

1.背景介绍
1. 背景介绍
语音识别是一种自然语言处理技术,它将人类的语音信号转换为文本,从而实现与计算机的交互。随着人工智能技术的发展,语音识别技术也不断发展,成为了人工智能领域的重要应用。
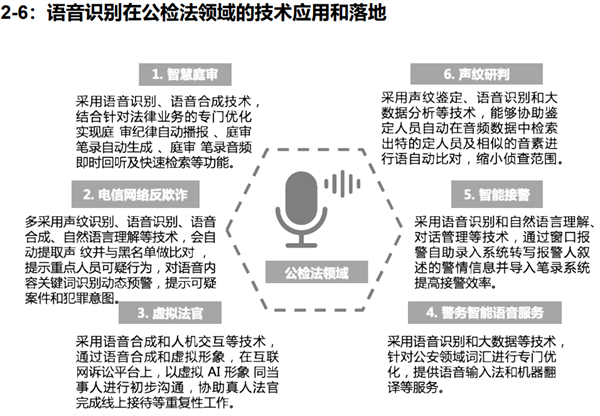
AI大模型在语音识别中的应用,主要体现在以下几个方面:
语音识别精度的提高:AI大模型可以通过深度学习算法,对大量语音数据进行训练,从而提高语音识别的准确性和可靠性。
 (图片来源网络,侵删)
(图片来源网络,侵删)多语言支持:AI大模型可以通过多语言训练数据,实现多语言语音识别,从而更好地满足不同国家和地区的需求。
实时性能:AI大模型可以通过实时计算和优化,实现实时语音识别,从而更好地满足实时交互的需求。
低噪声性能:AI大模型可以通过深度学习算法,对噪音信号进行去噪处理,从而提高语音识别的准确性。
2. 核心概念与联系
在探讨AI大模型在语音识别中的应用之前,我们需要了解一下相关的核心概念:
自然语言处理(NLP):自然语言处理是一种计算机科学技术,它旨在让计算机理解、生成和处理人类自然语言。语音识别是NLP的一个重要子领域。
语音识别模型:语音识别模型是一种用于将语音信号转换为文本的模型。常见的语音识别模型有Hidden Markov Model(HMM)、Deep Neural Network(DNN)、Recurrent Neural Network(RNN)等。
语音特征提取:语音特征提取是将语音信号转换为数字特征的过程。常见的语音特征有MFCC(Mel-Frequency Cepstral Coefficients)、LPCC(Linear Predictive Cepstral Coefficients)等。
语音识别精度:语音识别精度是衡量语音识别系统识别正确率的指标。通常情况下,精度越高,系统性能越好。
3. 核心算法原理和具体操作步骤以及数学模型公式详细讲解
在探讨AI大模型在语音识别中的应用之前,我们需要了解一下相关的核心算法原理和具体操作步骤以及数学模型公式详细讲解:
深度学习算法原理:深度学习算法是一种基于神经网络的机器学习方法,它通过多层神经网络来学习数据的特征,从而实现自主地学习和决策。深度学习算法的核心是神经网络,神经网络由多个神经元组成,每个神经元之间通过权重和偏置连接,形成一个有向无环图。
语音特征提取:语音特征提取是将语音信号转换为数字特征的过程。常见的语音特征有MFCC(Mel-Frequency Cepstral Coefficients)、LPCC(Linear Predictive Cepstral Coefficients)等。MFCC是一种基于滤波器银行的语音特征,它可以捕捉语音信号的时域和频域特征。LPCC是一种基于预测误差的语音特征,它可以捕捉语音信号的时域和频域特征。
语音识别模型:常见的语音识别模型有Hidden Markov Model(HMM)、Deep Neural Network(DNN)、Recurrent Neural Network(RNN)等。HMM是一种基于隐马尔科夫模型的语音识别模型,它可以捕捉语音信号的时域和频域特征。DNN是一种基于深度学习的语音识别模型,它可以捕捉语音信号的时域和频域特征,并通过多层神经网络进行学习和决策。RNN是一种基于递归神经网络的语音识别模型,它可以捕捉语音信号的时域和频域特征,并通过多层递归神经网络进行学习和决策。
语音识别精度:语音识别精度是衡量语音识别系统识别正确率的指标。通常情况下,精度越高,系统性能越好。语音识别精度可以通过以下公式计算:
$$ Precision = \frac{TP}{TP + FP} $$
$$ Recall = \frac{TP}{TP + FN} $$
$$ F1 = 2 \times \frac{Precision \times Recall}{Precision + Recall} $$
其中,TP表示真正例,FP表示假正例,FN表示假阴例。
4. 具体最佳实践:代码实例和详细解释说明
在探讨AI大模型在语音识别中的应用之前,我们需要了解一下相关的具体最佳实践:
数据准备:首先,我们需要准备一些语音数据,这些数据可以来自于公开的语音数据集,如LibriSpeech、Common Voice等。
语音特征提取:接下来,我们需要对语音数据进行特征提取,常见的语音特征有MFCC、LPCC等。
模型训练:接下来,我们需要训练一个语音识别模型,常见的语音识别模型有HMM、DNN、RNN等。
模型评估:最后,我们需要对模型进行评估,从而得到语音识别精度等指标。
以下是一个简单的Python代码实例,展示了如何使用Keras库进行语音识别模型的训练和评估:
```python from keras.models import Sequential from keras.layers import Dense, LSTM, Dropout from keras.utils import to_categorical
准备数据
Xtrain, Xtest, ytrain, ytest = ...
