

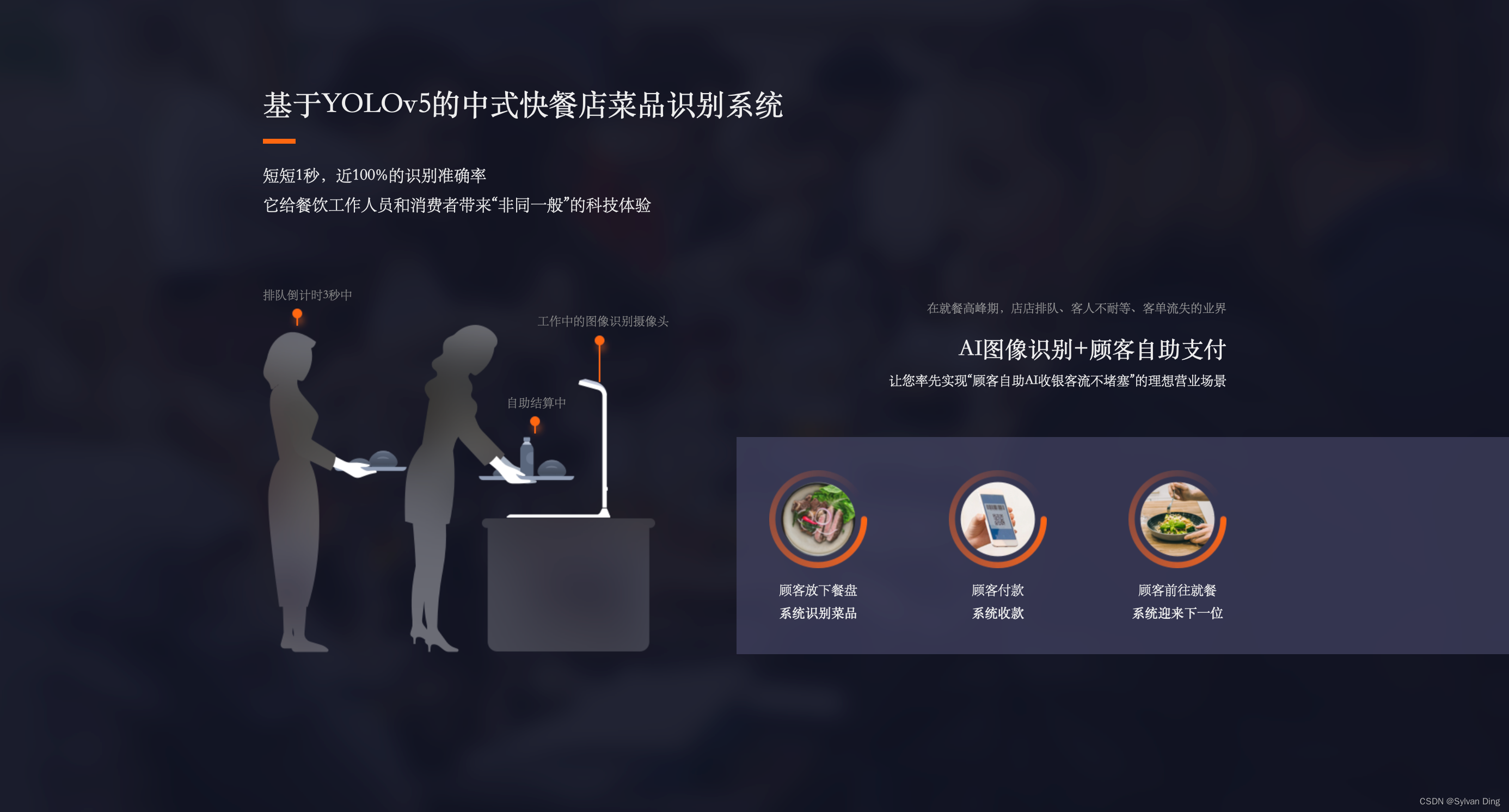
基于YOLOv5的中式快餐店菜品识别系统[金鹰物联智慧食堂项目]
摘要
本文基于YOLOv5v6.1提出了一套适用于中式快餐店的菜品识别自助支付系统,综述了食品识别领域的发展现状,简要介绍了YOLOv5模型的历史背景、发展优势和网络结构。在数据集预处理过程中,通过解析UNIMIB2016,构建了一套行之有效的标签格式转换与校验流程,解决了YOLOv5中文件路径问题、标签格式转换问题和因EXIF信息的存在而导致的标记错位问题。在模型训练阶段,配置了云服务器,引入了Weights and Bias可视化工具,实现了在线监督训练和sweep超参数调优的功能,在sweep中使用hyperband剪枝算法加速了sweep过程,并且给出了对于训练过程中可能出现的问题的解决方法。最后介绍了目标识别领域的评价指标和YOLOv5的损失函数,分析了sweep超参数调优的结果,选取最优参数组合训练模型,通过分析样本分布、PR曲线等,选取最佳预测置信度,大幅提升了预测精度和召回率,部署了模型并制作了客户端。
引言
随着智能信息化时代的到来,人工智能与传感技术取得了巨大进步,在智能交通、智能家居、智能医疗等民生领域产生积极正面影响。其中,社交网络、移动网络和物联网等新兴技术产生了食品大数据,这些大数据与人工智能,尤其是快速发展的深度学习催生了新的交叉研究领域食品计算。现在,在智慧健康、食品智能装备、智慧餐饮、智能零售及智能家居等方面都可以找到食品大数据与人工智能相结合的例子。
人工智能时代下的食品图像识别是当前计算机视觉研究的重要领域之一。我们希望研发一种可快速且高效识别菜品的校园菜肴识别系统,在校园食堂中应用本系统,可缩短收银员计算价格的时间、简化收银步骤;可协助管理者精准备餐、减少库存的浪费;就餐者还可以即时看见摄入的食物营养价值,实现膳食平衡;另外,可迅速实现食品的安全溯源,避免出现食品安全情况。
传统的食物图像识别方法是选择图像特征,然后使用某些方法(比如SIFT、HOG)提取图像特征点,再将特征点用矢量表示,最后采用机器学习的方法训练分类器(如SVM、K-Means)。传统食物图像识别提取特定特征或者关键点对食物进行分类,但在实际应用中,拍摄的图像会受到环境的光照强度、噪声干扰、环境光等外部因素的干扰,导致拍摄图像质量参差,从而影响最终的检测结果同一事物的颜色形状会有差异,不同食物直接的颜色形状也会相同。所以传统的图像识别方法很难准确识别出食物。
深度学习的发展使得当前大部分工作均采用卷积神经网络,思路是先对菜品图像中不同的菜品区域进行检测或分割,然后对其区域进行识别。从2014年开始,基于深度学习的目标检测网络井喷式爆发,先是二阶段网络,如R-CNN、Fast-RCNN、Mask-RCNN等,自2016年Joseph等提出You only Look Once(YOLOv1)以来学者者们的视野,开启了单阶段目标检测网络的新纪元。YOLO均是对单阶段目标检测模型改进的研究,为各研究领域提供了更快、更好的目标检测方法,也为单阶段目标检测算法的实际应用提供了重要理论保障。例如 Aguilar 等人微调物体检测算法 YOLOv2 来进行多种食物检测和识别。又如 Pandey 等人微调了 AlexNet、GoogLeNet、ResNet等三种CNN网络,然后基于微调的网络提取和融合来自不同网络的视觉特征,通过集成学习方法实现菜品图像识别。随着深度学习的发展,卷积神经网络(CNN)在各领域中获得不俗的效果,菜品识别也围绕卷积神经网络展开研究,不仅提出了新的方法,也提升了检测精度。
