

前言
- A Time Series is Worth 64 Words论文下载地址,Github项目地址,论文解读系列
- 本文针对PatchTST模型参数与模型架构开源代码进行讲解,本人水平有限,若出现解读错误,欢迎指出
- 开源代码中分别实现了监督学习(PatchTST_supervised)与自监督学习(PatchTST_self_supervised)框架,本文仅针对监督学习框架进行讲解。
参数设定模块(run_longExp)
- 首先打开run_longExp.py文件保证在不修改任何参数的情况下,代码可以跑通,这里Windows系统需要将代码中--is_training、--model_id、--model、--data参数中required=True选项删除,否则会报错。--num_workers参数需要置为0。
- 其次需要在项目文件夹下新建子文件夹data用来存放训练数据,可以使用ETTh1数据,这里提供下载地址
- 运行run_longExp.py训练完成不报错就成功了
参数含义
- 下面是各参数含义(注释)
parser = argparse.ArgumentParser(description='Autoformer & Transformer family for Time Series Forecasting') # 随机数种子 parser.add_argument('--random_seed', type=int, default=2021, help='random seed') # basic config parser.add_argument('--is_training', type=int, default=1, help='status') parser.add_argument('--model_id', type=str, default='test', help='model id') parser.add_argument('--model', type=str, default='PatchTST', help='model name, options: [Autoformer, Informer, Transformer]') # 数据名称 parser.add_argument('--data', type=str, default='ETTh1', help='dataset type') # 数据所在文件夹 parser.add_argument('--root_path', type=str, default='./data/', help='root path of the data file') # 数据文件全称 parser.add_argument('--data_path', type=str, default='ETTh1.csv', help='data file') # 时间特征处理方式 parser.add_argument('--features', type=str, default='M', help='forecasting task, options:[M, S, MS]; M:multivariate predict multivariate, S:univariate predict univariate, MS:multivariate predict univariate') # 目标列列名 parser.add_argument('--target', type=str, default='OT', help='target feature in S or MS task') # 时间采集粒度 parser.add_argument('--freq', type=str, default='h', help='freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h') # 模型保存文件夹 parser.add_argument('--checkpoints', type=str, default='./checkpoints/', help='location of model checkpoints') # 回视窗口 parser.add_argument('--seq_len', type=int, default=96, help='input sequence length') # 先验序列长度 parser.add_argument('--label_len', type=int, default=48, help='start token length') # 预测窗口长度 parser.add_argument('--pred_len', type=int, default=96, help='prediction sequence length') # DLinear #parser.add_argument('--individual', action='store_true', default=False, help='DLinear: a linear layer for each variate(channel) individually') # PatchTST # 全连接层的dropout率 parser.add_argument('--fc_dropout', type=float, default=0.05, help='fully connected dropout') # 多头注意力机制的dropout率 parser.add_argument('--head_dropout', type=float, default=0.0, help='head dropout') # patch的长度 parser.add_argument('--patch_len', type=int, default=16, help='patch length') # 核的步长 parser.add_argument('--stride', type=int, default=8, help='stride') # padding方式 parser.add_argument('--padding_patch', default='end', help='None: None; end: padding on the end') # 