

课程学习自 知乎知学堂 https://www.zhihu.com/education/learning
如果侵权,请联系删除,感谢!
文章目录
- 1. LLM 服务维护
- 2. LangSmith
- 2.1 数据集
- 2.2 测试工具
- 2.3 自定义评估指标
- 2.4 文本生成评估方法
- 3. LangFuse
- 3.1 数据集
- 3.2 定义评估函数
- 3.3 定义chain
- 3.4 测试
- 4. Prompt Flow
1. LLM 服务维护
生产级别的LLM服务需要:
- 调试 Prompt
- Prompt 版本管理
- 测试/验证系统的相关指标
- 数据集管理
- 各种指标监控与统计:访问量、响应时长、Token费用等
三个生产级 LLM App 维护平台
- LangSmith: LangChain 的官方平台,SaaS 服务,非开源
- LangFuse: 开源 + SaaS,LangSmith 平替,可集成 LangChain ,对接 OpenAI API
- Prompt Flow:微软开源 + Azure AI云服务,可集成 Semantic Kernel
2. LangSmith
平台入口:https://www.langchain.com/langsmith
注册申请 api key
# 设置环境变量 from dotenv import load_dotenv, find_dotenv _ = load_dotenv(find_dotenv('../utils/.env')) import os os.environ["LANGCHAIN_TRACING_V2"]="true" os.environ["LANGCHAIN_PROJECT"]="agi_demo_hello_world" os.environ["LANGCHAIN_ENDPOINT"]="https://api.smith.langchain.com" # os.environ["LANGCHAIN_API_KEY"]="ls__****"
from langchain.chat_models import ChatOpenAI from langchain.prompts import PromptTemplate from langchain.schema.output_parser import StrOutputParser from langchain.schema.runnable import RunnablePassthrough # 定义语言模型 llm = ChatOpenAI( model="gpt-3.5-turbo", temperature=0, ) # 定义Prompt模板 prompt = PromptTemplate.from_template("鉴赏一下这首诗词: {input}!") # 定义输出解析器 parser = StrOutputParser() chain = ( {"input":RunnablePassthrough()} | prompt | llm | parser ) chain.invoke("静夜思")查看调用记录和中间结果
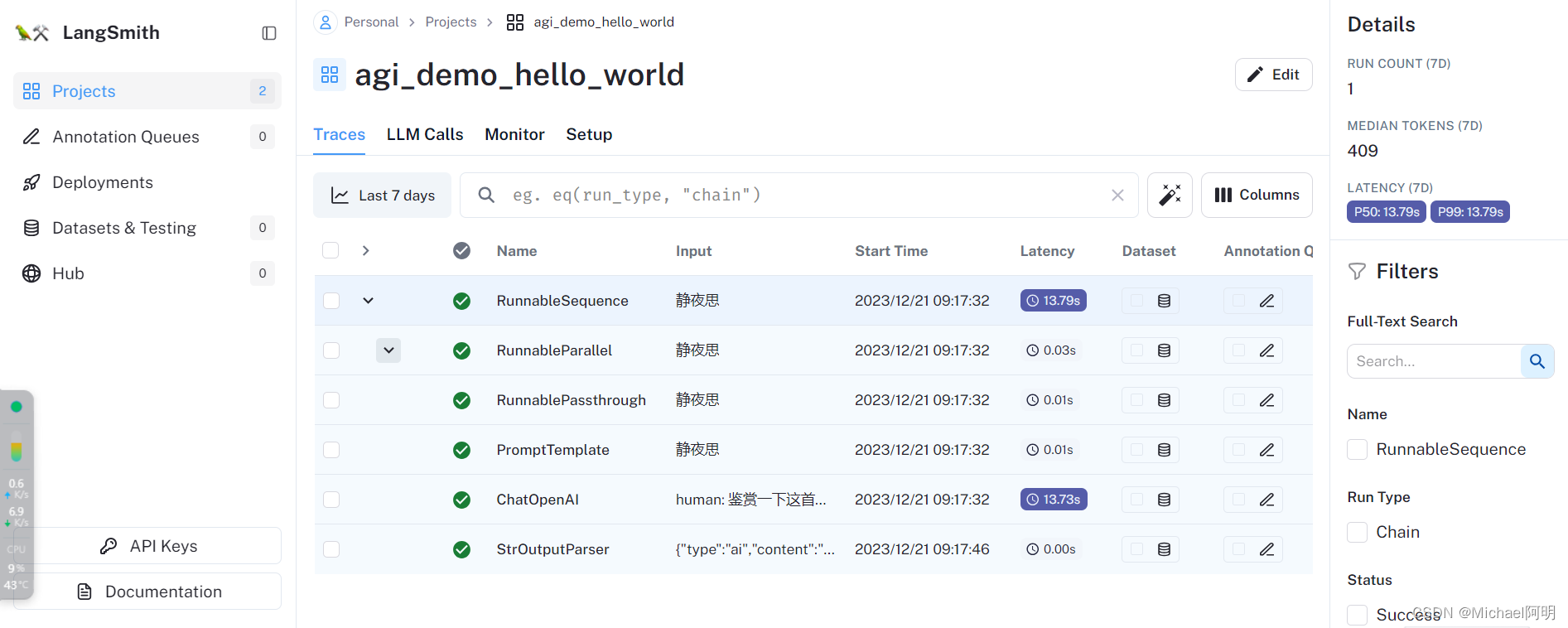
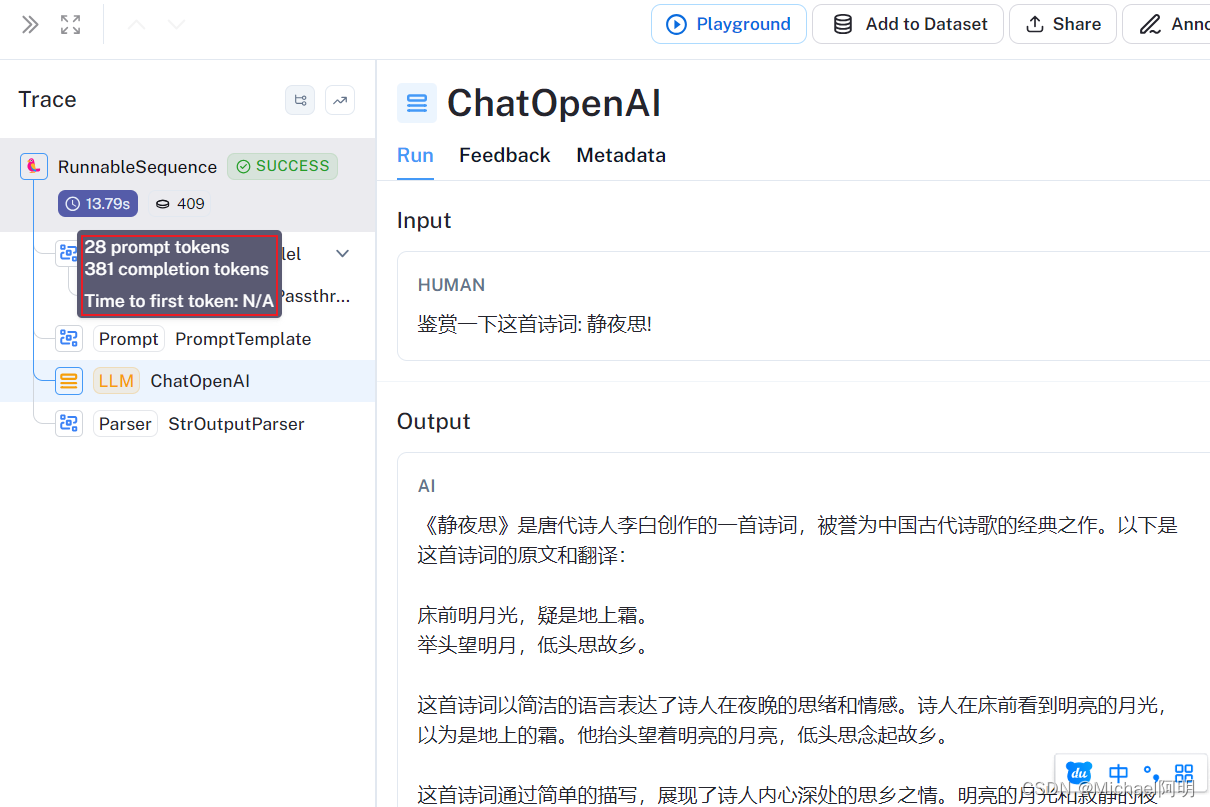
2.1 数据集
使用一个 LLM系统之前,需要系统测试其性能指标
# pip install wikipedia from langchain.retrievers import WikipediaRetriever from langchain.chat_models import ChatOpenAI from langchain.prompts import PromptTemplate from langchain.schema.output_parser import StrOutputParser from langchain.schema.runnable import RunnablePassthrough from operator import itemgetter prompt_template = """ Answer user's question according to the context below. Be brief, answer in no more than 20 words. CONTEXT_START {context} CONTEXT_END USER QUESTION: {input} """ # 检索 wikipedia retriever = WikipediaRetriever(top_k_results=3) def chain_constructor(retriever): # 定义语言模型 llm = ChatOpenAI( model="gpt-3.5-turbo-16k", temperature=0, ) # 定义Prompt模板 prompt = PromptTemplate.from_template( prompt_template ) # 定义输出解析器 parser = StrOutputParser() response_generator = ( prompt | llm | parser ) chain = ( { "context": itemgetter("input") | retriever | (lambda docs: "\n".join([doc.page_content for doc in docs])), "input": itemgetter("input") } | response_generator ) return chain- 准备数据集(输入和输出)

import json qa_pairs = [] with open('example_dataset.jsonl','r',encoding='utf-8') as fp: for line in fp: example = json.loads(line.strip()) qa_pairs.append(example) from langsmith import Client client = Client() dataset_name = "wiki_qa_dataset_demo_100" dataset = client.create_dataset( dataset_name, #数据集名称 description="一个数据集样例,从wiki_qa benchmark中抽取的100条问答对", #数据集描述 ) for example in qa_pairs: client.create_example( inputs={"input": example['question']}, outputs={"output": example['answer']}, dataset_id=dataset.id )执行完,在 郎史密斯 上面就可以看见数据集了
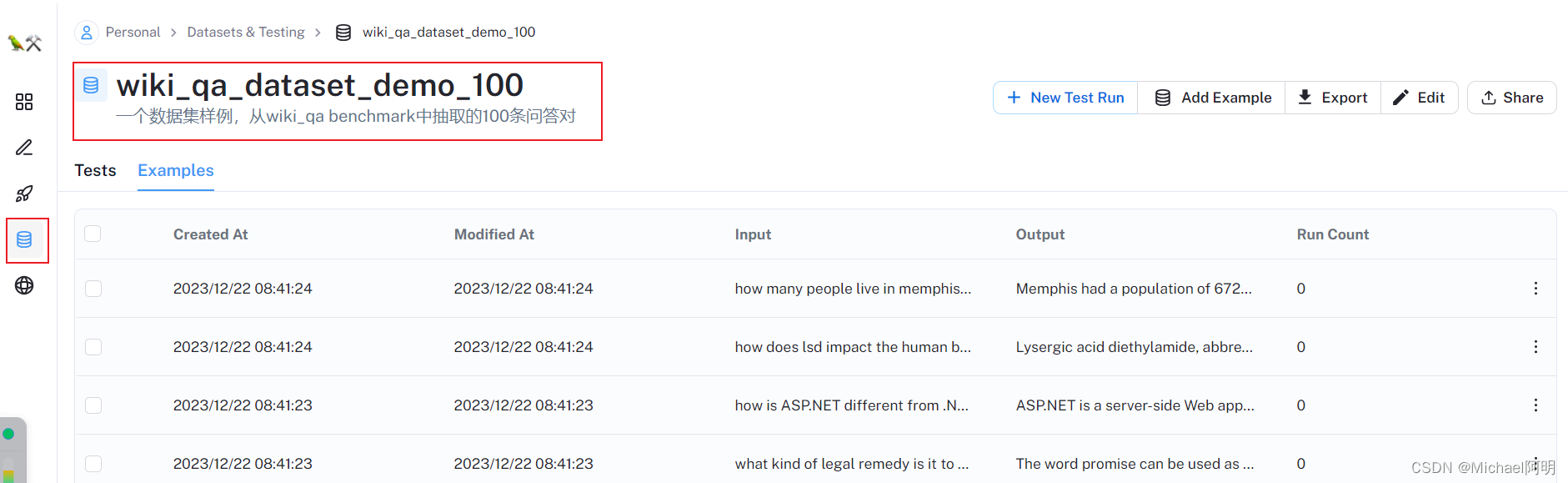
2.2 测试工具
- 定义评估函数,评估输入和输出之间的差距
from langchain.evaluation import EvaluatorType from langchain.smith import RunEvalConfig evaluation_config = RunEvalConfig( # 评估器,可多选 evaluators=[ # 根据答案判断回复是否"Correct" EvaluatorType.QA, ], # 可追加自定评估标准 custom_evaluators=[], )from langchain.smith import ( arun_on_dataset, run_on_dataset, ) from uuid import uuid4 unique_id = uuid4().hex[0:8] chain = chain_constructor(retriever) chain_results = await