模型训练
model = Sequential() model.add(LSTM(128, inputshape=(Xtrain.shape[1], Xtrain.shape[2]), returnsequences=True)) model.add(Dropout(0.2)) model.add(LSTM(128, returnsequences=True)) model.add(Dropout(0.2)) model.add(LSTM(128)) model.add(Dense(ytrain.shape[1], activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(Xtrain, ytrain, batchsize=64, epochs=10, validationdata=(Xtest, ytest))
模型评估
loss, accuracy = model.evaluate(Xtest, ytest) print('Test loss:', loss) print('Test accuracy:', accuracy) ```
5. 实际应用场景
AI大模型在语音识别中的应用场景非常广泛,主要包括:
智能家居:语音识别技术可以用于智能家居系统,实现与家居设备的交互,例如开关灯、调节温度等。
语音助手:语音识别技术可以用于语音助手系统,实现与用户的自然语言交互,例如查询信息、设置闹钟等。
语音翻译:语音识别技术可以用于语音翻译系统,实现不同语言之间的实时翻译,例如英语翻译成中文等。
语音搜索:语音识别技术可以用于语音搜索系统,实现用户通过语音与搜索引擎进行交互,例如搜索图片、音乐等。
语音游戏:语音识别技术可以用于语音游戏系统,实现与游戏角色的自然语言交互,例如角色对话、任务指令等。
6. 工具和资源推荐
在探讨AI大模型在语音识别中的应用之前,我们需要了解一下相关的工具和资源推荐:
语音数据集:LibriSpeech、Common Voice等公开语音数据集。
深度学习框架:TensorFlow、PyTorch等深度学习框架。
语音处理库:Librosa、SpeechBrain等语音处理库。
语音识别模型:HMM、DNN、RNN等语音识别模型。
语音特征提取:MFCC、LPCC等语音特征提取方法。
语音识别评估指标:Precision、Recall、F1等语音识别评估指标。
7. 总结:未来发展趋势与挑战
AI大模型在语音识别中的应用,已经取得了很大的成功,但仍然存在一些挑战:
语音数据不均衡:语音数据集中的不同类别数据量不均衡,可能导致模型的泛化能力受到影响。
噪声干扰:语音信号中的噪声干扰,可能导致模型的识别精度下降。
多语言支持:目前的语音识别模型在多语言支持方面仍然存在挑战,需要更多的多语言训练数据和模型优化。
未来发展趋势:
语音识别技术将更加精确和实时,从而更好地满足实时交互的需求。
语音识别技术将支持更多的语言,从而更好地满足不同国家和地区的需求。
语音识别技术将更加智能化和个性化,从而更好地满足用户的需求。
8. 附录:常见问题与解答
在探讨AI大模型在语音识别中的应用之前,我们需要了解一下相关的常见问题与解答:
Q1:什么是自然语言处理?
A:自然语言处理(NLP)是一种计算机科学技术,它旨在让计算机理解、生成和处理人类自然语言。
Q2:什么是深度学习?
A:深度学习是一种机器学习方法,它通过多层神经网络来学习数据的特征,从而实现自主地学习和决策。
Q3:什么是语音识别模型?
A:语音识别模型是一种用于将语音信号转换为文本的模型。常见的语音识别模型有Hidden Markov Model(HMM)、Deep Neural Network(DNN)、Recurrent Neural Network(RNN)等。
Q4:什么是语音特征提取?
A:语音特征提取是将语音信号转换为数字特征的过程。常见的语音特征有MFCC(Mel-Frequency Cepstral Coefficients)、LPCC(Linear Predictive Cepstral Coefficients)等。
Q5:什么是语音识别精度?
A:语音识别精度是衡量语音识别系统识别正确率的指标。通常情况下,精度越高,系统性能越好。语音识别精度可以通过以下公式计算:
$$ Precision = \frac{TP}{TP + FP} $$
$$ Recall = \frac{TP}{TP + FN} $$
$$ F1 = 2 \times \frac{Precision \times Recall}{Precision + Recall} $$
其中,TP表示真正例,FP表示假正例,FN表示假阴例。