是否要进行实例归一化(instancenorm1d) parser.add_argument('--revin', type=int, default=1, help='RevIN; True 1 False 0') # 是否要学习仿生参数 parser.add_argument('--affine', type=int, default=0, help='RevIN-affine; True 1 False 0') parser.add_argument('--subtract_last', type=int, default=0, help='0: subtract mean; 1: subtract last') # 是否做趋势分解 parser.add_argument('--decomposition', type=int, default=0, help='decomposition; True 1 False 0') # 趋势分解所用kerner_size parser.add_argument('--kernel_size', type=int, default=25, help='decomposition-kernel') parser.add_argument('--individual', type=int, default=0, help='individual head; True 1 False 0') # embedding方式 parser.add_argument('--embed_type', type=int, default=0, help='0: default 1: value embedding + temporal embedding + positional embedding 2: value embedding + temporal embedding 3: value embedding + positional embedding 4: value embedding') # encoder输入特征数 parser.add_argument('--enc_in', type=int, default=5, help='encoder input size') # DLinear with --individual, use this hyperparameter as the number of channels # decoder输入特征数 parser.add_argument('--dec_in', type=int, default=5, help='decoder input size') # 输出通道数 parser.add_argument('--c_out', type=int, default=5, help='output size') # 线性层隐含神经元个数 parser.add_argument('--d_model', type=int, default=512, help='dimension of model') # 多头注意力机制 parser.add_argument('--n_heads', type=int, default=8, help='num of heads') # encoder层数 parser.add_argument('--e_layers', type=int, default=2, help='num of encoder layers') # decoder层数 parser.add_argument('--d_layers', type=int, default=1, help='num of decoder layers') # FFN层隐含神经元个数 parser.add_argument('--d_ff', type=int, default=2048, help='dimension of fcn') # 滑动窗口长度 parser.add_argument('--moving_avg', type=int, default=25, help='window size of moving average') # 对Q进行采样,对Q采样的因子数 parser.add_argument('--factor', type=int, default=1, help='attn factor') # 是否下采样操作pooling parser.add_argument('--distil', action='store_false', help='whether to use distilling in encoder, using this argument means not using distilling', default=True) # dropout率 parser.add_argument('--dropout', type=float, default=0.05, help='dropout') # 时间特征嵌入方式 parser.add_argument('--embed', type=str, default='timeF', help='time features encoding, options:[timeF, fixed, learned]') # 激活函数类型 parser.add_argument('--activation', type=str, default='gelu', help='activation') # 是否输出attention矩阵 parser.add_argument('--output_attention', action='store_true', help='whether to output attention in ecoder') # 是否进行预测 parser.add_argument('--do_predict', action='store_true', help='whether to predict unseen future data') # 并行核心数 parser.add_argument('--num_workers', type=int, default=0, help='data loader num workers') # 实验轮数 parser.add_argument('--itr', type=int, default=1, help='experiments