

1. 背景介绍
1.1 人工智能的崛起
随着计算机技术的飞速发展,人工智能(AI)已经成为了当今科技领域的热门话题。特别是近年来,深度学习技术的突破性进展,使得AI在众多领域取得了显著的成果,如计算机视觉、自然语言处理、语音识别等。
(图片来源网络,侵删)
1.2 大语言模型的兴起
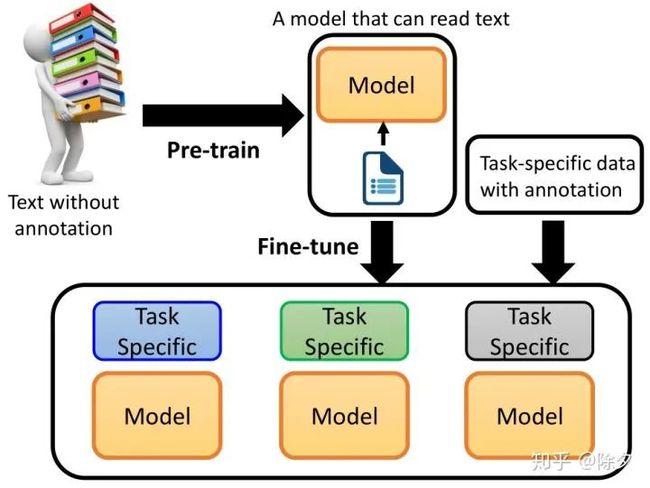
在自然语言处理(NLP)领域,大型预训练语言模型(如GPT-3、BERT等)已经成为了一种主流方法。这些模型通过在大量文本数据上进行预训练,学习到了丰富的语言知识,从而在各种NLP任务上取得了优异的表现。
1.3 预训练数据的重要性
为了训练这些大型语言模型,我们需要大量的高质量文本数据。预训练数据的质量和数量直接影响到模型的性能。因此,如何准备这些预训练数据成为了一个关键问题。
(图片来源网络,侵删)
本文将详细介绍AI大语言模型预训练数据的准备方法,包括核心概念、算法原理、具体操作步骤、最佳实践、实际应用场景等方面的内容。
2. 核心概念与联系
2.1 语言模型
语言模型是一种用于描述自然语言序列概率分布的数学模型。给定一个词序列,语言模型可以计算这个序列出现的概率。语言模型在自然语言处理任务中有着广泛的应用,如机器翻译、语音识别、文本生成等。
2.2 预训练与微调
预训练是指在大量无标签文本数据上训练语言模型,使其学习到通用的语言知识。微调是指在特定任务的有标签数据上对预训练好的模型进行调整,使其适应特定任务。
2.3 数据清洗与预处理
数据清洗是指对原始