arun_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=chain, evaluation=evaluation_config, verbose=True, client=client, project_name=f"LangChain_WikiQA_Project-{unique_id}", tags=[ "testing-agiclass-demo", "2023-12-22", ], # 可选,自定义的标识 )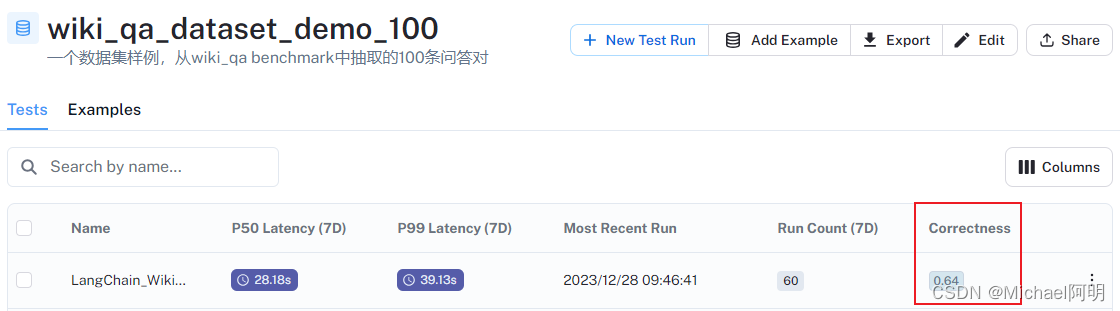
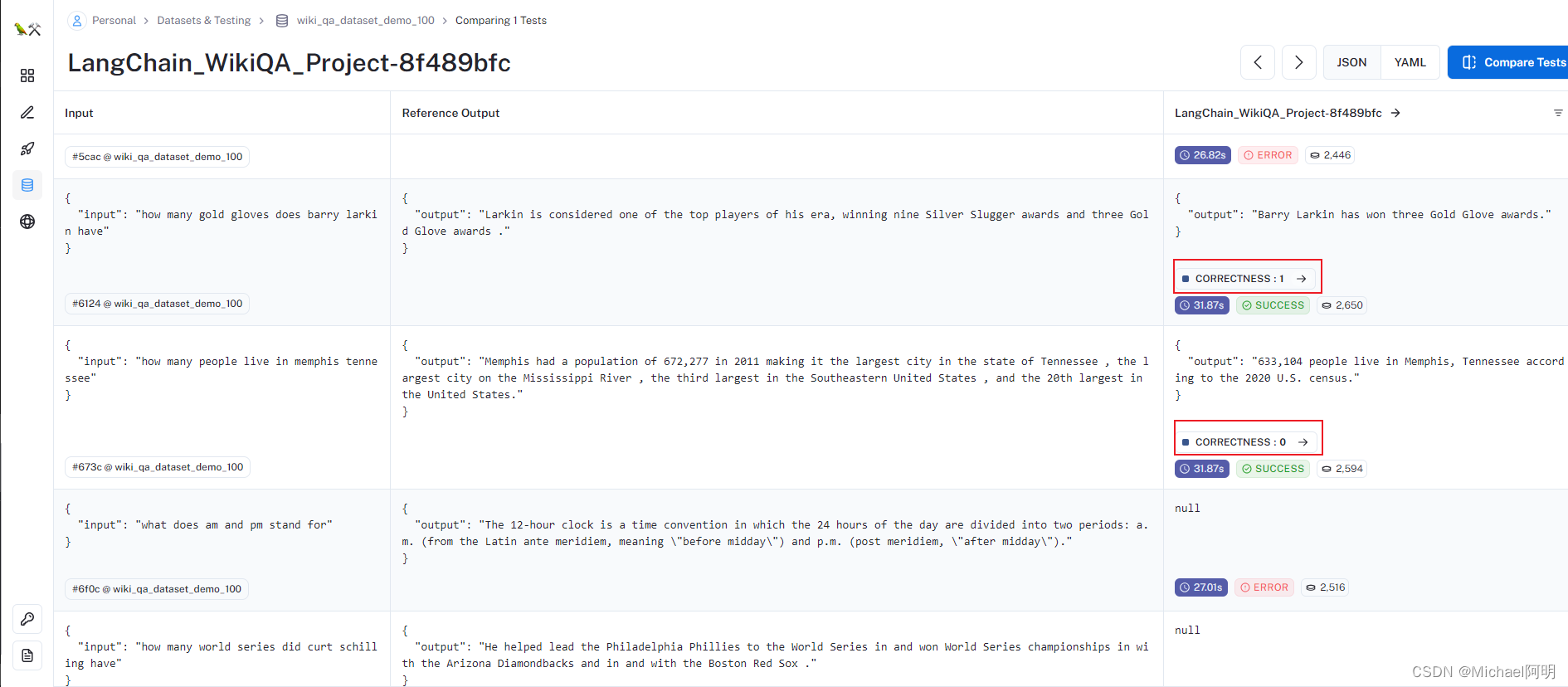
可以看见,有的回答对了,有的错了,还有的运行失败了
2.3 自定义评估指标
from langchain.evaluation import StringEvaluator from nltk.translate.bleu_score import sentence_bleu, SmoothingFunction import re from typing import Optional, Any class BleuEvaluator(StringEvaluator): def __init__(self): pass @property def requires_input(self) -> bool: return False @property def requires_reference(self) -> bool: return True @property def evaluation_name(self) -> str: return "bleu_score" def _tokenize(self,sentence): # 正则表达式定义了要去除的标点符号 return re.sub(r'[^\w\s]', '', sentence.lower()).split() def _evaluate_strings( self, prediction: str, input: Optional[str] = None, reference: Optional[str] = None, **kwargs: Any ) -> dict: bleu_score = sentence_bleu( [self._tokenize(reference)], self._tokenize(prediction), smoothing_function=SmoothingFunction().method3 ) return {"score": bleu_score} from uuid import uuid4 from langchain.smith import ( arun_on_dataset, run_on_dataset, ) evaluation_config = RunEvalConfig( # 自定义的BLEU SCORE评估器 custom_evaluators=[BleuEvaluator()], ) unique_id = uuid4().hex[0:8] chain = chain_constructor(retriever) chain_results = await arun_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=chain, evaluation=evaluation_config, verbose=True, client=client, project_name=f"LangChain_WikiQA_Project-{unique_id}", tags=[ "testing-agiclass-demo", "2023-12-22", ], # 可选,自定义的标识 )"bleu_score" 是一种用于评估自然语言处理中机器生成文本质量的指标,例如翻译和摘要。它衡量机器生成的文本与一组参考文本(如人工翻译)之间的相似性。
BLEU 分数是基于机器生成文本中也出现在参考文本中的 n-gram(给定文本样本中连续 n 项的精度)计算的。它考虑了 1-gram,2-gram,直到 n-gram 的精度,并通过几何平均数将它们组合起来。
此外,为了惩罚短的机器生成文本,BLEU 分数还包括了简洁性惩罚。如果机器生成的文本比参考文本短,BLEU 分数会被按比例降低。
BLEU 分数的范围是 0 到 1
- 越接近 1,机器生成的文本与参考文本越相似,表示机器翻译或文本生成模型的性能越好
2.4 文本生成评估方法
https://docs.smith.langchain.com/evaluation/evaluator-implementations
- 基于大模型做评估
正确性Correctness:给定query,真实的 answer,问大模型,预测的 answer 是否正确
符合标准Criteria:没有参考答案时,判断输出是否符合标准
有帮助Helpfulness:根据参考答案,判断输出是否有帮助
这类方法,对LLM的能力有要求
- 经典测评方法
编辑距离:修改两个句子变成一样,需要的编辑的次数
BLEU Score:
Rouge Score:反应参照句中多少内容被生成的句子包含(召回),函数库 https://pypi.org/project/rouge-score/
METEOR:考虑更多的因素,同义词匹配、词干、次序、短语匹配等
调优的过程中,关注下指标的值是否在变好
3. LangFuse
