

1.背景介绍
1. 背景介绍
目标检测是计算机视觉领域的一个重要任务,它涉及到识别图像中的物体和场景,并定位这些物体在图像中的位置。随着深度学习技术的发展,目标检测也逐渐向深度学习技术转型。在深度学习领域,目标检测可以分为两个子任务:目标检测和目标分类。目标检测的目的是找出图像中的物体,并确定它们的边界框。目标分类的目的是将物体分为不同的类别。
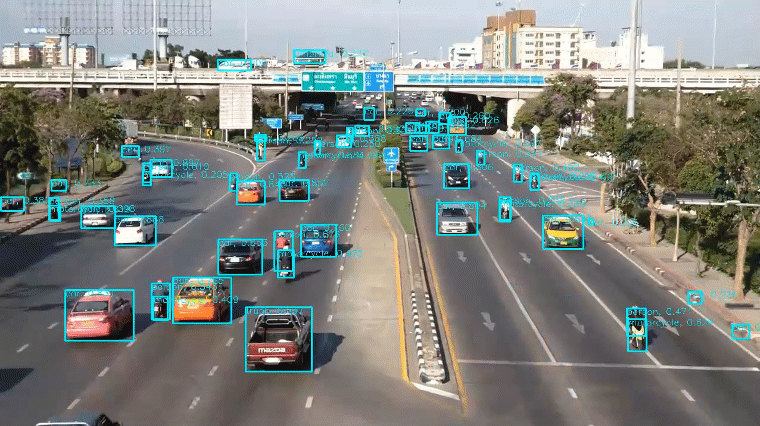
AI大模型在目标检测领域的应用,主要体现在以下几个方面:
- 提高目标检测的准确性和效率:AI大模型可以通过学习大量的训练数据,提高目标检测的准确性和效率。
- 支持多模态的目标检测:AI大模型可以支持多模态的目标检测,例如图像、视频、立体图像等。
- 实现端到端的目标检测:AI大模型可以实现端到端的目标检测,从图像输入到边界框输出,无需额外的人工干预。
2. 核心概念与联系
在目标检测领域,AI大模型主要涉及以下几个核心概念:
 (图片来源网络,侵删)
(图片来源网络,侵删)- 卷积神经网络(CNN):CNN是深度学习领域的一种常用的神经网络结构,它通过卷积、池化和全连接层来提取图像中的特征。
- 目标检测网络:目标检测网络是一种特殊的CNN,它通过预测边界框来实现目标检测。
- 回归和分类:目标检测网络通过回归和分类来实现目标检测。回归用于预测边界框的四个角坐标,分类用于预测物体的类别。
- 非极大值抑制(NMS):NMS是目标检测中的一种常用的后处理方法,它用于消除重叠的边界框。
这些核心概念之间的联系如下:
- CNN是目标检测网络的基础,它用于提取图像中的特征。
- 目标检测网络通过CNN提取的特征,实现回归和分类来实现目标检测。
- NMS是目标检测网络的后处理方法,用于消除重叠的边界框。
3. 核心算法原理和具体操作步骤以及数学模型公式详细讲解
3.1 卷积神经网络(CNN)
CNN是一种深度学习模型,它通过卷积、池化和全连接层来提取图像中的特征。卷积层通过卷积核对图像进行卷积操作,从而提取图像中的特征。池化层通过采样方法对卷积层的输出进行下采样,从而减少参数数量和计算量。全连接层通过权重和偏置对池化层的输出进行线性变换,从而实现特征的分类和回归。
CNN的数学模型公式如下:
$$ y = f(Wx + b) $$
其中,$y$ 是输出,$W$ 是权重,$x$ 是输入,$b$ 是偏置,$f$ 是激活函数。
3.2 目标检测网络
目标检测网络是一种特殊的CNN,它通过预测边界框来实现目标检测。目标检测网络的输入是图像,输出是边界框和分类结果。边界框表示物体在图像中的位置,分类结果表示物体的类别。
目标检测网络的具体操作步骤如下:
- 通过CNN提取图像中的特征。
- 通过全连接层实现回归和分类。
- 通过NMS消除重叠的边界框。
3.3 回归和分类
回归用于预测边界框的四个角坐标,分类用于预测物体的类别。回归和分类的数学模型公式如下:
$$ \begin{aligned} P(x,y,w,h) &= \text{softmax}(Wp[x;y;w;h] + bp) \ R(x,y,w,h) &= Wr[x;y;w;h] + br \end{aligned} $$
其中,$P$ 是分类概率,$R$ 是回归结果,$Wp$ 和 $Wr$ 是分类和回归的权重,$bp$ 和 $br$ 是分类和回归的偏置,$x,y,w,h$ 是边界框的四个角坐标。
3.4 非极大值抑制(NMS)
NMS是目标检测中的一种常用的后处理方法,它用于消除重叠的边界框。NMS的具体操作步骤如下:
- 对所有边界框进行排序,从大到小。
- 从排序后的边界框列表中,逐个选择边界框,并检查与其他边界框是否有重叠。
- 如果有重叠,则将重叠部分的边界框去除,并继续检查其他边界框。
- 重复上述操作,直到所有边界框都检查完毕。
4. 具体最佳实践:代码实例和详细解释说明
4.1 使用PyTorch实现目标检测网络
PyTorch是一个流行的深度学习框架,它支持CNN、RNN、LSTM等深度学习模型。以下是使用PyTorch实现目标检测网络的代码实例:
```python import torch import torch.nn as nn import torch.optim as optim
class Detector(nn.Module): def init(self): super(Detector, self).init() self.conv1 = nn.Conv2d(3, 64, kernelsize=3, stride=1, padding=1) self.conv2 = nn.Conv2d(64, 128, kernelsize=3, stride=2, padding=1) self.conv3 = nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1) self.fc1 = nn.Linear(256 * 8 * 8, 1024) self.fc2 = nn.Linear(1024, 512) self.fc3 = nn.Linear(512, 2)
