

高通 AI Stack 稳定扩散Demo指南(1)
- 1. 介绍
- 1.1 适用于 Snapdragon 设备的 AI 模型效率工具包模型优化
- 1.1.1 优化 Snapdragon 设备的稳定扩散
1. 介绍
本指南展示了如何准备和优化稳定扩散模型,以便使用 Qualcomm AI Stack 在 Snapdragon 设备上运行。应按顺序遵循(模型优化、模型准备和模型执行)Jupyter 笔记,因为一个笔记的输出将被下一个笔记使用,例如,优化的模型文件用于 AI Engine Direct 模型准备,输出上下文二进制文件是在目标 Snapdragon 设备上执行模型时使用。
笔记
需要下载笔记才能在本地计算机上运行。要下载笔记,请单击下载图标并选择笔记本。

1.1 适用于 Snapdragon 设备的 AI 模型效率工具包模型优化
在本笔记本中,您将学习如何优化 Snapdragon 设备的稳定扩散模型,包括如何使用 AI 模型效率工具包 (AIMET) 应用训练后量化技术来提高量化模型精度。
1.1.1 优化 Snapdragon 设备的稳定扩散
下载

背景
稳定扩散是一种非常流行的基础模型,它是一种文本到图像生成人工智能模型,能够在数十秒内给定任何文本输入创建逼真的图像。Qualcomm AI Research 使用 Qualcomm AI Stack 进行全栈 AI 优化,首次在 Android 智能手机上部署 Stable Diffusion。
稳定扩散使用潜在扩散模型,迭代地应用去噪自动编码器。为了实现计算/内存效率更高的扩散过程,稳定扩散使用预训练的 CLIP 文本编码器、U-Net 和变分自动编码器 (VAE) 模型。稳定扩散模型采用潜在种子和文本提示作为输入。潜在种子用于生成随机潜在像素图像表示。
- 文本编码器将文本提示转换为 U-Net 可以理解的嵌入空间。
- VAE将图像从像素空间压缩到更小维的潜在空间以输入到U-Net模型。
- U-Net 迭代地对随机潜在图像表示进行去噪,同时调节文本嵌入以改进 U-Net 输出的潜在图像表示。
- VAE 解码器通过将表示转换回其原始像素空间形式来生成最终图像。
下图展示了推理过程中稳定扩散的工作原理
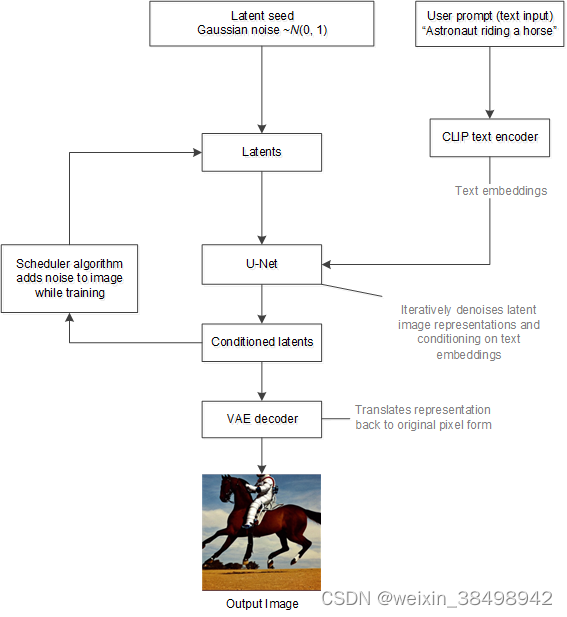
稳定扩散模型将潜在种子和文本提示作为输入。然后,使用潜在种子生成大小为 64×64 的随机潜在图像表示,其中文本提示通过 CLIP 的文本编码器转换为大小为 77×768 的文本嵌入。
接下来,U-Net 在以文本嵌入为条件的同时迭代地对随机潜在图像表示进行去噪。U-Net 的输出是噪声残差,用于通过调度算法计算去噪的潜在图像表示。重复去噪过程约。50 次逐步检索更好的潜在图像表示。一旦完成,潜在图像表示就由变分自动编码器的解码器部分解码。
设置环境
平台要求
该笔记本电脑旨在在具有以下功能的机器上运行:
- 运行 Ubuntu 20.04 的机器
- 相当于 525.60.13 的 NVIDIA 驱动程序版本
安装包依赖项
-
确保您已安装 docker 和 nvidia docker2 运行时:https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html#docker。
-
导航到包含此 jupyter 笔记本的文件夹并启动容器。有关如何下载此笔记本的说明,请参阅https://docs.qualcomm.com/bundle/publicresource/topics/80-64748-1/introduction.html 。
docker run --rm --gpus all --name=aimet-dev-torch-gpu -v P W D : PWD: PWD:PWD -w $PWD -v /etc/localtime:/etc/localtime:ro -v /etc/timezone:/etc/timezone:ro --network=host --ulimit core=-1 --ipc=host --shm-size=8G --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -it artifacts.codelinaro.org/codelinaro-aimet/aimet-dev:latest.torch-gpu
或者,您可以使用以下 Dockerfile 下载并构建 AIMET docker:https://github.com/quic/aimet/blob/develop/Jenkins/Dockerfile.torch-gpu。
-
要安装其他依赖项并启动 jupyter 服务器,请运行 launch.sh 脚本。 ./launch.sh
-
服务器启动后,您将看到 URL,您可以将其复制并粘贴到浏览器中。
-
从 jupyter 主页中选择 stable_diffusion.ipynb。
加载预训练的 FP32 模型
请注意,首次运行时,这些大型模型检查点(5-6GB)将被下载到磁盘上的当前文件夹中。
import torch from redefined_modules.transformers.models.clip.modeling_clip import CLIPTextModel from redefined_modules.diffusers.models.unet_2d_condition import UNet2DConditionModel from redefined_modules.diffusers.models.vae import AutoencoderKLDecoder
cache_dir = "./_data_/cache/huggingface/diffusers" device = 'cuda' dtype = torch.float print("Loading pre-trained TextEncoder model") text_encoder = CLIPTextModel.from_pretrained('openai/clip-vit-large-patch14', torch_dtype=dtype, cache_dir=cache_dir).to(device) text_encoder.config.return_dict = False print("Loading pre-trained UNET model") unet = UNet2DConditionModel.from_pretrained('runwayml/stable-diffusion-v1-5', subfolder="unet", revision='main', torch_dtype=dtype, cache_dir=cache_dir).to(device) unet.config.return_dict = False print("Loading pre-trained VAE model") vae = AutoencoderKLDecoder.from_pretrained('runwayml/stable-diffusion-v1-5', revision='main', subfolder="vae", torch_dtype=dtype, cache_dir=cache_dir).to(device) vae.config.return_dict = False接下来,将模型中的多头注意力(MHA)块展开为单个单头注意力(SHA)块。
from stable_diff_pipeline import run_the_pipeline, save_image, replace_mha_with_sha_blocks replace_mha_with_sha_blocks(unet)
运行浮点计算
通过加载的 FP32 模型运行示例提示并检查生成的图像。
from transformers import CLIPTokenizer from stable_diff_pipeline import run_tokenizer, run_text_encoder, run_diffusion_steps, run_vae_decoder tokenizer = CLIPTokenizer.from_pretrained('openai/clip-vit-large-patch14', cache_dir=cache_dir) prompt = "decorated modern country house interior, 8 k, light reflections" image = run_the_pipeline(prompt, unet, text_encoder, vae, tokenizer, test_name='fp32', seed=1.36477711e+14) save_image(image.squeeze(0), 'generated.png') from IPython.display import Image, display display(Image(filename='generated.png'))预量化优化结果示例