2020 年 6 月 10 日 YOLOv5 发布,随着版本迭代更新,其已成为现今最先进的目标检测技术之一。YOLOv5 使用Pytorch框架,对用户非常友好,能够方便地训练自己的数据集;能够直接对视频甚至网络摄像头端口输入进行有效推理,有着高达140FPS的目标识别速度;能够轻松的将Pytorch权重文件转化为安卓使用的ONXX格式,或者通过CoreML转化为IOS格式,以便直接部署到手机应用端。
YOLO的核心思想就是将整张图片作为网络的输入,利用“分而治之”的思想,对图片进行网格划分,直接在输出层回归边界框的检测位置及其所属的类别。与Faster R-CNN相比,YOLO产生的背景错误要少得多。通过使用YOLO来消除Faster RCNN的背景检测,可以显着提高模型性能。实验表明YOLO v5可以达到比Faster R-CNN更快的收敛速度,并且在小目标的检测上比SSD模型更加准确。
数据集
数据集来源和说明
本文所使用的托盘食物数据集来源于 UNIMIB2016 Food Database. 此数据集在真实餐厅环境中收集而来,每张照片的尺寸为 (3264, 2448),包含一个托盘和托盘上不同的食物,有些食物放在餐具垫上而非碟子中。有时,多种菜会被放置在同一碟子中,这给图像分割带来了困难。此外,图像畸变和光线环境等影响也会给分割和识别带来挑战。
The dataset has been collected in a real canteen environment. The particularities of this setting are that each image depicts different foods on a tray, and some foods (e.g. fruit, bread and dessert) are placed on the placemats rather than on plates. Sides are often served in the same plate as the main dish making it difficulty to separate the two. Moreover, the acquisition of the images has been performed in a semi-controlled settings so the images present visual distortions as well as illumination changes due to shadows. These characteristics make this dataset challenging requiring both the segmentation of the trays for food localization, and a robust way to deal with multiple foods.


如图3所示,在数据集中,许多类别的食物非常相似,例如,有四种不同的“Pasta al sugo”,其中添加了其他主要成分(如鱼肉、蔬菜或者其他的一些肉类)。最后,托盘上可能有其他物品造成干扰,比如有智能手机、钱包、校园卡等等。
Figure 3, many food classes have a very similar appearance. For example, we have four different “Pasta al sugo”, but with other main ingredients (e.g. fish, vegetables, or meat) added. Finally, on the tray there can be other “noisy” objects that must be ignored during the recognition. For example, we may find cell phones, wallets, id cards, and other personal items. For these reasons we need to design of a very accurate recognition algorithm.

