

原書很長,有19.3w字,本文嘗試濃縮一下其中的精華。
知識點
GPT相關
谷歌發布LaMDA、BERT和PaLM-E,PaLM 2
Facebook的母公司Meta推出LLaMA,并在博客上免費公開LLM:OPT-175B。
在GPT中,P代表經過預訓練(pre-trained),T代表Transformer,G代表生成性的(generative)。
基于大模型提供法律咨詢服務的Casetext,利用私域文本嵌入和摘要技術來應對GPT的錯誤信息風險。
ChatPDF:基于大模型的文檔工具,解析PDF,識别内容,理解用戶意圖和需求,提供文本對話、知識問答等服務。
ShareGPT:浏覽器插件産品,用戶可以通過ShareGPT保存并分享自己跟ChatGPT的對話記錄。
Character.ai:神經語言模型聊天機器人網絡應用程序。
ELIZA:1960s年代在麻省理工學院開發的聊天機器人,支持好幾種對話腳本,可以模拟人本主義的心理治療師,跟用戶文本交流。
GPT系列模型用過的數據集:
- 維基百科
- 古登堡計劃(Project Gutenberg),緻力于将文化作品數字化和歸檔,數字圖書館
- ThePile數據集中的Books3數據
- 自助出版平台Smashwords,維護着Toronto BookCorpus與BookCorpus數據集
- ArXiv論文庫
- 美國國家衛生研究院(The National Institutes of Health)數據集
- GitHub
- Reddit:社交媒體平台
- Common Crawl:互聯網爬蟲
- C4,公共網頁數據集,包括各種文章、博客、新聞、論壇等
- Stack Exchange,高質量的問答網站,涵蓋從計算機到化學等各種領域的問題和答案
- 斯坦福問答數據集,The Stanford Question Answering Dataset,簡稱SQuAD。
- 谷歌的自然問答數據集
- TruthfulQA:一個非常容易産生幻覺的數據集,專門用來對幻覺進行測試
-
臨界點:《大語言模型的湧現能力》(Emergent Abilities of Large Language Models)論文說,許多新的能力在中小模型上線性放大規模都得不到線性的增長,模型規模必須要指數級增長超過某個臨界點,新技能才會突飛猛進。量變引發質變。
大模型強調規模定律(Scaling Law),要指數級地加大模型來獲得性能突增和能力湧現
Hallucination:幻覺,指的是生成式AI的胡謅,杜撰,Confabulation。封閉域幻覺是指人類用戶要求大模型僅使用給定背景中提供的信息,但大模型卻創造背景中沒有的額外信息。開放域幻覺是指大模型在沒有參考任何特定輸入背景的情況下,提供關于世界的錯誤信息。
未來人類學習的知識,會有很大一部分源于生成式大模型;大模型生成的内容,存在胡謅和虛假,會對傳統人類知識造成污染。OpenAI曾考慮對人工智能生成内容進行水印标記,但并未找到可行的實施方法。因此,這個關于信任的挑戰必須由人類自己來面對。