功能与 LangSmith 基本重合,开源,支持 LangChain 集成或原生 OpenAI API 集成
- 注册:https://cloud.langfuse.com/,创建公钥、密钥
- 或者本地部署:https://github.com/langfuse/langfuse.git
# pip install langfuse from langfuse.callback import CallbackHandler handler = CallbackHandler( os.getenv("LANGFUSE_PUBLIC_KEY"), os.getenv("LANGFUSE_SECRET_KEY") ) from langchain.chat_models import ChatOpenAI from langchain.prompts import PromptTemplate from langchain.schema.output_parser import StrOutputParser from langchain.schema.runnable import RunnablePassthrough from langchain.chat_models import ErnieBotChat from langchain.schema import HumanMessage from langchain.prompts.chat import HumanMessagePromptTemplate from langchain.prompts import ChatPromptTemplate model = ChatOpenAI() prompt = ChatPromptTemplate.from_messages([ HumanMessagePromptTemplate.from_template("{input}!") ]) # 定义输出解析器 parser = StrOutputParser() chain = ( {"input":RunnablePassthrough()} | prompt | model | parser ) chain.invoke("gpt5什么时候发布啊", config={"callbacks":[handler]})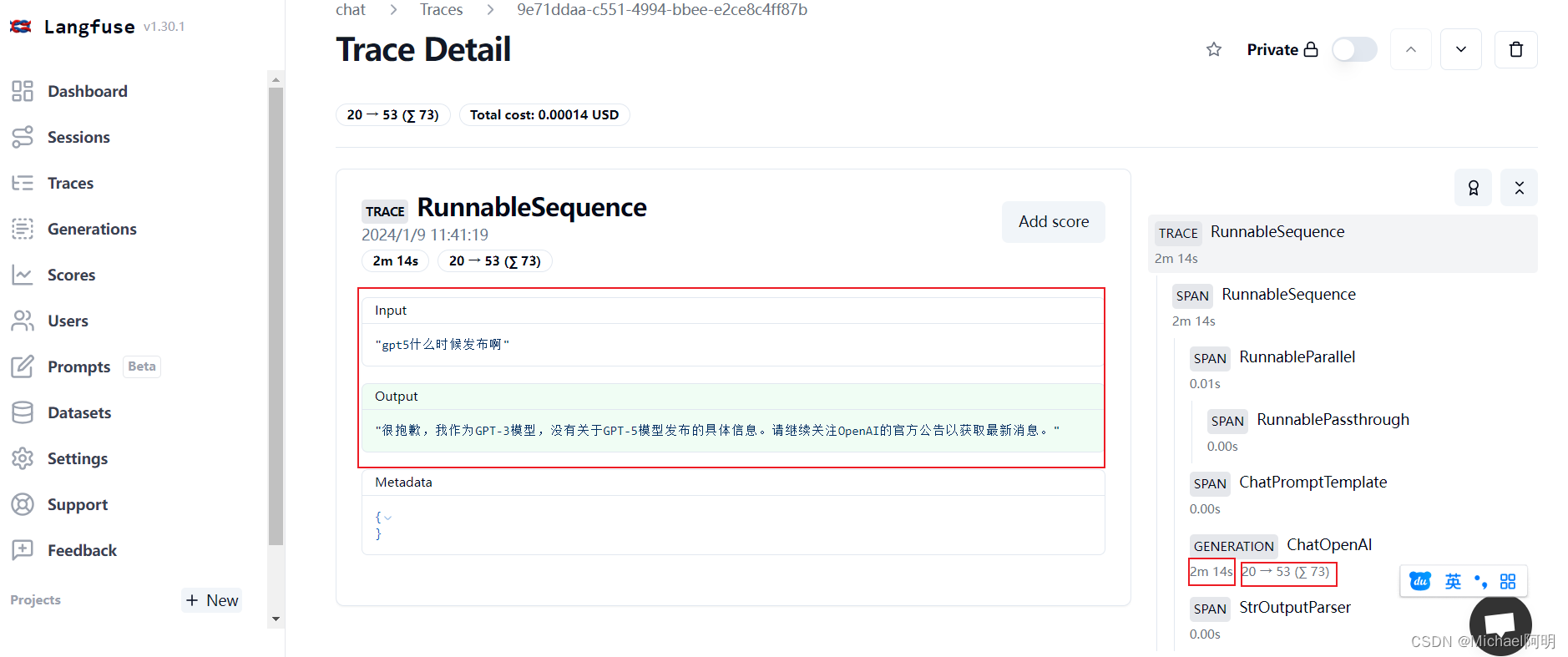
3.1 数据集
