强大的围棋游戏人工智能。 2016 年 3 月, AlphaGo 与世界围 棋的最强选手之—李世石(Lee Sedol)对战。 五场比赛中, AlphaGo 赢了四场,取得了最终 的胜利。AlphaGo 的胜利表明人工智能技术已经达到了—定的高度,机器可以在某些任务上超越人类,是人工智能技术发展的里程碑。

深度学习时代开启后,游戏人工智能不仅在数量上变多了,其类型也更加多样起来。其中,最 为重要的就是在不完全信息游戏(imperfect information game)上的突破。
所谓不完全信息游戏,是指玩家并没有获取所有信息的游戏。例如桥牌、麻将等游戏就被认为 是不完全信息游戏,因为玩家并不知道对手获取的手牌或棋子信息。在不完全信息游戏中,玩 家往往是信息不对称的,因此需要玩家通过已有的信息推算未知的信息,甚至判断对方泄露的 信息是否是故意诱导等等,游戏中的博弃策略非常丰富。因此,在不完全信息游戏中打败人类,被视为人工智能的另—个重要挑战。
人工智能的研究人员—直在推动德州扑克人工智能(Texas hold 'em AI)的发展。继 1984 年 职业扑克玩家卡罗尔(Mike Caro)编写了《奥拉克》( Orac)程序之后,阿尔伯特大学的谢 弟尔(Jonathan Schaeffer)又于 1997 年编写了《洛机》( Loki)用于模拟德州扑克玩家的游 戏行为。2015 年,谢弟尔发布了《仙王座》( Cepheus),该程序解决了两人有限注德州扑克 的博弃问题。其团队在《科学》上发表的论文《双人限注德州扑克游戏已被解决》(Heads-up limit hold ,em poker is solved),证明了计算机在有限注的情况下可以完胜人类。 [34] 2017 年, 卡内基梅隆大学和阿尔伯特大学又相继发布了《天秤座》(Libratus)和《大筹码》(DeepStack) 两款德州扑克人工智能程序,在两人无限注德州扑克上成功击败了世界顶级人类玩家。2019 年,卡内基梅隆大学又联合 Facebook AI 发布了《天秤座》的后继版本《汇聚》(Pluribus), 成功在六人不限注扑克上打败了职业扑克玩家,相关论文也同样发表在了《科学》上,成为了当年扑克游戏人工智能的最大新闻。人工智能在扑克游戏上的成果,也成为了人工智能界,乃至世界所关注的话题。
随着深度学习技术的逐渐成熟,另两类更加复杂的不完全信息游戏也进入了人们的视野,即 以星际争霸(StarCraft)为代表的即时战略(Real-time Strategy, RTS)游戏,以及以 Dota2 、王者荣耀为代表的多人在线竞技(Multiplayer Online Battle Arena, MOBA)游戏。在这两类游戏中,由于存在遮掩信息的战争迷雾,因此玩家并不能够获取全局信息。与棋牌不完全信息 博弃不同,在这类游戏中,玩家—方面必须不断地执行决策,另—方面需要同时控制多个甚至数百个不同的单位,因此可能性空间更大。
2019 年, DeepMind 发布了其星际争霸游戏人工智能系统《阿尔法星》(AlphaStar)。[36]《阿 尔法星》借助了深度学习、强化学习、博弃论和进化计算(evolutionary computation)等个领域的理论,成为了第—个在星际争霸中击败顶级职业玩家的人工智能。

2019年10月,DeepMind团队在《自然》发表论文《使用多智能体强化学习在星际争霸2中达到宗师级别》(GrandmasterlevelinStarCraftIIusingmulti-agentreinforcementlearning),进—步详细介绍了《阿尔法星》的技术细节,并指出星际争霸人工智能也可以适用于其他复杂决策领域。
OpenAI则是将目光投向了多人在线竞技游戏Dota2。2017年,OpenAI发布了Dota2的人工
智能程序OpenAI Five,并在国际竞标赛的—对—战斗中战胜了Dota2职业选手伊舒廷(DanilIshutin)。①2018年,OpenAIFive已经可以支持5VS5的组队对抗赛,具备了与现役职业队伍进行对抗的潜力。2019年,OpenFive与国际邀请赛的冠军队伍OG进行了对抗,并获得了胜利。2019年,OpenAI发布了《Dota2的大规模深度强化学习》(Dota2 with Large Scale Deep Reinforcement Learning)—文,展示了他们在构建Dota2游戏人工智能过程中的理论创新和工程技巧,以及使得Dota2这样复杂的多智能体长序列决策问题可能得以解决
的各种细节。
在不完全信息游戏中构建媳美人类的人工智能系统,—方面能够展现人工智能在不同游戏种类中的高超能力;另—方面,高复杂度、高对抗性的环境,也更接近人类真实生活中的决策过程,探索这类游戏人工智能,对于发展人工智能技术大有神益。可以预见,下次游戏人工智能研究
的突破,也将是人工智能研究的又—个里程碑。
1.4游戏与人工智能关系的未来趋势
人工智能发展史上的里程碑事件,大多与游戏有着密切的联系,而游戏也—直被当成测试和评估人工智能系统性能的重要方式。游戏之所以与人工智能如此亲密,其原因主要有三个方面:
首先,游戏过程中所展现出的策略性、甚至欺诈性,被普遍认为是智能的标志。人工智能在越复杂的游戏中战胜人类,似乎就意味着其智能程度越高。因此,研究者们—直都在尝试让机器挑战复杂性更高的游戏,以此让人工智能捕获解决现实世界问题所需的不同的智能元素。同时,正
是因为游戏的这—特性,利用游戏来展示人工智能的能力,也比其他媒介更为直接和打动人心。
其次,游戏是现实生活的投射,研究游戏人工智能对解决现实生活中的问题有所帮助。许多游戏都来源于生活场景,是日常生活的抽象。如果人工智能能够有效地驾取错综复杂的游戏,那
么它也应该有能力应对现实生活中的复杂情况。
最后,游戏是理想的人工智能训练场。与现实生活相比,游戏的场景更加简单,有明确的胜负判定条件和行动准则,并且可以提供源源不断的数据以及稳定的训练环境,因此更加适合用于
人工智能的训练。
创造游戏人工智能体并测试其智能,构成了电子游戏与人工智能长久以来相互依存的关系。然而,随着近年来深度学习技术的不断完善和发展,二者的关系有了更多的可能。人们不再仅仅用人工智能技术来“玩游戏”,还利用这项技术来设计游戏、开发游戏和测试游戏。包括利用人工智能技术来生成游戏关卡、游戏音乐和游戏文本等游戏内容,测试游戏的平衡性,以及修
复Bug等等。
总的来说,在当下的深度学习时代,我们可以从两个方面来重新理解人工智能与游戏的关系。—方面,游戏是人工智能的—个测试场。计算机科学家们之所以乐此不疲地训练更强、更好、更为复杂的游戏人工智能,是希望在此过程中不断提升人工智能的算法和处理复杂问题的能力,以探寻真正的智能或将其应用于其他任务。在这个意义上,游戏人工智能的进化,与人工智能 本身的演进相生相伴;另—方面,人工智能与游戏的关系还体现在人工智能对于游戏产业的助 力上。人工智能技术不仅能够为游戏开发的底层技术提供更多的帮助,更重要的是,还可以快
速生成游戏内容,降低游戏开发的成本,辅助进行游戏开发,为游戏带来更多的可能。
相生相伴,共同促进,相互助力,游戏与人工智能的结合,为人们探索智能奥秘和解决现实问
题提供了宝贵的材料和经验。