英偉達公司推出針對大模型推理的H100 NVL GPU和DGX CLOUD計算集群。
Anyscale:開發Ray并爲OpenAI公司提供框架支持的創業公司,提供SkyPilot,基于多個雲服務商的模型訓練推理計算資源的代理。給定一項計算任務及資源需求(CPU、GPU或TPU),SkyPilot會自動找出哪些位置(區域和雲服務商)具有合适的計算能力,然後将其發送到成本最低的位置執行。
TPU,Tensor Processing Unit,張量處理單元,張量處理器,Google開發的專用集成電路,專門用于加速機器學習。
NPU:神經網絡處理器,Neural Network Processing Unit,用電路模拟人類的神經元和突觸結構。典型代表有國内的寒武紀芯片和IBM的TrueNorth。
PUGC:Professional User Generated Content
PUGM:Professional User Generated Model
其他
BIG-bench,谷歌的一個研究項目,包括有207個測試任務,涵蓋語言學、數學、常識推理、生物學、物理學、軟件開發等領域。
盧德運動:英格蘭中部萊斯特市,織布學徒工内德·盧德(Ned Ludham)在被雇主責罵後失控,拿起錘子砸毀一台紡織機。此後,他被追随者們稱作“盧德王”或“盧德将軍”,盧德運動由此得名。
恩格斯式停頓:Engels’ pause,技術進步初期,收益分配不均;雖然全社會的生産率在不斷上升,但許多人的生活水平仍然停滞不前,甚至不斷惡化。
自動駕駛裏的分級标準,涉及生命安全,對駕駛動作的容錯性極低,分級也非常細緻:
- L1級,輔助駕駛,指車輛可以在一個維度(橫向或縱向)完成部分駕駛任務,例如自适應巡航、車道保持等,但需要人類司機時刻監控和幹預。
- L2級,部分自動駕駛,指車輛可以同時在多個維度(加減速和轉向)完成部分駕駛任務,例如特斯拉的自動輔助駕駛(Autopilot)等,但仍然需要人類司機時刻監控和幹預。
- L3級,有條件自動駕駛,指車輛可以在特定環境中(如高速公路)實現完全自動化的加減速和轉向,無需人類司機幹預,但當遇到複雜或異常情況時(如交通擁堵、事故等),需要人類司機接管控制權。
- L4級,高度自動駕駛,指車輛可以在限定條件下(如地理區域、天氣狀況、速度範圍等)實現完全自動化的行駛,在這些條件下無須人類司機接管或監控。
- L5級,完全自動化或無人化,在任何條件、任何場景下都能夠實現完全自動化的行駛,在任何情況下都不需要人類司機接管或監控。
智能客服領域,可以簡化爲3級:
- L1級,輔助客服,大模型可以在服務過程中的部分環節(如查詢信息、回答常規問題)提供響應,但仍然需要人工客服時刻監控和幹預。類似于自動駕駛中的輔助駕駛或部分自動駕駛。