times') # 训练迭代次数 parser.add_argument('--train_epochs', type=int, default=100, help='train epochs') # batch size大小 parser.add_argument('--batch_size', type=int, default=128, help='batch size of train input data') # early stopping机制容忍次数 parser.add_argument('--patience', type=int, default=100, help='early stopping patience') # 学习率 parser.add_argument('--learning_rate', type=float, default=0.0001, help='optimizer learning rate') parser.add_argument('--des', type=str, default='test', help='exp description') # 损失函数 parser.add_argument('--loss', type=str, default='mse', help='loss function') # 学习率下降策略 parser.add_argument('--lradj', type=str, default='type3', help='adjust learning rate') parser.add_argument('--pct_start', type=float, default=0.3, help='pct_start') # 使用混合精度训练 parser.add_argument('--use_amp', action='store_true', help='use automatic mixed precision training', default=False) # GPU parser.add_argument('--use_gpu', type=bool, default=False, help='use gpu') parser.add_argument('--gpu', type=int, default=0, help='gpu') parser.add_argument('--use_multi_gpu', action='store_true', help='use multiple gpus', default=False) parser.add_argument('--devices', type=str, default='0,1,2,3', help='device ids of multile gpus') parser.add_argument('--test_flop', action='store_true', default=False, help='See utils/tools for usage')我们在exp.train(setting)行打上断点跳到训练主函数exp_main.py
数据处理模块
在_get_data中找到数据处理函数data_factory.py点击进入,可以看到各标准数据集处理方法:
data_dict = { 'ETTh1': Dataset_ETT_hour, 'ETTh2': Dataset_ETT_hour, 'ETTm1': Dataset_ETT_minute, 'ETTm2': Dataset_ETT_minute, 'power data': Dataset_Custom, 'custom': Dataset_Custom, }- 由于我们的数据集是ETTh1,那么数据处理的方式为Dataset_ETT_hour,我们进入data_loader.py文件,找到Dataset_ETT_hour类
- __init__主要用于传各类参数,这里不过多赘述,主要对__read_data__进行说明
def __read_data__(self): # 数据标准化实例 self.scaler = StandardScaler() # 读取数据 df_raw = pd.read_csv(os.path.join(self.root_path, self.data_path)) # 计算数据起始点 border1s = [0, 12 * 30 * 24 - self.seq_len, 12 * 30 * 24 + 4 * 30 * 24 - self.seq_len] border2s = [12 * 30 * 24, 12 * 30 * 24 + 4 * 30 * 24, 12 * 30 * 24 + 8 * 30 * 24] border1 = border1s[self.set_type] border2 = border2s[self.set_type] # 如果预测对象为多变量预测或多元预测单变量 if self.features == 'M' or self.features == 'MS': # 取除日期列的其他所有列 cols_data = df_raw.columns[1:] df_data = df_raw[cols_data] # 若预测类型为S(单特征预测单特征) elif self.features == 'S': # 取特征列 df_data = df_raw[[self.target]] # 将数据进行归一化 if self.scale: train_data = df_data[border1s[0]:border2s[0]] self.scaler.fit(train_data.values) data = self.scaler.transform(df_data.values) else: data = df_data.values # 取日期列 df_stamp = df_raw[['date']][border1:border2] # 利用pandas将数据转换为日期格式 df_stamp['date'] = pd.to_datetime(df_stamp.date) # 构建时间特征 if self.timeenc == 0: df_stamp['month'] = df_stamp.date.apply(lambda