

目录
前言
设计思路
一、课题背景与意义
二、算法理论原理
2.1 引入双向FPN
2.2 软性非极大值抑制
三、检测的实现
3.1 数据集
3.2 实验环境搭建
3.3 实验及结果分析
实现效果图样例
最后
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是

设计思路
一、课题背景与意义
采摘机器人作为智慧农业的代表,近年来已经从研究阶段进入实验阶段。为解决繁重的农业任务和日益增长的人工成本之间的矛盾,以深度学习和机器人为代表的人工智能(AI)技术正成为新的发展趋势。番茄作为重要的经济作物,研发机器人对新鲜的番茄进行采摘由重要意义。
二、算法理论原理
2.1 引入双向FPN
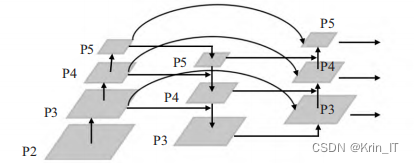
为了更加有效地进行多尺度特征融合,同时考虑到融合时的权重问题,引入了加权双向FPN,通过引入可学习的权重来学习不同输入特征的重要性,同时重复应用自顶向下和自底向上的多尺度特征融合。因为边界节点仅存在一条输入边,并没有进行特征融合,BiFPN移除了这些对结果贡献较小的节点,如果原始的输入节点和输出节点处于同一级别,将增加一条额外的边用于直接将输入和输出进行跨层连接,在控制了计算成本的情况下,实现了更多的特征融合。另外,BiFPN为了实现更加高级的特征融合,将PANet中每个双向的路径视为一个特征层,并多次重复同一层。
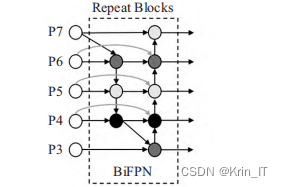
借鉴Weighted-BiFPN结构,对YOLOv5s中的Neck部分进行改进,将原始的FPN的输入和PANet的输出在同一级别上的特征图进行融合,并在融合时考虑到权重问题,通过可学习的权重达到最佳的优化效果。
2.2 软性非极大值抑制
对于与置信度最高的框重叠较为严重的检测框,通过衰减函数进行处理,降低大于重叠阈值的检测框的置信度,而非直接删除。
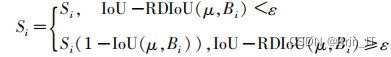
相关代码:
# 定义多尺度特征融合的模块
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1)
self.conv2 = nn.Conv2d(in_channels, out_channels, kernel_size=1)
self.conv3 = nn.Conv2d(in_channels, out_channels, kernel_size=1)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
# 跨层连接,将不同层级的特征进行融合
feat1 = self.relu(self.conv1(x[0]))
feat2 = self.relu(self.conv2(x[1]))
feat3 = self.relu(self.conv3(x[2]))
# 将融合后的特征进行拼接
fused_feat = torch.cat((feat1, feat2, feat3), dim=1)
return fused_feat
三、检测的实现
3.1 数据集
数据集由学长使用相机在蔬菜大棚拍摄采集。采集的图像尺寸为640×640,共1200张,经数据增强扩充至2400张,并按8:2的比例随机划分为训练集和测试集。识别对象为经过基因改良的小型樱桃番茄,该品种色泽鲜艳,坐果率高,且在不同光照环境下特征有所变化。

3.2 实验环境搭建
模型训练的硬件环境配置如下:CPU为Intel® i7 9700K,GPU为Nvidia RTX 2080Ti,内存为64GB的计算机。并在其中安装PyTorch深度学习框架、并行计算框架CUDA 10.02以及配套的深度学习加速计算库CuDNN 7.6.5。每组实验中Batch-size设置为16,训练420个Epochs。
3.3 实验及结果分析
对于YOLOv5s网络结构中的Neck部分,借鉴了BiFPN的思想进行改进,引入了跨层连接,实现了多尺度特征融合。这样可以让模型学习到更多的特征信息,从而提高检测的准确性。采用训练精度Precision和均值平均精度mAP_0.5:0.95作为衡量模型性能的指标。 训练过程各指标变化: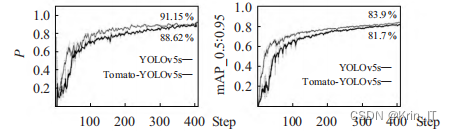
对YOLOv5s中传统的非极大值抑制(NMS)进行了改进,提出了Soft-DIOU-NMS算法。传统的NMS算法在处理重叠的检测框时,会直接删除重叠较严重的框,容易导致漏检。而Soft-DIOU-NMS通过引入衰减函数,对与置信度最高的框重叠较严重的检测框进行处理,降低其置信度而非直接删除,从而有效降低了漏检率。
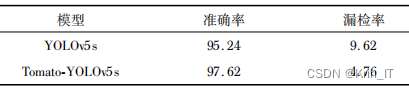
相关代码如下:
# 加载数据集
dataset = torchvision.datasets.VOCDetection(dataset_path, year='2007', image_set='train', download=True, transform=transform)
# 创建数据加载器
batch_size = 32
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 加载预训练的模型
model = faster_rcnn.mobilenet_v2(pretrained=True)
model = model.cuda() # 将模型移动到GPU(如果可用)
# 定义优化器和损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
criterion = torch.nn.CrossEntropyLoss()
# 训练模型
num_epochs = 10
for epoch in range(num_epochs):
for images, targets in dataloader:
images = images.cuda()
targets = [target.cuda() for target in targets]
# 前向传播
outputs = model(images)
loss = criterion(outputs, targets)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}")
# 保存训练好的模型
torch.save(model.state_dict(), 'path_to_save_model.pth')
实现效果图样例

创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!







