

一、导入包
import torch # pytorch import torch.nn as nn from torch.utils.data import Dataset, DataLoader, random_split
二、配置项
方便更新超参数,对模型进行参数调整

(图片来源网络,侵删)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
config = {
'seed': 5201314, # Your seed number, you can pick your lucky number. :)
'select_all': False, # Whether to use all features.
'valid_ratio': 0.2, # validation_size = train_size * valid_ratio
'n_epochs': 5000, # Number of epochs.
'batch_size': 256,
'learning_rate': 1e-5,
'early_stop': 600, # If model has not improved for this many consecutive epochs, stop training.
'save_path': './models/model.ckpt' # Your model will be saved here.
}
三、创建神经网络模型
class My_Model(nn.Module): # 搭建的神经网络 Model继承了 Module类(父类)
def __init__(self, input_dim): # 初始化函数
super(My_Model, self).__init__() # 必须要这一步,调用父类的初始化函数
# TODO: modify model's structure, be aware of dimensions.
self.layers = nn.Sequential(
nn.Linear(input_dim, 16),
nn.ReLU(),
nn.Linear(16, 8),
nn.ReLU(),
nn.Linear(8, 1)
)
def forward(self, x): # 前向传播(为输入和输出中间的处理过程),x为输入
x = self.layers(x)
x = x.squeeze(1) # (B, 1) -> (B)
return x
四、模型训练过程
def trainer(train_loader, valid_loader, model, config, device):
criterion = nn.MSELoss(reduction='mean') # Define your loss function, do not modify this.
# Define your optimization algorithm.
# TODO: Please check https://pytorch.org/docs/stable/optim.html to get more available algorithms.
# TODO: L2 regularization (optimizer(weight decay...) or implement by your self).
optimizer = torch.optim.SGD(model.parameters(), lr=config['learning_rate'], momentum=0.9)
# math.inf为无限大
n_epochs, best_loss, step, early_stop_count = config['n_epochs'], math.inf, 0, 0
for epoch in range(n_epochs):
model.train() # Set your model to train mode.
loss_record = [] # 记录损失
for x, y in train_loader:
optimizer.zero_grad() # Set gradient to zero. 梯度清0
x, y = x.to(device), y.to(device) # Move your data to device.
pred = model(x) # 数据传入模型model,生成预测值pred
loss = criterion(pred, y) # 预测值pred和真实值y计算损失loss
loss.backward() # Compute gradient(backpropagation).
optimizer.step() # Update parameters.
step += 1
loss_record.append(loss.detach().item()) # 当前步骤的loss加到loss_record[]
# Display current epoch number and loss on tqdm progress bar.
train_pbar.set_description(f'Epoch [{epoch+1}/{n_epochs}]')
train_pbar.set_postfix({'loss': loss.detach().item()})
mean_train_loss = sum(loss_record)/len(loss_record) # 计算训练集上平均损失
writer.add_scalar('Loss/train', mean_train_loss, step)
model.eval() # Set your model to evaluation mode.
loss_record = []
for x, y in valid_loader:
x, y = x.to(device), y.to(device)
with torch.no_grad():
pred = model(x)
loss = criterion(pred, y)
loss_record.append(loss.item())
mean_valid_loss = sum(loss_record)/len(loss_record) # 计算验证集上平均损失
print(f'Epoch [{epoch+1}/{n_epochs}]: Train loss: {mean_train_loss:.4f}, Valid loss: {mean_valid_loss:.4f}')
writer.add_scalar('Loss/valid', mean_valid_loss, step)
# 保存验证集上平均损失最小的模型
if mean_valid_loss = config['early_stop']:
print('\nModel is not improving, so we halt the training session.')
return
五、训练模型
# 创建模型model,将模型和数据放到相同的计算设备上 model = My_Model(input_dim=x_train.shape[1]).to(device) # 开始训练 trainer(train_loader, valid_loader, model, config, device)
六、模型测试过程
# 测试数据集的预测
def predict(test_loader, model, device):
model.eval() # Set your model to evaluation mode.
preds = []
for x in tqdm(test_loader):
x = x.to(device)
with torch.no_grad(): # 关闭梯度
pred = model(x)
preds.append(pred.detach().cpu())
preds = torch.cat(preds, dim=0).numpy()
return preds
七、测试模型
def save_pred(preds, file):
''' Save predictions to specified file '''
with open(file, 'w') as fp:
writer = csv.writer(fp)
writer.writerow(['id', 'tested_positive'])
for i, p in enumerate(preds):
writer.writerow([i, p])
model = My_Model(input_dim=x_train.shape[1]).to(device)
model.load_state_dict(torch.load(config['save_path'])) # 加载模型
preds = predict(test_loader, model, device) # 生成预测结果preds
save_pred(preds, 'pred.csv') # 保存preds到pred.csv
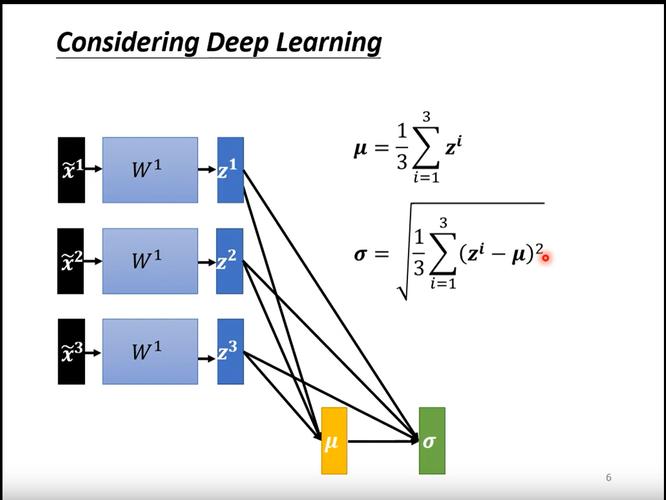
(图片来源网络,侵删)







