

今天学习的是,如何搭建一个机器学习模型。
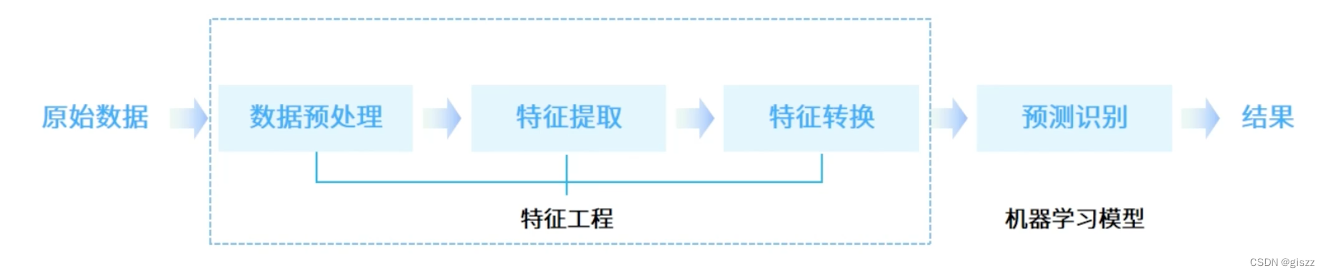
主要有以上的步骤:
- 原始数据采集
- 特征工程
- 数据预处理
- 特征提取
- 特征转换(构造)
- 预测识别(模型训练和测试)
在实际工作中,特征比模型更重要。
数据和特征的选择,已经决定了模型的天花板,模型算法只是去逼近这个上限。
在上述的特征工程中:
数据预处理,就是去除数据的噪声,例如文本中的错误、不再使用的词语等;
特征提取,就是从原始数据中提取一些有效的特征。例如图像分类中,提取边缘、尺度不变特征变换特征等。
特征转换和识别,就是对特征进行一定的加工,例如升维和降维。
再看下面的图:
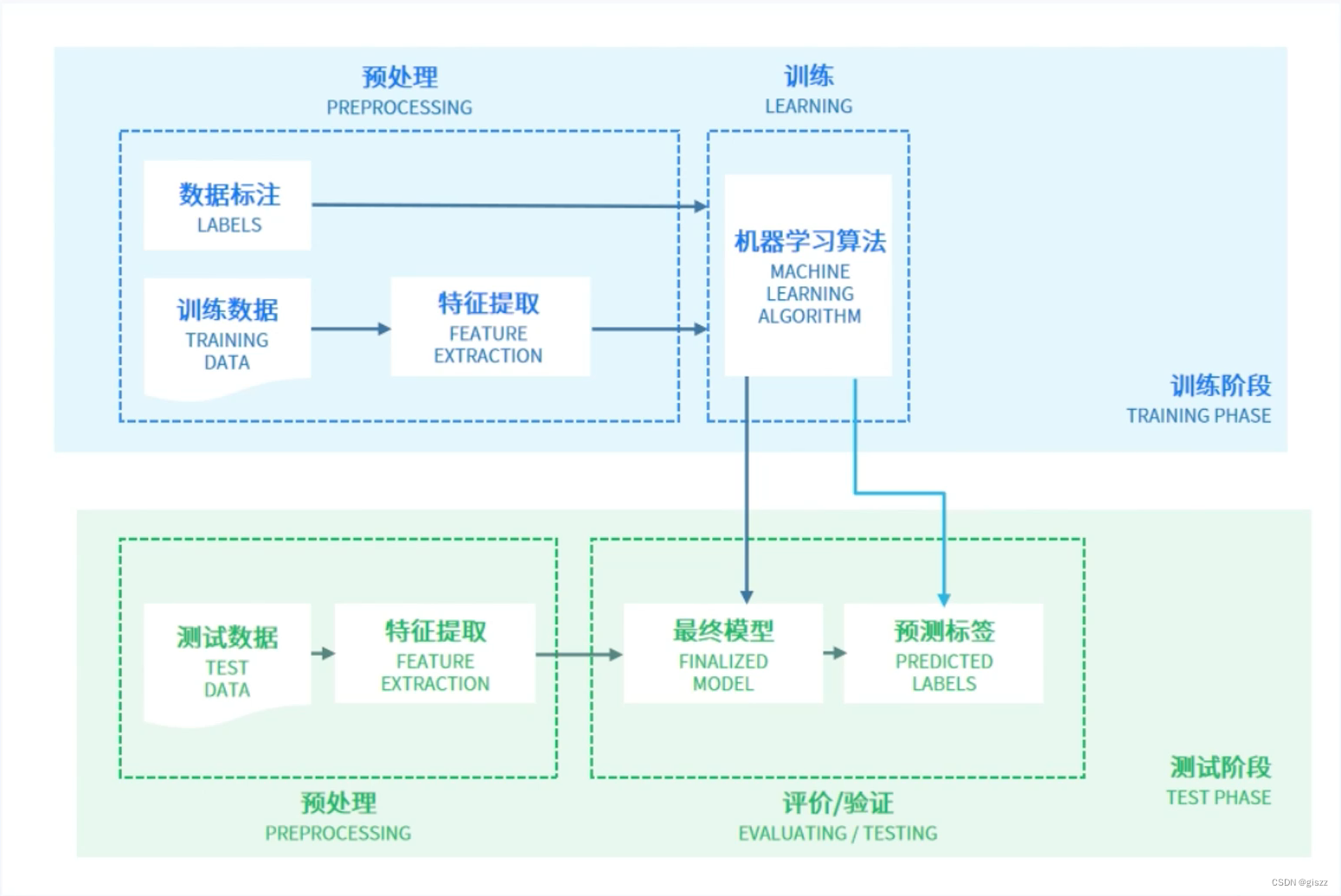
训练的过程和测试的过程是完全独立的。
延伸学习:
在人工智能领域,机器学习是一种让计算机系统从数据中学习并提升性能的技术。搭建一个有效的机器学习模型是一个复杂但非常有价值的过程。本文将详细阐述这一过程的主要步骤、所使用的方法、涉及的关键技术,以及需要注意的其他重要问题。
一、数据收集与预处理
步骤一:数据收集
搭建机器学习模型的第一步是收集数据。这些数据可以来自多种来源,如数据库、日志文件、API接口、传感器等。数据的质量和数量对模型的性能有直接影响,因此这一步至关重要。
步骤二:数据预处理
收集到数据后,需要进行预处理以使其适合机器学习算法。预处理步骤包括数据清洗(去除噪声、填充缺失值等)、特征工程(提取、转换和选择特征)、以及数据标准化或归一化等。
方法与关键技术
- 数据清洗:使用统计学方法识别并处理异常值,利用插值、均值填充等技术处理缺失值。
- 特征工程:根据领域知识和算法需求,手动或自动地构造新的特征。
- 数据标准化/归一化:通过变换将数据映射到特定范围(如0到1或-1到1),以消除量纲对模型的影响。
二、模型选择与构建
步骤三:选择机器学习算法
根据问题的性质和数据的特性选择合适的机器学习算法。常见的算法包括线性回归、决策树、支持向量机(SVM)、神经网络等。
步骤四:构建模型架构
对于复杂的模型(如深度学习模型),需要设计合适的网络架构。这包括确定层的数量、每层的神经元数量、激活函数的选择等。
方法与关键技术
- 算法选择:基于问题的分类(回归、分类、聚类等)和数据特性(大小、维度、分布等)选择合适的算法。
- 神经网络设计:对于深度学习,设计合适的网络结构是关键。常见的结构包括卷积神经网络(CNN)用于图像处理,循环神经网络(RNN)用于序列数据等。
