

- 大家好,我是同学小张,日常分享AI知识和实战案例
- 欢迎 点赞 + 关注 👏,持续学习,持续干货输出。
- +v: jasper_8017 一起交流💬,一起进步💪。
- 微信公众号也可搜【同学小张】 🙏
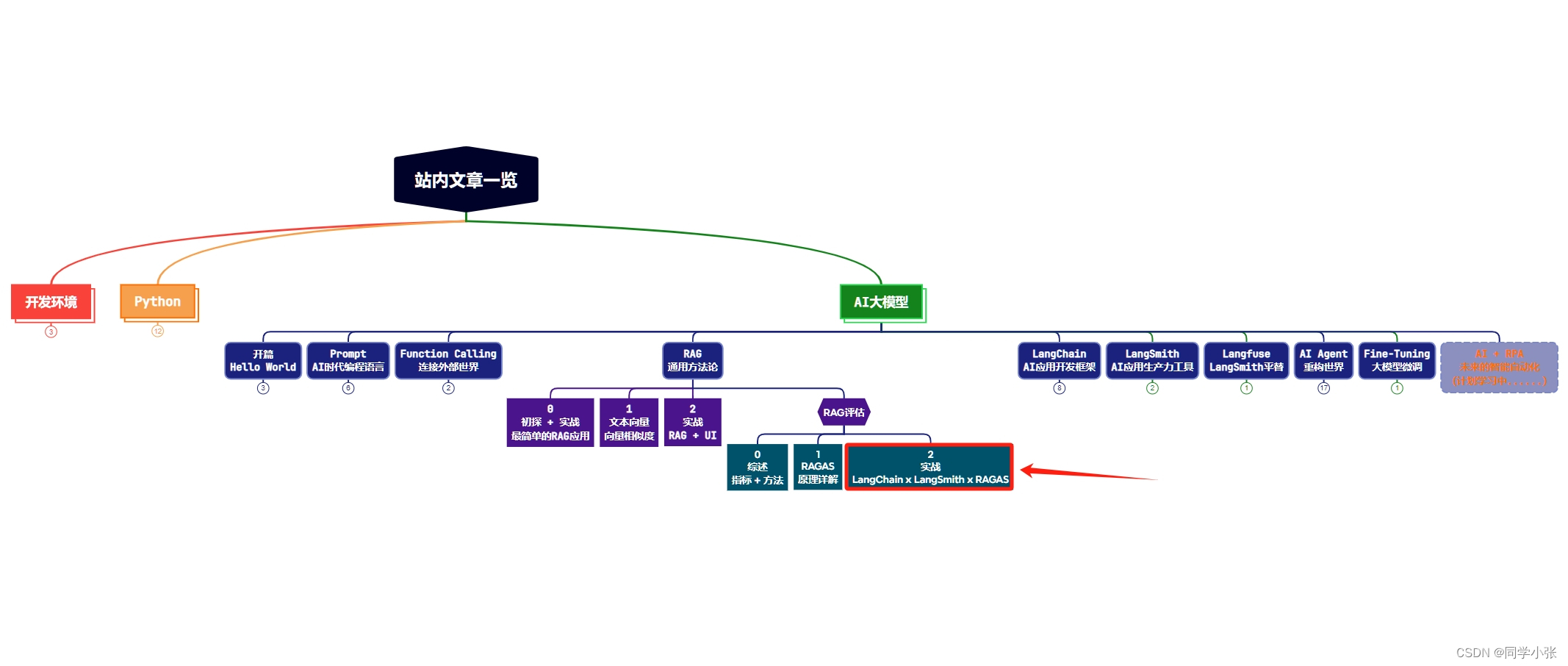
本站文章一览:
上篇文章【AI大模型应用开发】【RAG评估】1. 通俗易懂:深度理解RAGAS评估方法的原理与应用 我们详细讲解了RAGAs的原理和实现方式,今天我们完整的实战一遍。将RAGAs集成在LangChain的RAG应用中,同时打通LangSmith平台,使评估过程可视化。
实践完之后,通过LangSmith平台,还会有意外收获:带你看看如何利用LangSmith平台来有效学习LangChain的使用和相关知识。
文章目录
- 0. 前置 - 环境安装
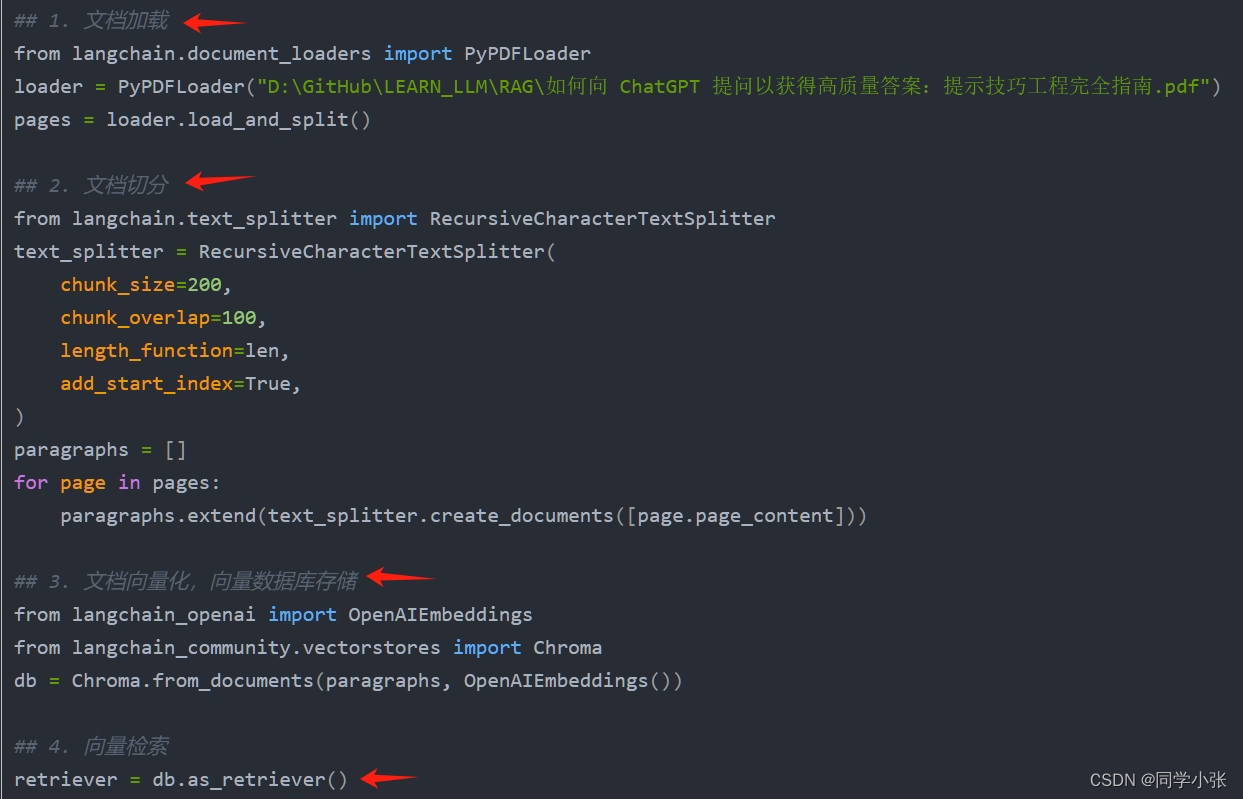
- 1. 创建RAG
- 0.1 文本加载
- 0.2 创建向量索引
- 0.2.1 代码
- 0.2.2 `VectorstoreIndexCreator` 介绍
- 0.3 创建QA链
- 0.3.1 代码
- 0.3.2 `RetrievalQA` 介绍
- 0.4 提问,运行QA链,得到RAG结果
- 1. 加入评估
- 2. 接入LangSmith
- 3. 完整代码
- 4. 使用LangSmith中的测试数据集进行测试
- 4.1 创建及数据集
- 4.2 使用数据集进行评估
- 4.3 完整代码
- 5. LangSmith助力LangChain学习
- 6. 遗留问题
0. 前置 - 环境安装
- 安装 langchain 和 ragas,注意安装ragas的 0.0.22 版本
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -U langchain pip install ragas==0.0.22
- 如果安装了高版本的 ragas,例如 >= 0.1 版本,运行本文的代码会报错:
ModuleNotFoundError: No module named ‘ragas.langchain’
原因是现在 langchain 还没有对 ragas 0.1 及以后版本作兼容(截止到 2024-02-25)。目前有两个选择:
(1)不使用 langchain 来实现你的功能,也就不用 langchain 内的 ragas,直接使用原生的 ragas。