- L3級,有條件自動客服,大模型在标準的場景中(如普通等級投訴、标準産品銷售)實現完全自動化的服務,無須人工客服幹預,但當遇到複雜或異常情況時(如高等級投訴、申請特殊折扣),需要人工客服接管服務。類似于自動駕駛中的有條件自動駕駛或高度自動駕駛。
- L5級,無人化客服,在任何條件、任何場景下都能夠實現完全自動化的客服,在任何情況下都不需要人工客服接管或監控。類似于自動駕駛中的無人化自動駕駛。
數字遊民通常是指那些通過互聯網和移動設備追尋自由、獨立和靈活的新型職業人群,他們可以在任何地點和時間進行自己的工作。
個人IP則是指個人在社交媒體等平台上,通過内容輸出和品牌塑造來建立自己的個人品牌。
Hugging Face:在線模型庫和社區平台。用戶分爲兩大類,即模型托管者和模型使用者。托管者通常是模型的研究開發方,可以在平台上托管并共享預訓練模型和數據集;模型使用者可以通過平台選擇合适的模型,在社區中進行協作和模型評價,然後将選定的模型投入生産應用,而訓練和推理均可在平台上完成。
Hugging Face是人工智能領域的GitHub。國内類似的有阿裏的ModelScope魔搭社區。
DeepMind:2010年創業公司,2014年被Google收購。發布的AlphaGo Zero,不采用任何人類棋譜作爲訓練數據,僅通過自我對弈完成強化學習,且比之前的所有版本都要強大。DeepMind和Google自家的Brain合并爲Google DeepMind。
Watson Health:IBM投資醫療領域的産物。
Alphabet:谷歌母公司,Waymo也隸屬于Alphabet下,研發自動駕駛汽車。
MaaS:Model as a Service,模型即服務。
聚焦生成式預訓練大模型領域,主要需要關注大模型在以下幾個方面的表現:
- 生成文本的質量:模型生成的文本是否流暢、連貫,是否與輸入強相關、符合人類的預期,是否存在偏見或錯誤信息,可以通過人工評估來衡量。
- 零次遷移的學習能力:模型在沒有接受特定任務訓練的情況下處理相關問題的能力。這反映了模型的泛化能力和靈活性。
- 生成樣本的多樣性:模型生成的文本是否具有多樣性,能否在相同輸入的情況下給出多種合理的回應。這可以通過檢查生成樣本的不同程度來評估。
- 輸入的容錯性和魯棒性:一個好的模型應當能夠處理輸入中的錯誤(如拼寫錯誤、語法錯誤等),并且在面對攻擊或敵對樣本時保持穩定表現。
- 計算資源需求:模型在訓練和推理階段對計算資源(如GPU、内存等)的需求。較小的計算資源需求意味着更高的可擴展性和商業可行性。
- 可解釋性和可審計性:這些特性有助于理解模型的工作原理,以及如何改進模型以減少偏見和錯誤。
技術
GPT
Transformer核心是基于注意力機制的技術,可以建立起輸入和輸出數據的不同組成部分之間的依賴關系,具有質量更優、更強的并行性和訓練時間顯著減少的優勢。
Transformer的基本特征:
- 由編碼組件(encoder)和解碼組件(decoder)兩個部分組成;
