

AI预测相关目录
AI预测流程,包括ETL、算法策略、算法模型、模型评估、可视化等相关内容
最好有基础的python算法预测经验
- EEMD策略及踩坑
- VMD-CNN-LSTM时序预测
- 对双向LSTM等模型添加自注意力机制
- K折叠交叉验证
- optuna超参数优化框架
- 多任务学习-模型融合策略
- Transformer模型及Paddle实现
- 迁移学习在预测任务上的tensoflow2.0实现
- holt提取时序序列特征
- TCN时序预测及tf实现
- 注意力机制/多头注意力机制及其tensorflow实现
文章目录
- AI预测相关目录
- 一、注意力机制
- 二、代码示例
- 总结
一、注意力机制
《AI-预测-对双向LSTM等模型添加自注意力机制》一文中曾提到过自注意力机制,实际上注意力机制的有关内容原不仅这一点。
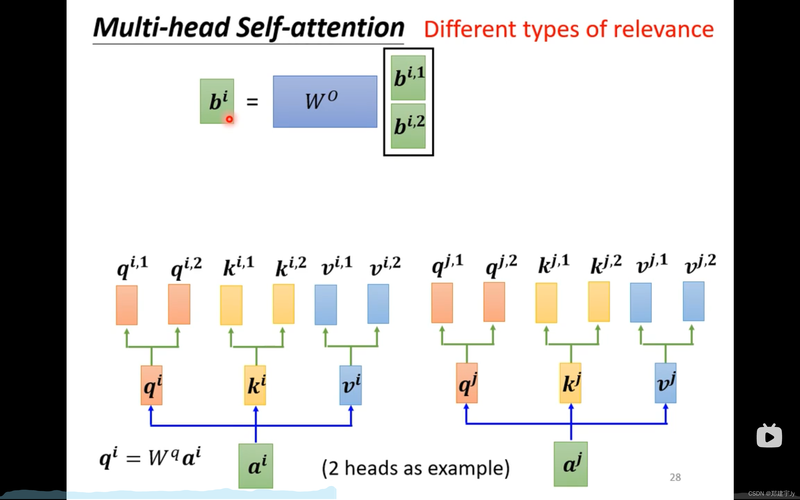
 (图片来源网络,侵删)
(图片来源网络,侵删)本次将分享注意力机制/多头注意力机制及其tensorflow实现。
注意力机制(Attention Mechanism)是一种让模型关注输入数据中重要部分,忽略不重要部分的方法。它通过赋予输入数据不同的权重,来决定每个部分对最终输出的贡献。注意力机制可以看作是一种特殊的加权平均,权重是通过模型学习得到的,代表了输入数据各部分的重要性。
多头注意力机制(Multi-Head Attention Mechanism)是注意力机制的一种扩展形式。在多头注意力机制中,模型同时关注输入数据的不同部分,并从多个角度或层面来处理这些信息。每个“头”可以看作是一个独立的注意力机制,对输入数据的不同部分进行加权处理。通过这种方式,多头注意力机制可以更全面地理解输入数据,并从中提取更丰富的语义信息。
多头注意力机制的优点包括:
1.捕获输入数据的不同方面:由于有多个注意力头,模型可以从不同的角度或层面来理解输入数据,从而更全面地捕获其语义信息。
2.增强模型的表示能力:多头注意力机制使得模型可以学习到更多的特征表示,从而在各种自然语言处理任务中取得更好的性能。
3.提高模型的泛化能力:由于多头注意力机制可以从多个角度来理解输入数据,因此它可以更好地泛化到新的任务和数据集上。
然而,多头注意力机制也有一些缺点:
1.计算复杂度高:由于有多个注意力头,每个头都需要计算其权重矩阵等参数,因此计算复杂度相对较高。
2.参数数量多:多头注意力机制中的参数数量相对较多,这可能会导致模型训练时过拟合的问题。
二、代码示例
注意力机制定义
def attention_function(inputs, single_attention_vector=False): # 定义 attention_function 函数,接受输入 inputs 和单一注意力向量标志 single_attention_vector TimeSteps = K.int_shape(inputs)[1] # 获取 inputs 的时间步数(序列长度) input_dim = K.int_shape(inputs)[2] # 获取 inputs 的特征维度 a = Permute((2, 1))(inputs) # 将 inputs 的维度进行转置,维度顺序变为 (特征维度, 时间步维度) a = Dense(TimeSteps, activation='softmax')(a) # 经过全连接层,输出维度为 (特征维度, 时间步维度),并使用 softmax 激活函数 if single_attention_vector: a = Lambda(lambda x: K.mean(x, axis=1))(a) # 如果 single_attention_vector 为 True,则对第二个维度进行求平均,得到单一注意力向量 a = RepeatVector(input_dim)(a) # 将单一注意力向量进行复制,使其与 inputs 的维度一致 a_probs = Permute((2, 1))(a) # 再次将注意力权重进行转置,维度顺序变为 (时间步维度, 特征维度) output_attention_mul = Multiply()([inputs, a_probs]) # 使用 Multiply 层将 inputs 和注意力权重进行元素级乘法操作 return output_attention_mul # 返回经过注意力机制处理后的结果 output_attention_mul注意力机制使用
model = Sequential() # 创建Sequential模型 inputs = Input(shape=(look_back, 1)) # 定义输入层,shape为(look_back, 1) LSTM_out = LSTM(neurons, return_sequences=True, activation="tanh")(inputs) # 创建LSTM层,返回序列,并使用tanh激活函数 Batch_Normalization = BatchNormalization()(LSTM_out) # 批量归一化层 Drop_out = Dropout(dropout)(Batch_Normalization) # Dropout层,根据给定的dropout率进行随机失活 attention = attention_function(Drop_out) # 注意力层,根据Drop_out进行注意力计算 Batch_Normalization = BatchNormalization()(attention) # 批量归一化层 Drop_out = Dropout(dropout)(Batch_Normalization) # Dropout层 Flatten_ = Flatten()(Drop_out) # 展平层 output = Dropout(dropout)(Flatten_) # Dropout层 output = Dense(1, activation='sigmoid')(output) # 全连接层,输出维度为1,激活函数为sigmoid model = Model(inputs=[inputs], outputs=output) # 创建模型,指定输入和输出 model.compile(loss='mean_squared_error', optimizer='adam') # 编译模型,使用均方误差损失函数和adam优化器
多头注意力机制定义
class MultiHeadAttention(tf.keras.layers.Layer): def __init__(self, input_units, head_units, transform_units, **kargs): super().__init__() self.head_units = head_units self.dense_q = TimeDistributed(Dense(transform_units * head_units)) self.dense_k = TimeDistributed(Dense(transform_units * head_units)) self.dense_v = TimeDistributed(Dense(transform_units * head_units)) self.attention = Attention(**kargs) self.dense_output = TimeDistributed(Dense(input_units)) def _split_and_concat(self, x): return K.concatenate(tf.split(x, self.head_units, axis=-1), axis=0) def _call_(self, q, v, q_mask, v_mask): print(q, v, q_mask, v_mask) k = v q_transform = self._split_and_concat(self.dense_q(q)) v_transform = self._split_and_concat(self.dense_v(v)) k_transform = self._split_and_concat(self.dense_k(k)) head_concat = K.concatenate( tf.split( self.attention( [q_transform, v_transform, k_transform], mask=[ K.tile(q_mask, [self.head_units, 1]), K.tile(v_mask, [self.head_units, 1]) ] ), self.head_units, axis=0 ), axis=-1 ) return self.dense_output(head_concat)多头注意力机制使用与类似
总结
完结,撒花!