(2)使用 ragas 的 0.0.22 版本
ragas 0.1 does not yet have this feature. We are working on it, for now you have two options
- Use ragas natively w/o the chain, in this way, you get all the new capabilities of 0.1 version
- reinstall and use 0.0.22
1. 创建RAG
0.1 文本加载
这里使用 langchain 中的 WebBaseLoader 来加载 html 数据:loader = WebBaseLoader("https://baike.baidu.com/item/%E7%BA%BD%E7%BA%A6/6230")
WebBaseLoader是LangChain中集成的用于加载网页中文字的类,详细使用方式可参考这里。
from langchain_community.document_loaders import WebBaseLoader loader = WebBaseLoader("https://baike.baidu.com/item/%E7%BA%BD%E7%BA%A6/6230") loader.requests_kwargs = {'verify':False} data = loader.load() print(data)将加载到的html数据打印出来看下,如下:

0.2 创建向量索引
0.2.1 代码
from langchain.indexes import VectorstoreIndexCreator index = VectorstoreIndexCreator().from_loaders([loader])
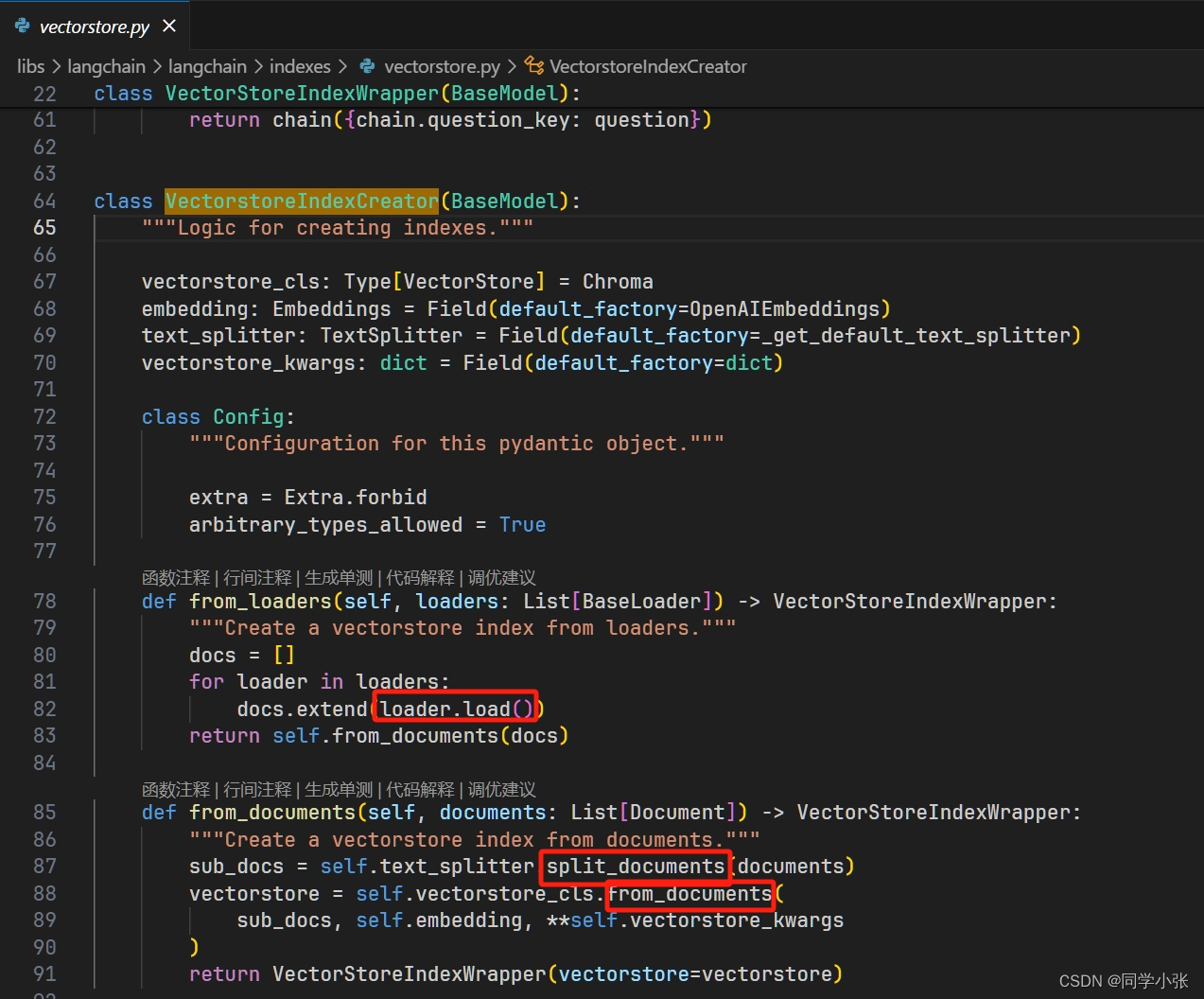
0.2.2 VectorstoreIndexCreator 介绍
VectorstoreIndexCreator 是一个用于创建索引的组件,用于查询文本文档。它将文档分割成更小的块,为每个文档生成嵌入(即数字表示),并将文档及其嵌入存储在向量库中,然后可以对其进行查询以检索相关文档。