import json qa_pairs = [] with open('example_dataset.jsonl','r',encoding='utf-8') as fp: for line in fp: example = json.loads(line.strip()) qa_pairs.append(example) from langfuse import Langfuse from langfuse.model import CreateDatasetRequest, CreateDatasetItemRequest # init langfuse = Langfuse() langfuse.create_dataset(name="wiki_qa-20-2024-01-09") for item in qa_pairs[:20]: langfuse.create_dataset_item( dataset_name="wiki_qa-20-2024-01-09", # any python object or value input=item["question"], # any python object or value, optional expected_output=item["answer"] )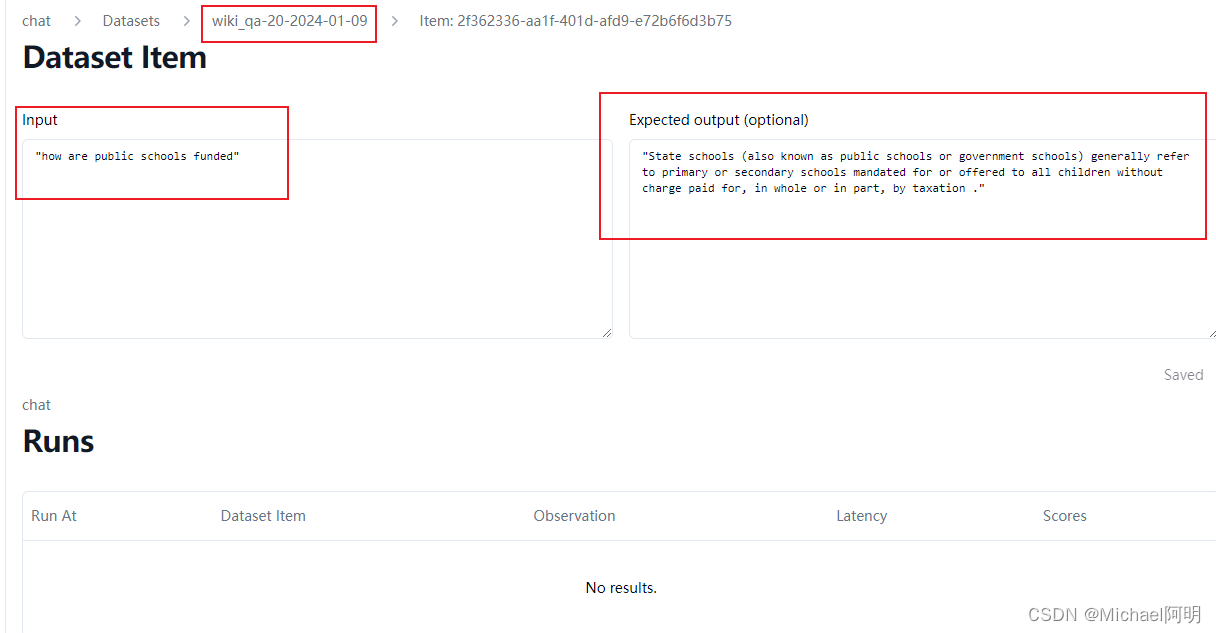
3.2 定义评估函数
from nltk.translate.bleu_score import sentence_bleu, SmoothingFunction import re def bleu_score(output, expected_output): def _tokenize(sentence): # 正则表达式定义了要去除的标点符号 return re.sub(r'[^\w\s]', '', sentence.lower()).split() return sentence_bleu( [_tokenize(expected_output)], _tokenize(output), smoothing_function=SmoothingFunction().method3 )3.3 定义chain
from langchain.retrievers import WikipediaRetriever from langchain.chat_models import ChatOpenAI from langchain.prompts import PromptTemplate from langchain.schema.output_parser import StrOutputParser from langchain.schema.runnable import RunnablePassthrough prompt_template = """ Answer user's question according to the context below. Be brief, answer in no more than 20 