- 采用神經網絡處理序列數據,神經網絡被用來将一種類型的數據轉換爲另一種類型的數據,在訓練期間,神經網絡的隐藏層(位于輸入和輸出之間的層)以最能代表輸入數據類型特征的方式調整其參數,并将其映射到輸出;
- 擁有的訓練數據和參數越多,它就越有能力在較長文本序列中保持連貫性和一緻性;
- 标記和嵌入——輸入文本必須經過處理并轉換爲統一格式,然後才能輸入到Transformer;
- 實現并行處理整個序列,從而可以将順序深度學習模型的速度和容量擴展到前所未有的速度;
- 引入注意機制,可以在正向和反向的非常長的文本序列中跟蹤單詞之間的關系,包括自注意力機制(self-attention)和多頭注意力機制(multi-head attention),其中的多頭注意力機制中有多個自注意力機制,可以捕獲單詞之間多種維度上的相關系數注意力評分(attention score),摒棄遞歸和卷積;
- 訓練和反饋——在訓練期間,Transformer提供非常大的配對示例語料庫(例如,英語句子及其相應的法語翻譯),編碼器模塊接收并處理完整的輸入字符串,嘗試建立編碼的注意向量和預期結果之間的映射。
在Transformer之前,有RNN,Recurrent Neural Network,循環神經網絡,或CNN,Convolutional Neural Networks,卷積神經網絡。
大模型的訓練包括三個階段:
- 自監督預訓練(Self-supervised pre-training)
- 監督微調(Supervised Fine Tuning)
- 人類反饋強化學習(RLHF)
RLHF:Reinforcement Learning from Human Feedback,
監督學習:一種經典的機器學習方法,其目标是使用有标簽數據集來訓練一個模型,以使其能夠對新的未标記數據進行預測。訓練數據的标簽是已知的,模型的目标是最小化預測輸出與真實标簽之間的差異,以學習如何進行準确的預測。
微調(Fine-Tuning)的起源可以追溯到早期計算機視覺領域,當時在大型圖像數據集上訓練的CNN被證明能夠捕捉圖像中的高級特征,這些特征在許多視覺任務中都是有用的。
SFT,Supervised Fine-Tuning,監督微調是一種特定的遷移學習方法,不同于傳統從零開始訓練的監督學習。基于一個通用的預訓練模型,使用少量有标簽的數據集對模型進行微調,以适應特定任務的要求。微調方法通常需要更少的标簽數據來實現良好的性能,因爲預先訓練的模型已經學習一些通用的語言表示,可以更好地适應新的任務。微調需要的訓練時間和算力也更少,在微調過程中,預訓練模型的一部分可能會被固定,以避免過度調整和過拟合,隻會改變模型的一小部分層。
自回歸(auto-regressive),在生成每個token時,都會考慮前面已經生成的token,可以保證生成文本的連貫性和語義一緻性。
束搜索(beam search),計算多個概率較高的token候選集,生成多個候選響應,并選擇其中概率最高的響應作爲最終的輸出。