回顾我们创建索引的过程:加载文档 —> 分割文本 —> 生成文本向量,存储。参考之前的文章:【AI大模型应用开发】【LangChain系列】4. 从Chain到LCEL:探索和实战LangChain的巧妙设计
这里利用 VectorstoreIndexCreator 一行代码就搞定了。所以,VectorstoreIndexCreator就是 LangChain 对以上过程的高层封装。看下它的源码:
- from_loaders:通过传入的Loader加载文本数据,然后调用 from_documents
- from_documents:切分文本,生成文本向量并存储
0.3 创建QA链
0.3.1 代码
from langchain.chains import RetrievalQA from langchain_community.chat_models import ChatOpenAI llm = ChatOpenAI() qa_chain = RetrievalQA.from_chain_type( llm, retriever=index.vectorstore.as_retriever(), return_source_documents=True )0.3.2 RetrievalQA 介绍
参考文档:https://python.langchain.com/docs/modules/chains/#legacy-chains

RetrievalQA 是 LangChain对问答类Chain的高层封装,它内部首先做检索步骤,然后将检索到的文档给到 LLM 生成结果。
0.4 提问,运行QA链,得到RAG结果
question = "纽约市的名字是怎么得来的?" result = qa_chain({"query": question}) # result["result"] print("========= chain result ==========") print(result)
这里关注下返回结果的结构,其中的key值为:
- query
- result
- source_documents
这个key值很关键,后面的RAGAs内部就是去取这些Key值里面的内容,错一个字符都会提取不到数据,报错。
1. 加入评估
context_recall 指标需要给定参考结果,放到key值为"ground_truths"的地方。没有"ground_truths",该指标的评估会报错。
主要使用 RagasEvaluatorChain 链。