应用 AIMET 量化优化技术
使用 AI 模型效率工具包 (AIMET) 使用混合精度量化方案为文本编码器、U-Net 和 VAE 创建量化仿真模型 (QuantSim)。校准过程用于创建这些 QuantSim 模型,其中使用代表性数据样本确定每层量化编码。QuantSim 模型模拟在量化目标上运行稳定扩散模型。此外,对于文本编码器模型,应用了 AIMET 自适应舍入(AdaRound)技术来提高量化精度。
设置参数位宽为INT8,激活位宽为INT16。
将 AIMET 自适应舍入 (AdaRound) 应用于 TE 模型
为了帮助恢复 TE 模型的量化精度,请应用 AIMET AdaRound 优化技术。AdaRound 执行逐层优化,以学习层权重如何舍入的舍入矩阵。
预计执行时间:19分钟
import json from argparse import Namespace from aimet_quantsim import apply_adaround_te, calibrate_te with open('config.json', 'rt') as f: config = Namespace(**json.load(f)) with open(config.calibration_prompts, "rt") as f: print(f'Loading prompts from {config.calibration_prompts}') prompts = f.readlines() prompts = prompts[:50] tokens = [run_tokenizer(tokenizer, prompt) for prompt in prompts] text_encoder_sim = apply_adaround_te(text_encoder, tokens, config) del text_encoder text_encoder = None校准 TE 模型
我们使用 20 个提示来校准 TE 量化 Sim (QuantSim) 模型。使用更多提示可能有助于提高量化精度,同时校准过程本身也会相应地花费更多时间。
text_encoder_sim = calibrate_te(text_encoder_sim, tokens, config)
校准 UNET 模型
接下来创建 QuantSim 模型并校准 UNET。使用与校准 TE 模型相同的提示来生成用于校准 UNET 模型的嵌入。提示将作为输入馈送到已校准的 TE QuantSim 模型,并且存储生成的嵌入以用作 UNET 的校准数据。
预计执行时间:28分钟
from aimet_quantsim import calibrate_unet embeddings = [(run_text_encoder(text_encoder_sim.model, uncond), run_text_encoder(text_encoder_sim.model, cond)) for cond, uncond in tokens] embeddings = [torch.cat([uncond, cond])for uncond, cond in embeddings] unet_sim = calibrate_unet(unet, embeddings, config)校准 VAE 模型
接下来创建 QuantSim 模型并校准 VAE。上一步中使用的嵌入作为已校准的 UNET QuantSim 模型的输入,并存储生成的潜在变量以用作 VAE 的校准数据。
预计执行时间:18分钟
from aimet_quantsim import calibrate_vae from tqdm.auto import tqdm latents = [run_diffusion_steps(unet_sim.model, i) for i in tqdm(embeddings)] print('Obtained latents using UNET QuantSim') vae_sim = calibrate_vae(vae, latents, config)运行量化脱靶推理
借助 AIMET QuantSim 版本的文本编码器、U-Net 和 VAE 模型,可以使用相同的管道来运行稳定扩散模型的模拟量化推理。传入模型的 sim 版本。管道的其余部分是相同的。
image = run_the_pipeline(prompt, unet_sim.model, text_encoder_sim.model, vae_sim.model, tokenizer, test_name="int8", seed=1.36477711e+14) save_image(image.squeeze(0), 'generated_after_quant.png') display(Image(filename='generated_after_quant.png'))
量化后优化结果示例

导出模型
使用 AIMET 的模型优化已完成。导出模型和相应的量化编码。
预计执行时间:18m
from aimet_quantsim import export_all_models export_all_models(text_encoder_sim, unet_sim, vae_sim, tokens, embeddings, latents)
-
- 1.1.1 优化 Snapdragon 设备的稳定扩散