使用溫度(temperature)參數來引入一定程度的随機性,以使生成的響應更加豐富多樣。較大的temperature值會有更多機會選擇非最高概率token,可産生更多樣的響應,但也可能會導緻生成的響應過于随機和不合理;較小的temperature值可以産生更保守和合理的響應,但也可能會導緻生成的響應缺乏多樣性。
大模型标注樣本數據的獲取主要有以下4種手段:
- 通過專業人員進行數據标注。Scale AI公司是OpenAI公司的專業數據标注服務商,支持标注的數據類型包括文本、圖像、音頻、視頻、3D傳感、地圖等。标注業務的商業模式有兩種:按條數收費和按項目收費。
- 搜集用戶使用過程中的反饋
- 獲取公域或三方數據
- 接入企業私域數據
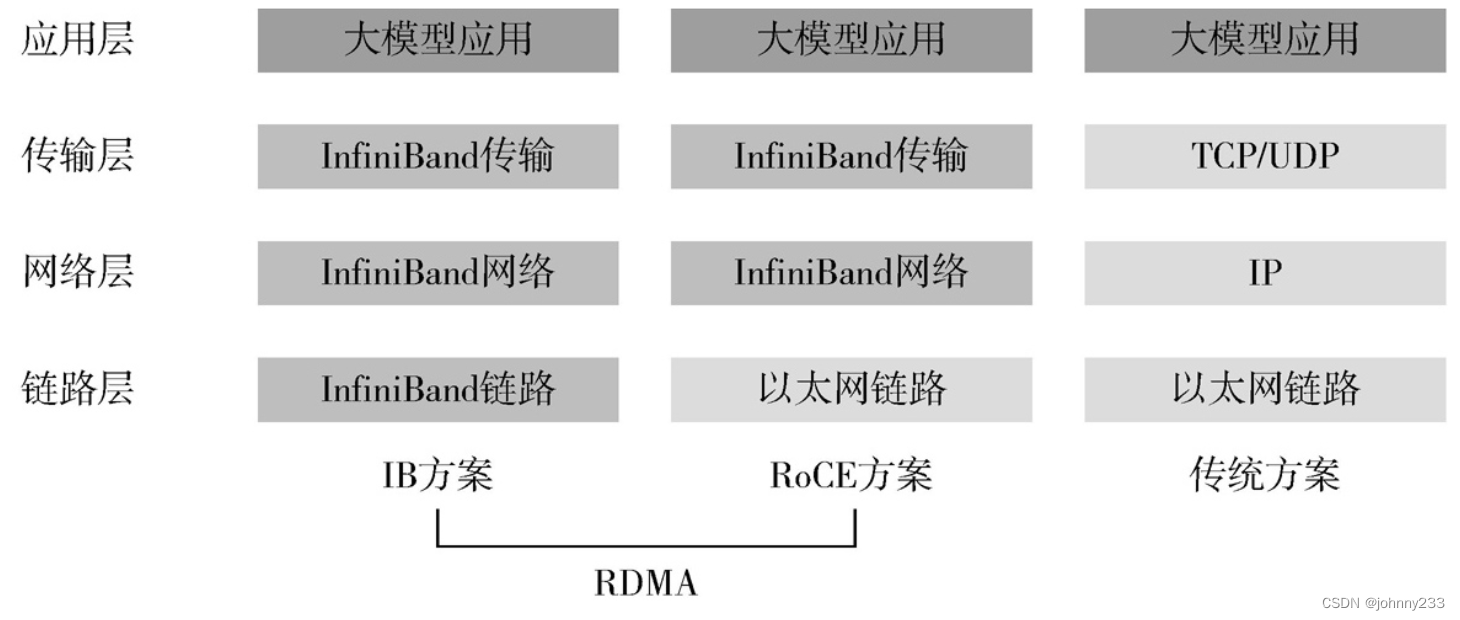
RDMA遠程直接内存訪問(Remote Direct Memory Access),跟傳統以太網和TCP/IP協議相比,RDMA将數據直接從一個GPU節點的内存快速轉移到另一個節點的内存中,繞開雙方操作系統内核和CPU的處理,實現高吞吐、低時延和低資源占用率。
RDMA有兩種典型的技術方案:無限寬帶技術(IB)、基于融合以太網的RDMA(RoCE)。IB方案的鏈路層流控技術可以獲得更高的帶寬利用率,因此能支撐更大規模的訓練集群;但IB方案無法兼容現有以太網,需要更換IB網卡和交換機,部署和運維成本不菲。RoCE,将IB的報文封裝成以太網包進行收發,相比IB在性能上有一些損失。
分布式的深度學習框架便成爲大模型最重要的軟件基礎設施,需要重點解決以下問題:
- 大規模計算:大型語言模型通常包含數十億甚至數百億的參數,這需要大量的計算資源才能進行訓練和推理。分布式深度學習框架可以在多個計算節點和多個GPU或其他***上并行執行任務,從而實現大規模計算。
- 數據、模型和流水線并行:數據并行将允許多個計算設備同時處理不同的數據分片,提高訓練速度。模型并行将模型分布在不同的計算設備上,使得訓練更大的模型成爲可能。流水線并行将模型的計算過程劃分爲多個階段,在不同的計算設備上并行執行,減少通信開銷,提高計算設備的利用率。以上幾種并行策略對于加速大型語言模型的訓練過程至關重要。
- 高效的資源利用:通過任務調度、負載均衡和資源管理等機制,确保計算資源得到高效利用。這有助于降低大型語言模型訓練和推理的時間和成本。
- 容錯和恢複:大型語言模型的訓練時間較長,在訓練過程中出現計算節點和設備故障,無須從頭開始,隻需要容錯和恢複機制,就可以确保訓練可以繼續進行。
如果大模型的需求超過(英偉達黃仁勳提出),隻能靠更大的分布式計算集群來實現,有兩個瓶頸或突破口:
- 雲服務商數據中心的核心網帶寬,要從老的以太網升級到新的标準;
- 軟件方面,深度學習框架要配合。
分布式深度學習框架能力的實現方式有兩種:
- 疊加式:在已有的深度學習框架之上提供分布式能力,如OpenAI在ChatGPT中使用Ray on PyTorch。Ray主要解決分布式計算、任務調度和資源管理等方面,而PyTorch則側重于模型的構建、訓練和優化。英偉達的Nemo Framework、微軟的DeepSpeed等,提供模型并行、數據并行和流水線并行等技術。
- 模型設計和開發:使用PyTorch構建神經網絡模型,定義損失函數、優化器等訓練所需組件。這個階段主要依賴于PyTorch的功能。
- 分布式訓練:使用Ray提供的分布式API,将PyTorch模型在多個節點和多個GPU上進行訓練。Ray負責任務調度、資源管理和容錯,而PyTorch則負責模型參數的更新和優化。
- 數據和模型并行:結合Ray的分布式特性,在PyTorch上實現數據并行(多個設備同時處理不同數據分片)和模型并行(将模型分散到不同的計算設備上)。
- 部署和推理:使用Ray Serve部署PyTorch模型,并提供高性能的在線推理服務。Ray Serve負責模型的擴展和負載均衡,确保推理過程的高效和穩定。
- 全棧式:專爲大模型解決橫向擴展問題的、原生支持分布式并行訓練的深度學習框架,如國人開源框架OneFlow。
- OneFlow以軟硬協同設計爲指導思想,從芯片設計領域借鑒了大量思路,在純軟件層面解決大模型訓練的橫向擴展難題。
- 将自動編排并行模式、靜态調度、流式執行等技術相融合,構建一套原生支持數據并行、模型并行及流水并行等多種模式的分布式深度學習框架,無需定制化開發,兼容多種底層GPU硬件,降低大模型分布式訓練門檻。
- 降低計算集群内部的通信和調度消耗,提高硬件使用率,縮減訓練成本和時間。
BERT
變體:BioBERT、RoBERTa和ALBERT
GPT vs BERT
不同:
- GPT是單向編碼,BERT是雙向編碼。GPT基于Transformer解碼器構建,BERT基于Transformer編碼器構建。這意味着GPT隻能利用左側的上文信息,而BERT可以同時利用左右兩側的上下文信息,可以捕捉更長距離的依賴關系,并且更适合處理一詞多義的情況。
- GPT使用傳統的語言模型作爲預訓練任務,即根據前面的詞預測下一個詞。而BERT使用兩個預訓練任務:掩碼語言模型(MLM),即在輸入中随機遮蓋一些詞,然後根據上下文來還原這些詞;下一句預測(NSP),即給定兩個句子,判斷它們是否有連貫的關系。這兩個任務可以提高BERT對語言結構和語義的理解能力。
- GPT可以應用于自然語言理解(NLU)和自然語言生成(NLG)兩大任務,原生的BERT隻能完成NLU任務,無法直接應用在文本生成上面。因爲GPT采用左到右的解碼器,可以在未完整輸入時預測接下來的詞彙。而BERT沒有解碼器,隻能對輸入進行編碼和預測掩碼位置的詞彙。
其他
傳統的分析型AI是通過訓練數據來學習預測新數據的标簽或值;生成式AI則是通過學習數據的概率分布來生成新的數據。生成式AI的技術:GPT,生成式對抗網絡(GAN)。