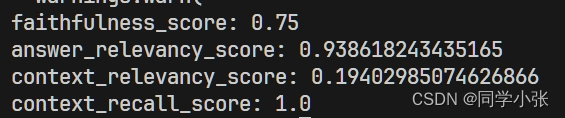
result['ground_truths'] = "纽约市的名字“纽约”来源于荷兰战败后将新阿姆斯特丹割让给英国的事件。" from ragas.metrics import faithfulness, answer_relevancy, context_relevancy, context_recall from ragas.langchain.evalchain import RagasEvaluatorChain # make eval chains eval_chains = { m.name: RagasEvaluatorChain(metric=m) for m in [faithfulness, answer_relevancy, context_relevancy, context_recall] } # evaluate for name, eval_chain in eval_chains.items(): score_name = f"{name}_score" print(f"{score_name}: {eval_chain(result)[score_name]}")
运行结果:
2. 接入LangSmith
LangSmith平台的具体使用方法,可以参考前面的文章:
- 【AI大模型应用开发】【LangSmith: 生产级AI应用维护平台】0. 一文全览Tracing功能,让你的程序运行过程一目了然
接入 LangSmith,只需在代码最前面加入以下代码。
import os os.environ["LANGCHAIN_API_KEY"] = "ls__xxxxxx" os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com" os.environ["LANGCHAIN_TRACING_V2"]="true" os.environ["LANGCHAIN_PROJECT"]="test-ragas"
运行程序之后,可以在LangSmith平台看到当前程序的运行过程。从下图可以看到一共运行了5个链,一个RetrievalQA链,四个RagasEvaluatorChain评估链(因为使用了四个测试指标),点击相应链,可以看到详细的运行过程日志和运行统计。
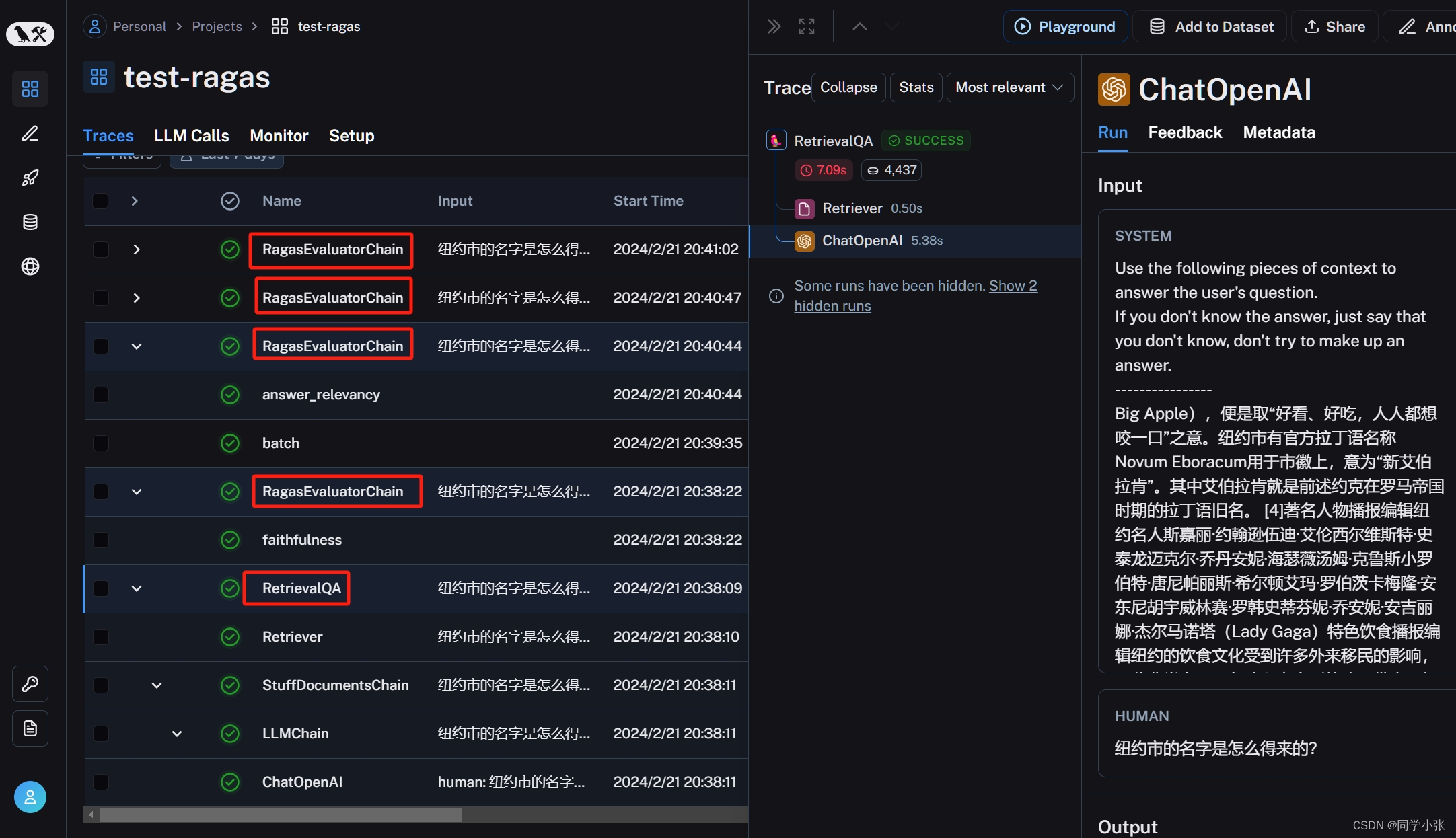
3. 完整代码