def forward(self, x): x = nn.functional.relu(self.conv1(x)) x = nn.functional.max_pool2d(x, kernel_size=2, stride=2) x = nn.functional.relu(self.conv2(x)) x = nn.functional.max_pool2d(x, kernel_size=2, stride=2) x = nn.functional.relu(self.conv3(x)) x = nn.functional.max_pool2d(x, kernel_size=2, stride=2) x = x.view(-1, 256 * 8 * 8) x = nn.functional.relu(self.fc1(x)) x = nn.functional.relu(self.fc2(x)) x = self.fc3(x) return xmodel = Detector() criterion = nn.MSELoss() optimizer = optim.Adam(model.parameters(), lr=0.001) ```
4.2 使用PyTorch实现NMS
NMS的PyTorch实现如下:
```python def nms(dets, thresh): idxs = dets[:, 0].argsort(descending=True) keep = [] while len(idxs) > 0: maxidx = idxs[0] keep.append(maxidx) idxs = idxs[1:] for idx in idxs: if dets[idx, 4] > dets[max_idx, 4]: break idxs = idxs[idx+1:] keep = torch.tensor(keep) return dets[keep]
dets = torch.tensor([[1, 100, 100, 200, 0.9, 0.9], [2, 150, 150, 250, 0.8, 0.8], [3, 200, 200, 300, 0.7, 0.7]]) keep = nms(dets, 0.8) print(keep) ```
5. 实际应用场景
AI大模型在目标检测领域的应用场景如下:
- 自动驾驶:目标检测可以用于识别道路上的车辆、行人和障碍物,从而实现自动驾驶系统的安全和准确性。
- 人脸识别:目标检测可以用于识别人脸,从而实现人脸识别系统的准确性和速度。
- 物体识别:目标检测可以用于识别物体,从而实现物体识别系统的准确性和速度。
- 视频分析:目标检测可以用于分析视频中的物体和行为,从而实现视频分析系统的准确性和速度。
6. 工具和资源推荐
7. 总结:未来发展趋势与挑战
AI大模型在目标检测领域的未来发展趋势和挑战如下:
- 模型规模和复杂性的增加:随着数据量和计算能力的增加,AI大模型在目标检测领域的规模和复杂性将会不断增加,从而提高目标检测的准确性和效率。
- 跨模态的目标检测:未来,AI大模型将会支持多模态的目标检测,例如图像、视频、立体图像等。
- 端到端的目标检测:未来,AI大模型将会实现端到端的目标检测,从图像输入到边界框输出,无需额外的人工干预。
- 实时性能的提高:未来,AI大模型将会提高目标检测的实时性能,从而满足实时应用的需求。
- 能源消耗的减少:未来,AI大模型将会减少目标检测的能源消耗,从而减少环境影响。
8. 附录:常见问题与解答
Q: 目标检测和目标分类的区别是什么?
A: 目标检测是识别图像中的物体和场景,并定位这些物体在图像中的位置。目标分类的目的是将物体分为不同的类别。目标检测包括目标检测和目标分类两个子任务。
Q: 为什么AI大模型在目标检测领域的应用如此重要?
A: AI大模型在目标检测领域的应用重要之处在于它可以提高目标检测的准确性和效率,同时支持多模态的目标检测,实现端到端的目标检测,从而满足实时应用的需求。
Q: 未来AI大模型在目标检测领域的发展趋势和挑战是什么?
A: 未来AI大模型在目标检测领域的发展趋势和挑战包括模型规模和复杂性的增加、跨模态的目标检测、端到端的目标检测、实时性能的提高和能源消耗的减少。