GAN,基本思想是同時訓練兩個神經網絡:一個生成器網絡和一個判别器網絡。生成器網絡用于生成假數據,判别器網絡用于區分真實數據和生成的假數據。兩個網絡不斷交替訓練,直到生成器網絡生成的假數據無法被判别器網絡區分真假爲止。已被廣泛應用于圖像、音頻、視頻生成等領域,如圖像生成應用Midjourney就采用GAN技術。
提示(Prompt)工程有3個主要作用:
- 激發模型的潛在知識和能力。
- 使模型理解輸入的問題或任務,提供相關的回答。
- 改進模型的生成輸出,提高可讀性、連貫性和準确性。
在的人工智能三要素當中,大模型産業通過硬件基礎設施層加上分布式框架,重點解決算力要素的問題。
LLaMA,一種基于開放數據集進行自監督預訓練的大模型。主打兩個特色:
- 開放,即可以在非商業許可下提供給政府、開發社區和學術界的研究人員,讓更多機構和個人能參與大模型的研究和探索,實現大模型的民主化;
- 性價比,可以在大數據集的基礎上縮小模型規模,找到模型性能和推理部署成本的最佳平衡。
觀點
21世紀以來,摩爾定律面臨新的生态:功耗、内存、開關功耗極限,以及算力瓶頸等技術節點。摩爾定律逼近物理極限,無法回避量子力學的限制。在摩爾定律之困下,隻有三項選擇:延緩摩爾,擴展摩爾,超越摩爾。
凱文·凱利1994年所著的《失控:機器、社會與經濟的新生物學》,提出群集系統理論:群集系統存在明顯的冗餘問題,且效率相對較低,有不可預測、不可知、不可控的缺點;但也有可适應、可進化、無限性和新穎性的優勢。如蟻群,粒子群,神經網絡等系統,個體随機混亂但是彼此關聯協同形成一個有迹可循的整體。個體的進化,推動整體能力的湧現。
達特茅斯學院的人工智能會議引申出人工智能的三個基本派别:
- 符号學派(Symbolism),又稱邏輯主義、心理學派或計算機學派。該學派主張通過計算機符号操作來模拟人的認知過程和大腦抽象邏輯思維,實現人工智能。符号學派主要集中在人類推理、規劃、知識表示等高級智能領域。
- 聯結學派(Connectionism),又稱仿生學派或生理學派。聯結學派強調對人類大腦的直接模拟,認爲神經網絡和神經網絡間的連接機制和學習算法能夠産生智能。學習和訓練是需要有内容的,數據就是機器學習、訓練的内容。聯結學派的技術性突破包括感知器、人工神經網絡和深度學習。
- 行爲學派(Actionism),該學派的思想來源是進化論和控制論。其原理爲控制論以及感知—動作型控制系統。該學派認爲行爲是個體用于适應環境變化的各種身體反應的組合,其理論目标在于預見和控制行爲。
羅伯特·賴克(Robert Reich)于1991年出版的《國家的工作》(The Work of Nations)一書中,把這個時代的工作分成三類:
- 符号分析師:包括經理人、工程師、金融分析師、律師、科學家、記者、咨詢師等知識工作者。
- 逐漸被計算機接管的常規工作
- 需要人際交流的面對面服務工作
根據布魯姆教育目标分類法(Bloom’s taxonomy of educational objectives),人類對知識的處理(Knowledge Processing)有六個層次:記憶、理解、應用、分析、評價和創造。
