

1. 背景介绍
1.1 电商B侧运营的挑战与机遇
随着电子商务的迅速发展,越来越多的企业开始将业务拓展到线上,电商平台的竞争也愈发激烈。在这个过程中,电商B侧运营成为了企业获取竞争优势的关键。然而,面对海量的用户数据和复杂的用户行为,如何精准地把握用户需求,提高用户体验,从而提升运营效果,成为了电商B侧运营面临的重要挑战。
1.2 AI技术在电商B侧运营的价值
人工智能(AI)技术的发展为电商B侧运营带来了新的机遇。通过运用AI技术,企业可以更加精准地分析用户数据,构建用户画像,从而实现个性化推荐、精准营销等,提高运营效果。本文将重点介绍AI大语言模型在电商B侧运营中的用户画像构建与应用。
2. 核心概念与联系
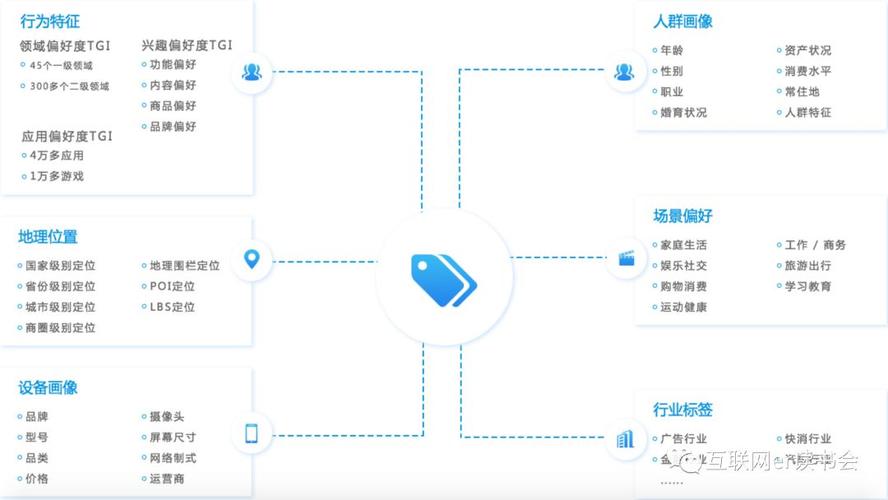
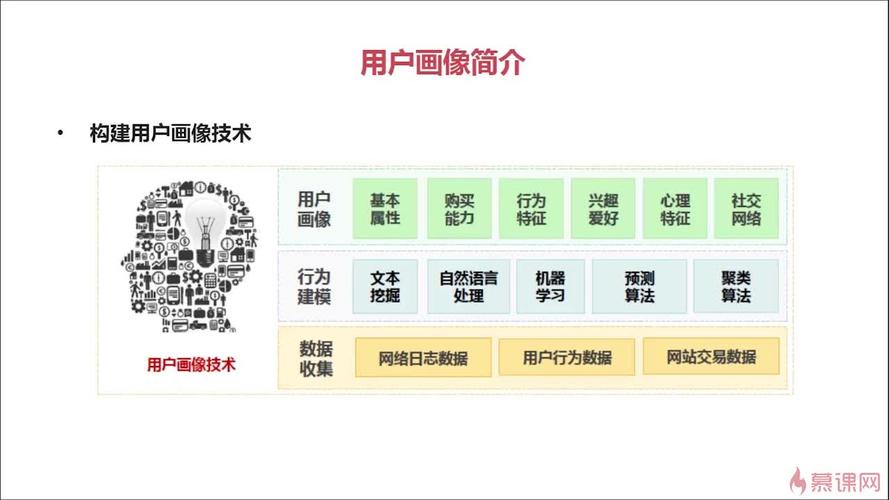
2.1 用户画像
用户画像是对用户的一种抽象描述,包括用户的基本信息、兴趣爱好、消费习惯等多维度特征。通过构建用户画像,企业可以更好地了解用户需求,实现精准营销。
2.2 AI大语言模型
AI大语言模型是一种基于深度学习的自然语言处理技术,通过对大量文本数据进行训练,可以生成具有一定语义和逻辑的文本。目前,AI大语言模型在自然语言理解、文本生成、知识问答等领域取得了显著的成果。
2.3 电商B侧运营与用户画像构建的联系
在电商B侧运营中,用户画像构建是关键环节。通过运用AI大语言模型,企业可以从海量的用户数据中提取有价值的信息,构建精准的用户画像,从而实现个性化推荐、精准营销等,提高运营效果。
3. 核心算法原理和具体操作步骤以及数学模型公式详细讲解
3.1 AI大语言模型的核心算法原理
AI大语言模型的核心算法原理是基于Transformer架构的自注意力机制(Self-Attention Mechanism)。自注意力机制可以捕捉文本中的长距离依赖关系,提高模型的表达能力。具体来说,自注意力机制通过计算文本中每个词与其他词之间的相关性,生成一个权重矩阵,用于表示文本的语义信息。
3.2 用户画像构建的具体操作步骤
- 数据收集:收集用户的基本信息、行为数据、消费记录等。
- 数据预处理:对收集到的数据进行清洗、去重、缺失值处理等。
- 特征工程:从预处理后的数据中提取有价值的特征,如用户的年龄、性别、职业、兴趣爱好等。
- 模型训练:利用AI大语言模型对特征数据进行训练,构建用户画像模型。
- 模型评估:通过一定的评价指标(如准确率、召回率等)评估模型的性能。
- 模型应用:将训练好的用户画像模型应用于电商B侧运营,实现个性化推荐、精准营销等。
3.3 数学模型公式详细讲解
在AI大语言模型中,自注意力机制的计算过程可以用以下数学公式表示:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dk QKT)V
其中, Q Q Q、 K K K、 V V V分别表示查询矩阵(Query)、键矩阵(Key)和值矩阵(Value), d k d_k dk表示词向量的维度。通过计算 Q K T QK^T QKT,可以得到文本中每个词与其他词之间的相关性,然后除以 d k \sqrt{d_k} dk 进行缩放,再应用softmax函数将相关性转换为权重。最后,将权重矩阵与值矩阵相乘,得到表示文本语义信息的矩阵。
4. 具体最佳实践:代码实例和详细解释说明
4.1 数据收集与预处理
假设我们已经收集到了用户的基本信息、行为数据和消费记录,存储在一个名为user_data的DataFrame中。首先,我们需要对数据进行预处理:
import pandas as pd # 数据清洗 user_data = user_data.drop_duplicates() # 去重 user_data = user_data.fillna(method='ffill') # 填充缺失值 # 数据转换 user_data['age'] = pd.cut(user_data['age'], bins=[0, 18, 35, 60, 100], labels=['少年', '青年', '中年', '老年']) # 将年龄分段
4.2 特征工程
接下来,我们需要从预处理后的数据中提取有价值的特征。这里,我们以用户的年龄、性别、职业和兴趣爱好为例:
# 提取特征 features = user_data[['age', 'gender', 'occupation', 'interests']]
4.3 模型训练
假设我们已经训练好了一个AI大语言模型(如GPT-3),我们可以将提取到的特征数据输入模型,构建用户画像模型:
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# 加载预训练模型
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
# 构建用户画像模型
user_profiles = []
for index, row in features.iterrows():
input_text = f"年龄:{row['age']},性别:{row['gender']},职业:{row['occupation']},兴趣爱好:{row['interests']}"
input_ids = tokenizer.encode(input_text, return_tensors='pt')
output = model.generate(input_ids, max_length=50, num_return_sequences=1)
user_profile = tokenizer.decode(output[0], skip_special_tokens=True)
user_profiles.append(user_profile)
4.4 模型评估与应用
在实际应用中,我们可以通过一定的评价指标(如准确率、召回率等)评估模型的性能。然后,将训练好的用户画像模型应用于电商B侧运营,实现个性化推荐、精准营销等。
5. 实际应用场景
AI大语言模型在电商B侧运营中的用户画像构建与应用可以应用于以下场景:
- 个性化推荐:根据用户画像,为用户推荐符合其兴趣和需求的商品,提高购买转化率。
- 精准营销:根据用户画像,制定针对性的营销策略,提高营销效果。
- 用户分群:根据用户画像,将用户进行细分,为不同群体提供差异化的服务。
- 用户流失预警:通过分析用户画像,预测用户流失的可能性,采取措施挽留用户。
6. 工具和资源推荐
7. 总结:未来发展趋势与挑战
AI大语言模型在电商B侧运营中的用户画像构建与应用具有巨大的潜力和价值。然而,目前仍面临一些挑战,如数据隐私保护、模型可解释性等。随着AI技术的不断发展,我们有理由相信,这些挑战将逐步得到解决,AI大语言模型在电商B侧运营中的应用将更加广泛和深入。
8. 附录:常见问题与解答
-
Q:AI大语言模型在用户画像构建中的优势是什么?
A:AI大语言模型具有强大的文本理解和生成能力,可以从海量的用户数据中提取有价值的信息,构建精准的用户画像,从而实现个性化推荐、精准营销等,提高运营效果。
-
Q:如何评估用户画像模型的性能?
A:可以通过一定的评价指标(如准确率、召回率等)评估模型的性能。在实际应用中,还可以通过观察模型对个性化推荐、精准营销等任务的效果来评估模型的性能。
-
Q:如何保护用户数据的隐私?
A:在收集和处理用户数据时,应遵循相关法律法规,确保用户数据的安全和隐私。此外,可以采用一些技术手段,如数据脱敏、差分隐私等,来保护用户数据的隐私。