row: row.month, 1) df_stamp['day'] = df_stamp.date.apply(lambda row: row.day, 1) df_stamp['weekday'] = df_stamp.date.apply(lambda row: row.weekday(), 1) df_stamp['hour'] = df_stamp.date.apply(lambda row: row.hour, 1) data_stamp = df_stamp.drop(['date'], 1).values elif self.timeenc == 1: # 时间特征构造函数 data_stamp = time_features(pd.to_datetime(df_stamp['date'].values), freq=self.freq) # 转置 data_stamp = data_stamp.transpose(1, 0) # 取数据特征列 self.data_x = data[border1:border2] self.data_y = data[border1:border2] self.data_stamp = data_stamp- 需要注意的是time_features函数,用来提取日期特征,比如't':['month','day','weekday','hour','minute'],表示提取月,天,周,小时,分钟。可以打开timefeatures.py文件进行查阅,同样后期也可以加一些日期编码进去。
- 同样的,对__getitem__进行说明
def __getitem__(self, index): # 随机取得标签 s_begin = index # 训练区间 s_end = s_begin + self.seq_len # 有标签区间+无标签区间(预测时间步长) r_begin = s_end - self.label_len r_end = r_begin + self.label_len + self.pred_len # 取训练数据 seq_x = self.data_x[s_begin:s_end] seq_y = self.data_y[r_begin:r_end] # 取训练数据对应时间特征 seq_x_mark = self.data_stamp[s_begin:s_end] # 取有标签区间+无标签区间(预测时间步长)对应时间特征 seq_y_mark = self.data_stamp[r_begin:r_end] return seq_x, seq_y, seq_x_mark, seq_y_mark- 关于这部分数据处理可能有些绕,开源看我在SCInet代码讲解中数据处理那一部分,绘制了数据集划分图。
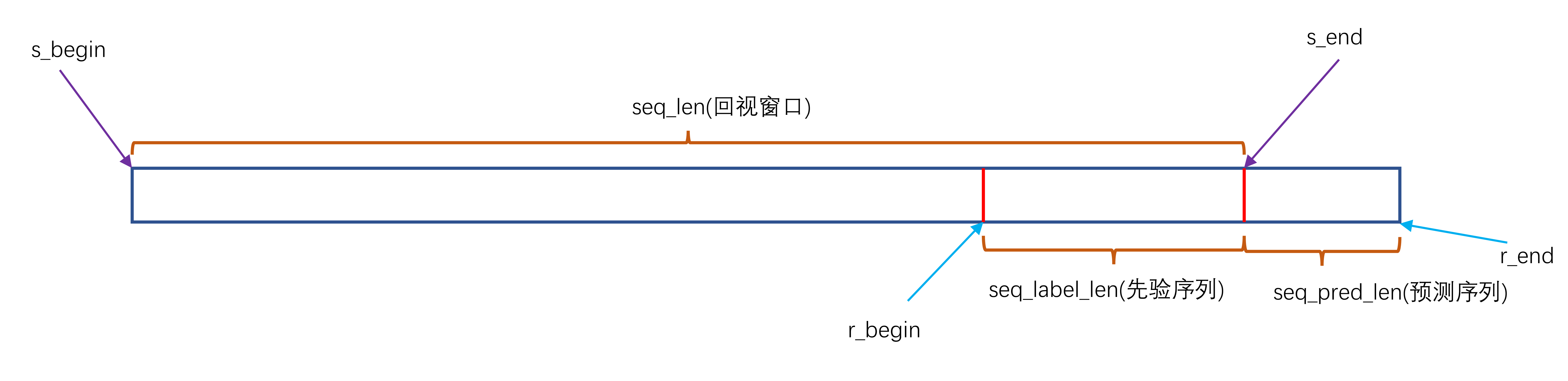
网络架构
- 这里将模型框架示意图展示出来,方便后续讲解。
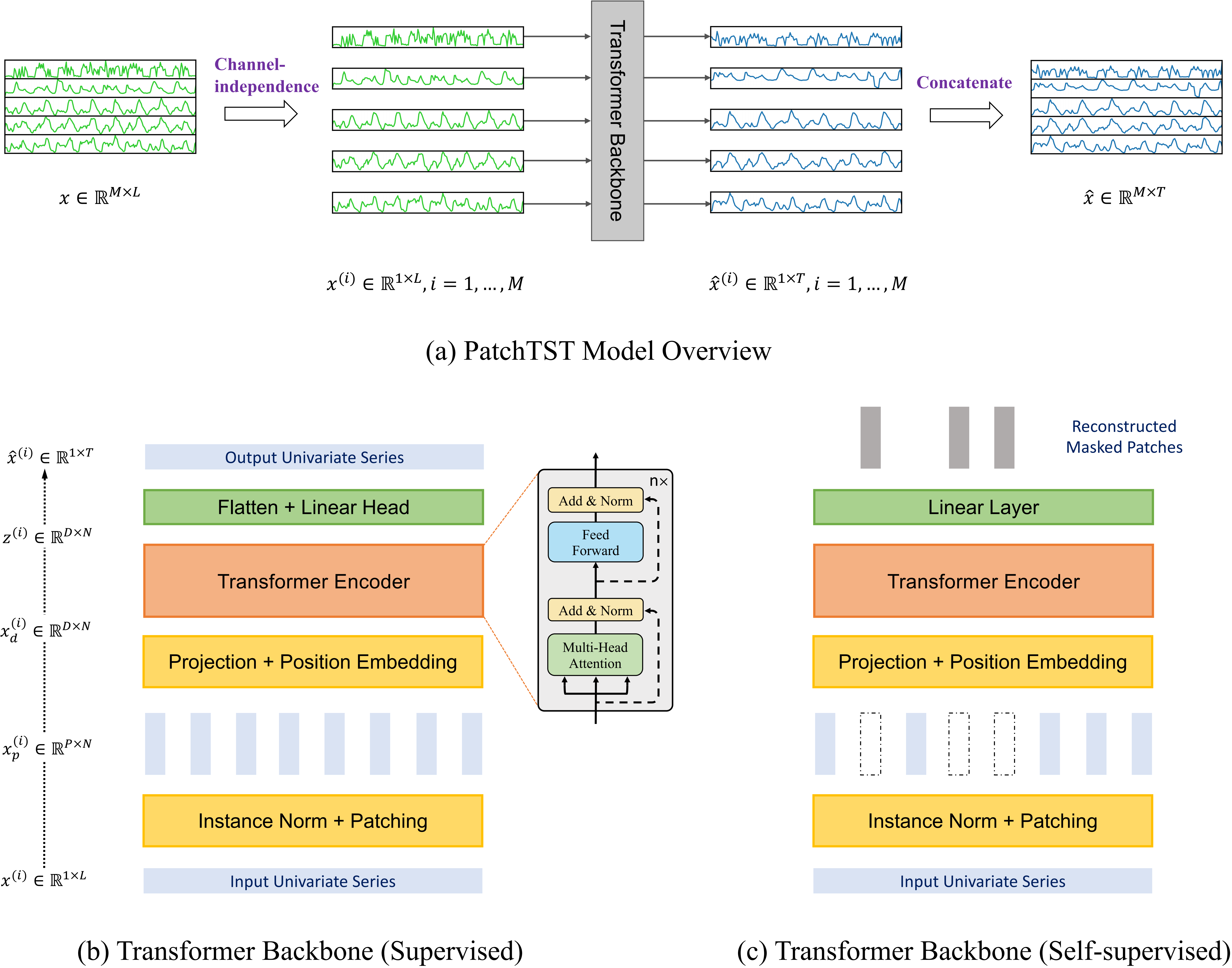
- 打开PatchTST.py文件,可以看到Model类中实例化了骨干网络PatchTST_backbone
PatchTST_backbone
- 可以看到PatchTST_backbone类,我们直接看该类forward方法。
- 首先将输入进行revin归一化,然后对数据进行padding操作,使用unfold方法通过滑窗得到不同patch。然后将数据输入TSTiEncoder中。得到输出,通过FNNhead输出结果,再反归一化Revin。
- 代码解析如下所示
class PatchTST_backbone(nn.Module): def __init__(self, c_in:int, context_window:int, target_window:int, patch_len:int, stride:int, max_seq_len:Optional[int]=1024, n_layers:int=3, d_model=128, n_heads=16, d_k:Optional[int]=None, d_v:Optional[int]=None, d_ff:int=256, norm:str='BatchNorm', attn_dropout:float=0., dropout:float=0., act:str="gelu", key_padding_mask:bool='auto', padding_var:Optional[int]=None, attn_mask:Optional[Tensor]=None, res_attention:bool=True, pre_norm:bool=False, store_attn:bool=False, pe:str='zeros', learn_pe:bool=True, fc_dropout:float=0., head_dropout = 0, padding_patch = None, pretrain_head:bool=False, head_type = 'flatten', individual = False, revin = True, affine = True, subtract_last = False, verbose:bool=False, **kwargs): super().__init__() # RevIn self.revin = revin if self.revin: self.revin_layer = RevIN(c_in, affine=affine, subtract_last=subtract_last) # Patching self.patch_len = patch_len self.stride = stride self.padding_patch = padding_patch patch_num = int((context_window - patch_len)/stride + 1) if padding_patch == 'end': # can be modified to general case self.padding_patch_layer = nn.ReplicationPad1d((0, stride)) patch_num += 1 # Backbone self.backbone = TSTiEncoder(c_in, patch_num=patch_num, patch_len=patch_len, max_seq_len=max_seq_len, n_layers=n_layers, d_model=d_model, n_heads=n_heads, d_k=d_k, d_v=d_v, d_ff=d_ff, attn_dropout=attn_dropout, dropout=dropout, act=act, key_padding_mask=key_padding_mask, padding_var=padding_var, attn_mask=attn_mask, res_attention=res_attention, pre_norm=pre_norm, store_attn=store_attn, pe=pe, learn_pe=learn_pe, verbose=verbose, **kwargs) # Head self.head_nf = d_model * patch_num self.n_vars = c_in self.pretrain_head = pretrain_head self.head_type = head_type self.individual = individual if self.pretrain_head: self.head = self.create_pretrain_head(self.head_nf, c_in, fc_dropout) # custom head passed as a partial func with all its kwargs elif head_type == 'flatten': self.head = Flatten_Head(self.individual, self.n_vars, self.head_nf, target_window, head_dropout=head_dropout) def forward(self, z): # z:[batch,feature,seq_len] # norm if self.revin: z = z.permute(0,2,1) z = self.revin_layer(z, 'norm') z = z.permute(0,2,1) # do patching if self.padding_patch == 'end': # padding操作 z = self.padding_patch_layer(z) # 从一个分批输入的张量中提取滑动的局部块 # z:[batch,feature,patch_num,patch_len] z = z.unfold(dimension=-1, size=self.patch_len, step=self.stride) # 维度交换z:[batch,feature,patch_len,patch_num] z = z.permute(0,1,3,2) # 进入骨干网络,输出维度[batch, feature, d_model, patch_num] z = self.backbone(z) z = self.head(z) # z: [bs x nvars x target_window] # 反归一化 if self.revin: z = z.permute(0,2,1) z = self.revin_layer(z, 'denorm') z = z.permute(0,2,1) return zTSTiEncoder
- 首先将数据进行维度转换,放入位置编码position_encoding函数,初始化为均匀分布[-0.02,0.02]区间
def positional_encoding(pe, learn_pe, q_len, d_model): # Positional encoding if pe == None: W_pos = torch.empty((q_len, d_model)) # pe = None and learn_pe = False can be used to measure impact of pe nn.init.uniform_(W_pos, -0.02, 0.02) learn_pe = False elif pe == 'zero': W_pos = torch.empty((q_len, 1)) nn.init.uniform_(W_pos, -0.02, 0.02) elif pe == 'zeros': W_pos = torch.empty((q_len, d_model)) nn.init.uniform_(W_pos, -0.02, 0.02) elif pe == 'normal' or pe == 'gauss': W_pos = torch.zeros((q_len, 1)) torch.nn.init.normal_(W_pos, mean=0.0, std=0.1) elif pe == 'uniform': W_pos = torch.zeros((q_len, 1)) nn.init.uniform_(W_pos, a=0.0, b=0.1) elif pe == 'lin1d': W_pos = Coord1dPosEncoding(q_len, exponential=False, normalize=True) elif pe == 'exp1d': W_pos = Coord1dPosEncoding(q_len, exponential=True, normalize=True) elif pe == 'lin2d': W_pos = Coord2dPosEncoding(q_len, d_model, exponential=False, normalize=True) elif pe == 'exp2d': W_pos = Coord2dPosEncoding(q_len, d_model, exponential=True, normalize=True) elif pe == 'sincos': W_pos = PositionalEncoding(q_len, d_model, normalize=True) else: raise ValueError(f"{pe} is not a valid pe (positional encoder. Available types: 'gauss'=='normal', \ 'zeros', 'zero', uniform', 'lin1d', 'exp1d', 'lin2d', 'exp2d', 'sincos', None.)") # 设定为可训练参数 return nn.Parameter(W_pos, requires_grad=learn_pe)- 然后进入dropout --> Encoder