《創造力手冊》,法國數學家龐加萊(Poincaré)指出:創造的一種形式,是對有用的關聯元素進行新組合。
《ChatGPT預示着一場智力革命》,大模型将重新定義人類的知識:
- 人類知識的邊界有機會更快速地擴展
- 人類知識處理的範式将發生轉換
- 人類知識處理還将面對範式轉換帶來的嚴峻挑戰
搜商:借助于搜索引擎在互聯網上快速精确搜索想要的信息及獲取知識的能力。
搜索語言:利用雙引号、加号、減号、文件類型、站點範圍等各種限定符,對搜索結果進行更精準的篩選。
阿爾伯特·愛因斯坦說:提出一個問題往往比解決一個問題更重要。
提問題的問題,即所謂問商。在大模型時代,問商更凸顯其價值。
根據人類與大模型之間協作的過程,把問商分爲兩部分:
- 初始階段,3R任務授權法,Ask AI for help。
- 跟進階段,蘇格拉底提問法,Question AI for better result。
3R:
- Role,即角色設定和目的
- Result,即期望的結果
- Recipe,即思考如何才能拿到預期的結果,并給出方法和指導
史蒂芬·R.柯維(Stephen R.Covey)在《高效能人士的七個習慣》一書中,提出任務授權的兩種類型——指令型授權和責任型授權,重點描述和推薦責任型授權的方法。這種授權類型要求雙方就以下五個方面達成清晰、坦誠的共識,并做出承諾:
- 預期成果。要以“結果”,而不是以“方法”爲中心
- 指導方針。确認适用的評估标準,避免成爲指令型授權,但是一定要有明确的限制性規定
- 可用資源
- 責任歸屬
- 明确獎懲
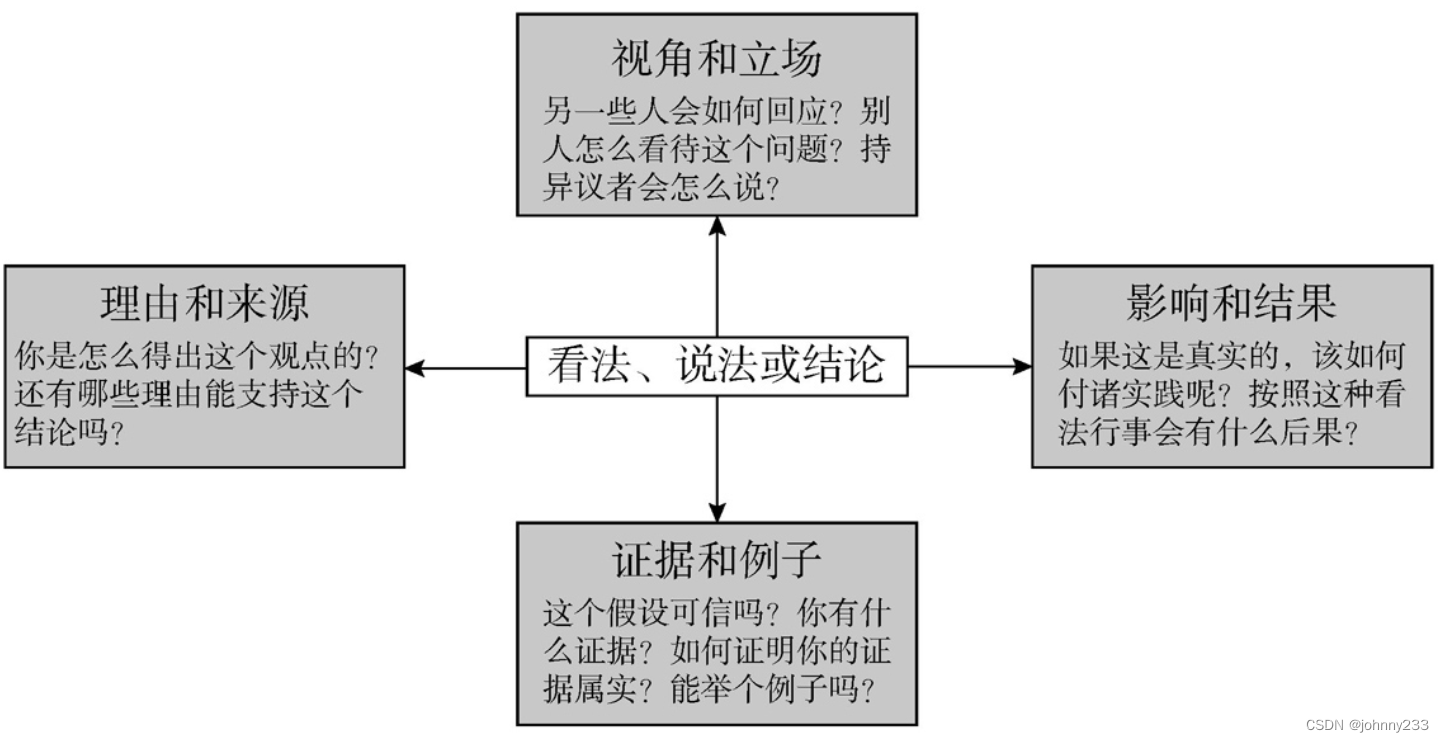
理查德·保羅(Richard Paul)在《像蘇格拉底一樣提問》(The art of Socratic questioning)一書中給蘇格拉底提問法下的定義:提出問題并引導出答案的方法,有如下的一個或多個目的:
- 檢驗理論或觀點是否正确。
- 循循善誘,讓潛藏于腦海中尚未成形的想法成形。
- 引導回答者得出符合邏輯或合理的結論,無論發問者是否已預知該結論。
- 引導對方承認其觀點或結論需要進一步驗證是真是假。
蘇格拉底式的問題,可以分爲4大類:證據類、視角類、理由類、影響類:
GPT大模型滿足通用技術的三個核心标準:随着時間推移,技術不斷改進,貫穿整個經濟體系,能夠催生互補性的創新。
創新者窘境,即成功的公司往往會被自己現有的市場和客戶束縛,而忽視新興的技術和市場的需求,從而導緻被更具創新力和靈活性的新進入者所颠覆。如谷歌在大模型方面落後于OpenAI。
- 疊加式:在已有的深度學習框架之上提供分布式能力,如OpenAI在ChatGPT中使用Ray on PyTorch。Ray主要解決分布式計算、任務調度和資源管理等方面,而PyTorch則側重于模型的構建、訓練和優化。英偉達的Nemo Framework、微軟的DeepSpeed等,提供模型并行、數據并行和流水線并行等技術。