words. CONTEXT_START {context} CONTEXT_END USER QUESTION: {input} """ # 定义语言模型 llm = ChatOpenAI( model="gpt-3.5-turbo-16k", temperature=0, ) # 定义Prompt模板 prompt = PromptTemplate.from_template( prompt_template ) # 检索 wikipedia retriever = WikipediaRetriever(top_k_results=1) # 定义输出解析器 parser = StrOutputParser() wiki_qa_chain = ( { "context": retriever, "input": RunnablePassthrough() } | prompt | llm | parser )3.4 测试
https://langfuse.com/docs/datasets#run-experiment-on-a-dataset
from langfuse import Langfuse langfuse = Langfuse() dataset = langfuse.get_dataset("wiki_qa-20-2024-01-09") for item in dataset.items: handler = item.get_langchain_handler(run_name="test_wiki_qa-20") output = wiki_qa_chain.invoke(item.input, config={"callbacks":[handler]}) handler.root_span.score( name="bleu_score", value=bleu_score(output, item.expected_output) )4. Prompt Flow
https://github.com/microsoft/promptflow
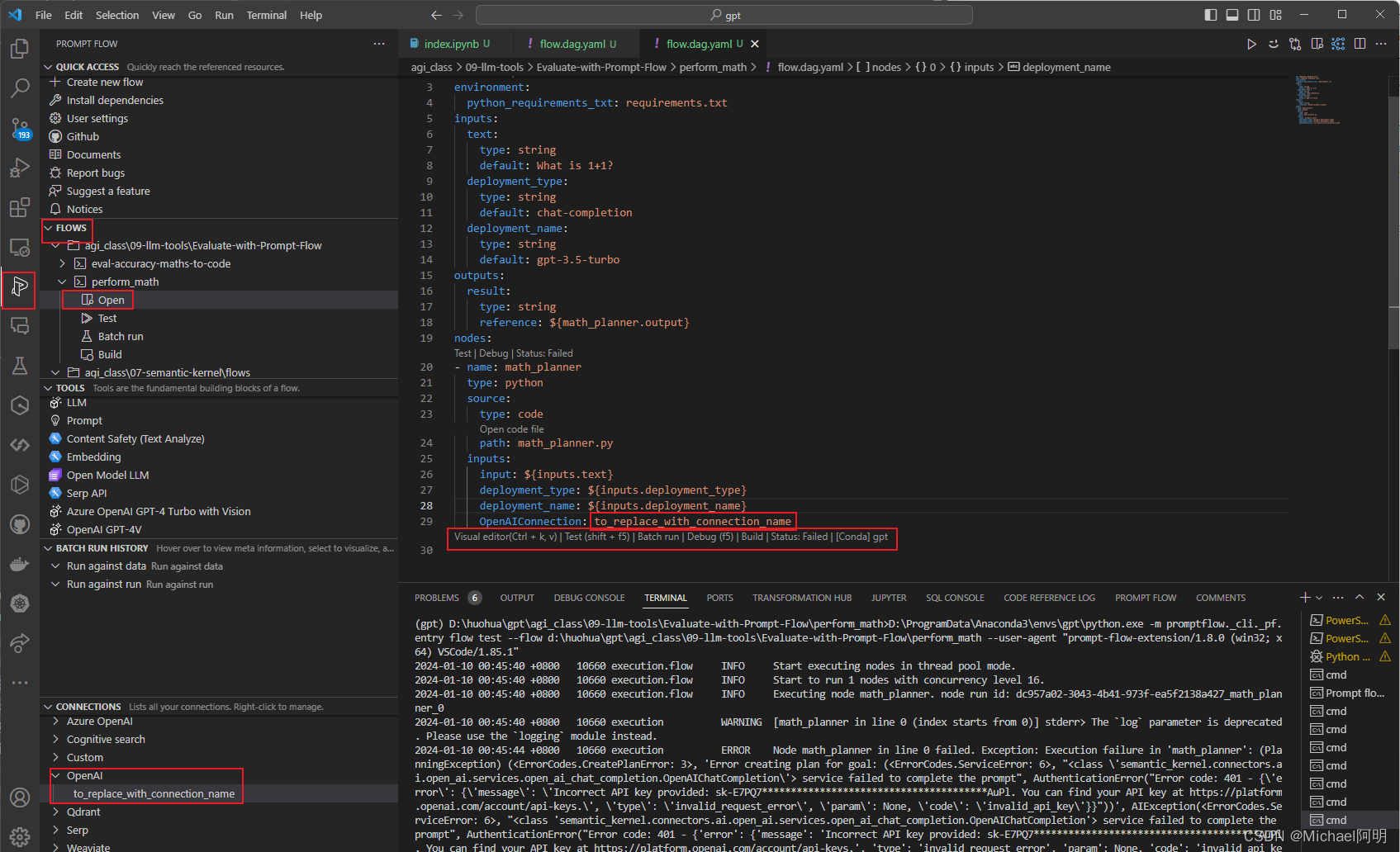
安装 pip install promptflow promptflow-tools
命令行运行 pf flow init --flow ./my_chatbot --type chat
插件

https://microsoft.github.io/promptflow/how-to-guides/quick-start.html
- 经典测评方法
- 基于大模型做评估
- 越接近 1,机器生成的文本与参考文本越相似,表示机器翻译或文本生成模型的性能越好
- 定义评估函数,评估输入和输出之间的差距