class TSTiEncoder(nn.Module): #i means channel-independent def __init__(self, c_in, patch_num, patch_len, max_seq_len=1024, n_layers=3, d_model=128, n_heads=16, d_k=None, d_v=None, d_ff=256, norm='BatchNorm', attn_dropout=0., dropout=0., act="gelu", store_attn=False, key_padding_mask='auto', padding_var=None, attn_mask=None, res_attention=True, pre_norm=False, pe='zeros', learn_pe=True, verbose=False, **kwargs): super().__init__() self.patch_num = patch_num self.patch_len = patch_len # Input encoding q_len = patch_num self.W_P = nn.Linear(patch_len, d_model) # Eq 1: projection of feature vectors onto a d-dim vector space self.seq_len = q_len # Positional encoding self.W_pos = positional_encoding(pe, learn_pe, q_len, d_model) # Residual dropout self.dropout = nn.Dropout(dropout) # Encoder self.encoder = TSTEncoder(q_len, d_model, n_heads, d_k=d_k, d_v=d_v, d_ff=d_ff, norm=norm, attn_dropout=attn_dropout, dropout=dropout, pre_norm=pre_norm, activation=act, res_attention=res_attention, n_layers=n_layers, store_attn=store_attn) def forward(self, x) -> Tensor: # 输入x维度:[batch,feature,patch_len,patch_num] # 取feature数量 n_vars = x.shape[1] # 调换维度,变为:[batch, feature, patch_num, patch_len] x = x.permute(0,1,3,2) # 进入全连接层,输出为[batch, feature, patch_num, d_model] x = self.W_P(x) # 重置维度为[batch * feature, patch_nums, d_model] u = torch.reshape(x, (x.shape[0]*x.shape[1],x.shape[2],x.shape[3])) # 进入位置编码后共同进入dropout层[batch * feature,patch_nums,d_model] u = self.dropout(u + self.W_pos) # 进入encoder层后z的维度[batch * feature, patch_num, d_model] z = self.encoder(u) # 重置维度为[batch, feature, patch_num, d_model] z = torch.reshape(z, (-1,n_vars,z.shape[-2],z.shape[-1])) # 再度交换维度为[batch, feature, d_model, patch_num] z = z.permute(0,1,3,2) return zTSTEncoderLayer
class TSTEncoderLayer(nn.Module): def __init__(self, q_len, d_model, n_heads, d_k=None, d_v=None, d_ff=256, store_attn=False, norm='BatchNorm', attn_dropout=0, dropout=0., bias=True, activation="gelu", res_attention=False, pre_norm=False): super().__init__() assert not d_model%n_heads, f"d_model ({d_model}) must be divisible by n_heads ({n_heads})" d_k = d_model // n_heads if d_k is None else d_k d_v = d_model // n_heads if d_v is None else d_v # Multi-Head attention self.res_attention = res_attention self.self_attn = _MultiheadAttention(d_model, n_heads, d_k, d_v, attn_dropout=attn_dropout, proj_dropout=dropout, res_attention=res_attention) # Add & Norm self.dropout_attn = nn.Dropout(dropout) if "batch" in norm.lower(): self.norm_attn = nn.Sequential(Transpose(1,2), nn.BatchNorm1d(d_model), Transpose(1,2)) else: self.norm_attn = nn.LayerNorm(d_model) # Position-wise Feed-Forward self.ff = nn.Sequential(nn.Linear(d_model, d_ff, bias=bias), get_activation_fn(activation), nn.Dropout(dropout), nn.Linear(d_ff, d_model, bias=bias)) # Add & Norm self.dropout_ffn = nn.Dropout(dropout) if "batch" in norm.lower(): self.norm_ffn = nn.Sequential(Transpose(1,2), nn.BatchNorm1d(d_model), Transpose(1,2)) else: self.norm_ffn = nn.LayerNorm(d_model) self.pre_norm = pre_norm self.store_attn = store_attn def forward(self, src:Tensor, prev:Optional[Tensor]=None, key_padding_mask:Optional[Tensor]=None, attn_mask:Optional[Tensor]=None) -> Tensor: # Multi-Head attention sublayer if self.pre_norm: src = self.norm_attn(src) ## Multi-Head attention if self.res_attention: src2, attn, scores = self.self_attn(src, src, src, prev, key_padding_mask=key_padding_mask, attn_mask=attn_mask) else: src2, attn = self.self_attn(src, src, src, key_padding_mask=key_padding_mask, attn_mask=attn_mask) if self.store_attn: self.attn = attn ## Add & Norm src = src + self.dropout_attn(src2) # Add: residual connection with residual dropout if not self.pre_norm: src = self.norm_attn(src) # Feed-forward sublayer if self.pre_norm: src = self.norm_ffn(src) ## Position-wise Feed-Forward src2 = self.ff(src) ## Add & Norm src = src + self.dropout_ffn(src2) # Add: residual connection with residual dropout if not self.pre_norm: src = self.norm_ffn(src) if self.res_attention: return src, scores else: return srcFlatten层
class Flatten_Head(nn.Module): def __init__(self, individual, n_vars, nf, target_window, head_dropout=0): super().__init__() self.individual = individual self.n_vars = n_vars if self.individual: # 对每个特征进行展平,然后进入线性层和dropout层 self.linears = nn.ModuleList() self.dropouts = nn.ModuleList() self.flattens = nn.ModuleList() for i in range(self.n_vars): self.flattens.append(nn.Flatten(start_dim=-2)) self.linears.append(nn.Linear(nf, target_window)) self.dropouts.append(nn.Dropout(head_dropout)) else: self.flatten = nn.Flatten(start_dim=-2) self.linear = nn.Linear(nf, target_window) self.dropout = nn.Dropout(head_dropout) def forward(self, x): # x: [bs x nvars x d_model x patch_num] if self.individual: x_out = [] for i in range(self.n_vars): z = self.flattens[i](x[:,i,:,:]) # z: [bs x d_model * patch_num] z = self.linears[i](z) # z: [bs x target_window] z = self.dropouts[i](z) x_out.append(z) x = torch.stack(x_out, dim=1) # x: [bs x nvars x target_window] else: # 输出x为[batch,target_window] x = self.flatten(x) x = self.linear(x) x = self.dropout(x) return x
- 然后进入dropout --> Encoder
- 首先将数据进行维度转换,放入位置编码position_encoding函数,初始化为均匀分布[-0.02,0.02]区间
- 这里将模型框架示意图展示出来,方便后续讲解。
- 关于这部分数据处理可能有些绕,开源看我在SCInet代码讲解中数据处理那一部分,绘制了数据集划分图。
- 下面是各参数含义(注释)