数据集处理
作者团队一共收集了1442张照片,去除模糊和重复照片后,将剩余有效图片保存在UNIMIB2016-images中。其中,包含1027张照片,共计73种菜品,总计3616个菜品实例。一些种类的食物只是在成分上有所不同,所以命名为“FoodName 1”, “FoodName 2”.
接下来,处理UNIMIB2016-annotations.zip中的annotations.mat文件,将其转换为yolo格式。
在UNIMIB2016-annotations中,存有annotations.mat标记文件,.mat文件是Matlab的Map对象(Map object),其介绍如下:
A Map object is a data structure that allows you to retrieve values using a corresponding key. Keys can be real numbers or character vectors. As a result, they provide more flexibility for data access than array indices, which must be positive integers. Values can be scalar or nonscalar arrays.
MAT文件解析
若使用scipy.io.loadmat工具解析.mat文件,如需要加载annotations.mat,在Map object多级嵌套时,解析可能出现意想不到的错误,故编写Matlab脚本将annotations.mat文件解析为YOLOv5所需的标记文件格式。
% .
% ├── annotations.mat
% ├── demo.m
% ├── formatted_annotations
% │ ├── 20151127_114556.txt
% │ ├── 20151127_114946.txt
% │ ├── 20151127_115133.txt
% │ ├── ...
% │ └── 20151221_135642.txt
% └── load_annotations.m
%% load_annotations.m
clc; clear;
% output path
output = './formatted_annotations/';
% Load the annotations in a map structure
load('annotations.mat');
% Each entry in the map corresponds to the annotations of an image.
% Each entry contains many cell tuples as annotated food
% A tuple is composed of 8 cells with the annotated:
% - (1) item category (food for all tuples)
% - (2) item class (e.g. pasta, patate, ...)