三、模型训练与优化
步骤五:模型训练
使用训练数据集对模型进行训练。这通常涉及选择一个损失函数和一个优化算法(如梯度下降)来最小化训练过程中的损失。
步骤六:模型评估与优化
使用验证数据集评估模型的性能,并根据评估结果进行模型优化。优化可以通过调整模型参数(如学习率、正则化系数等)或改变模型结构来实现。
方法与关键技术
- 损失函数选择:根据问题的性质选择合适的损失函数,如均方误差(MSE)用于回归问题,交叉熵损失用于分类问题。
- 优化算法:使用梯度下降或其变种(如随机梯度下降、Adam等)来优化模型参数。
- 超参数调优:通过网格搜索、随机搜索或贝叶斯优化等方法找到最佳的超参数组合。
- 正则化与防过拟合:使用L1、L2正则化、Dropout等技术来防止模型过拟合。
四、模型部署与监控
步骤七:模型部署
将训练好的模型部署到生产环境中,以便对新的、未见过的数据进行预测。
步骤八:模型监控与维护
监控模型的性能,并定期更新和维护模型以适应数据的变化。这包括定期重新训练模型、收集新的数据、以及监控模型的预测性能等。
方法与关键技术
- 模型部署技术:使用容器化技术(如Docker)和自动化工具(如Kubernetes)来简化模型的部署过程。
- 性能监控:设置关键性能指标(KPIs)来持续监控模型的性能。
- 模型更新策略:根据性能监控的结果和数据的变化情况制定模型更新策略。
五、其他重要问题
数据隐私与安全性
在处理敏感数据时,必须确保数据的隐私和安全性。这可以通过加密、匿名化和访问控制等技术来实现。
可解释性与透明度
机器学习模型的可解释性是一个重要问题。对于某些应用场景(如医疗、金融),模型做出的决策必须能够被人类理解。因此,研究和应用可解释性强的模型(如决策树、逻辑回归)或开发解释性工具是重要的方向。
偏见与公平性
机器学习模型可能会无意中继承其训练数据中的偏见,从而导致不公平的决策。因此,在模型开发过程中考虑公平性、多样性和包容性是非常重要的。
计算效率与资源消耗
训练复杂的机器学习模型可能需要大量的计算资源和时间。因此,优化模型的计算效率、降低资源消耗是一个重要的研究方向。这可以通过使用更高效的算法、硬件加速(如GPU、TPU)以及分布式计算等技术来实现。
结论
搭建一个有效的机器学习模型是一个涉及多个步骤和多种技术的复杂过程。从数据收集到模型部署和维护,每个步骤都需要精心设计和执行。此外,还需要考虑数据隐私、可解释性、公平性以及计算效率等其他重要问题。通过综合应用这些技术和考虑这些问题,可以开发出强大且可靠的机器学习模型来解决实际问题。