% - (3) item name
% - (4) boundary type (polygonal for all tuples)
% - (5) item's boundary points [x1,y1,x2,y2,...,xn,yn]
% - (6) item's bounding box [x1,y1,x2,y2,x3,y3,x4,y4]
image_names = annotations.keys;
n_images = numel(image_names);
for j = 1 : n_images
image_name = image_names{j};
tuples = annotations(image_name);
count = size(tuples,1);
coordinate_mat = cell2mat(tuples(:,6));
% open file
file_path = [output image_name '.txt'];
ffile = fopen(file_path, 'w');
% write file
for k = 1 : count
item = tuples(k,:);
fprintf(ffile, '%s %d %d %d %d %d %d %d %d\n', ...
string(item(2)), ... % item class
coordinate_mat(k,:)); % item's bounding box
end
% close file
fclose(ffile);
end
%% fprintf
% Write data to text file
% https://www.mathworks.com/help/matlab/ref/fprintf.html
运行上述Matlab脚本文件,在./formatted_annotations文件夹下生成以图片名命名的*.txt文件,每一行的格式为class x1 y1 x2 y2 x3 y3 x4 y4.

bounding box如图所示:(xy1左上,xy3右下)

数据集有效性检验
下载并解压 [UNIMIB2016-images.zip],./original文件夹内为所有图片数据。将 original文件夹重命名为images,今后该文件夹用来存放图片数据,否则YOLOv5模型训练会发生错误,具体原因请看 一文彻底解决YOLOv5训练找不到标签问题。编写check_dataset.py,检查formatted_annotations中标签文件是否和images中图像文件一一对应,删除无效的标签和不匹配的标签。
# UNIMIB2016
# ├── UNIMIB2016-annotations
# │ ├── check_dataset.py 9:
print('wrong label format: {}, {}'.format(annotation, line))
raise FileExistsError
except FileExistsError:
os.remove(label_path)
print('os.remove({})'.format(label_path))
if __name__ == '__main__':
check_dataset()
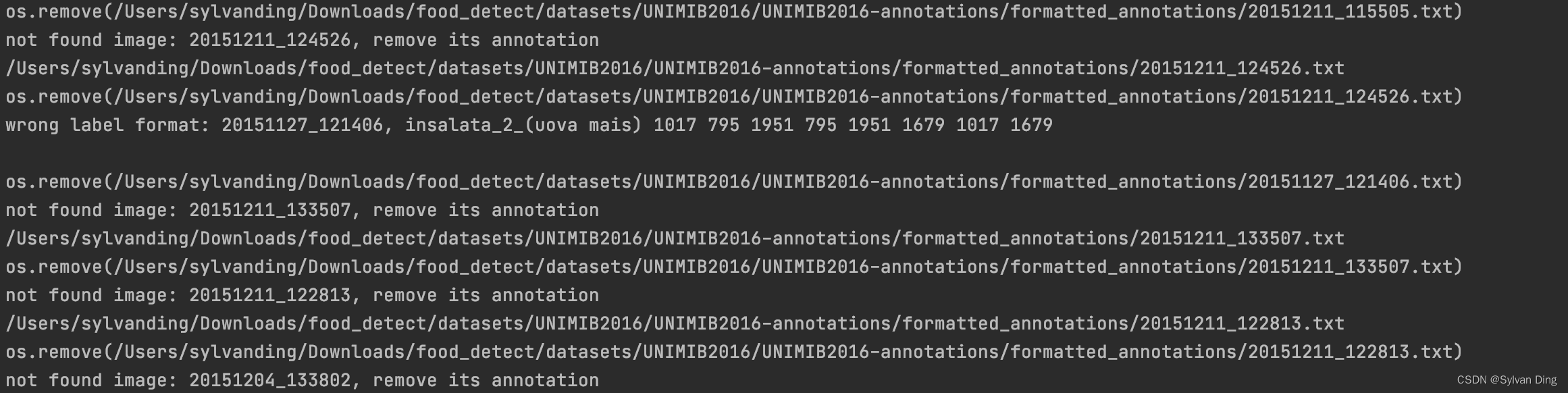
部分输出如下,check_dataset.py检查出21份在images中找不到对应图片的*.txt标记文件,检查出1份在类别标签中含有空格的*.txt标记文件,剔除这22份无效标记文件后,formatted_annotations中还剩余1005份有效标记文件。
食物类别统计
编写class_count.py,生成formatted_annotations中所有食品种类的统计数据:
# UNIMIB2016 # ├── UNIMIB2016-annotations # │ ├── check_dataset.py # │ ├── class_count.py