import os os.environ["LANGCHAIN_API_KEY"] = "ls__xxxxxx" os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com" os.environ["LANGCHAIN_TRACING_V2"]="true" os.environ["LANGCHAIN_PROJECT"]="test-ragas" from langchain_community.document_loaders import WebBaseLoader from langchain.indexes import VectorstoreIndexCreator from langchain.chains import RetrievalQA from langchain_community.chat_models import ChatOpenAI # load the Wikipedia page and create index loader = WebBaseLoader("https://baike.baidu.com/item/%E7%BA%BD%E7%BA%A6/6230") loader.requests_kwargs = {'verify':False} index = VectorstoreIndexCreator().from_loaders([loader]) # create the QA chain llm = ChatOpenAI() qa_chain = RetrievalQA.from_chain_type( llm, retriever=index.vectorstore.as_retriever(), return_source_documents=True ) # # testing it out question = "纽约市的名字是怎么得来的?" result = qa_chain({"query": question}) # result["result"] print("========= chain result ==========") print(result) result['ground_truths'] = "纽约市的名字“纽约”来源于荷兰战败后将新阿姆斯特丹割让给英国的事件。" from ragas.metrics import faithfulness, answer_relevancy, context_relevancy, context_recall from ragas.langchain.evalchain import RagasEvaluatorChain # make eval chains eval_chains = { m.name: RagasEvaluatorChain(metric=m) for m in [faithfulness, answer_relevancy, context_relevancy, context_recall] } # evaluate for name, eval_chain in eval_chains.items(): score_name = f"{name}_score" print(f"{score_name}: {eval_chain(result)[score_name]}")4. 使用LangSmith中的测试数据集进行测试
除了以上在运行过程中实时获取评估结果,我们还可以针对某些数据集进行集中评估。下面是操作方法。
LangSmith平台测试数据集的具体使用方法,可以参考前面的文章:
- 【AI大模型应用开发】【LangSmith: 生产级AI应用维护平台】1. 快速上手数据集与测试评估过程
4.1 创建及数据集
首先可以创建一个数据集。
- create_dataset:用来在LangSmith平台创建数据集
- read_dataset:用来读取LangSmith平台的数据集
# 测试数据集 eval_questions = [ "纽约市的名字是怎么得来的?", ] eval_answers = [ "纽约市的名字“纽约”来源于荷兰战败后将新阿姆斯特丹割让给英国的事件。", ] examples = [{"query": q, "ground_truths": [eval_answers[i]]} for i, q in enumerate(eval_questions)] # dataset creation from langsmith import Client from langsmith.utils import LangSmithError client = Client() dataset_name = "NYC test" try: # check if dataset exists dataset = client.read_dataset(dataset_name=dataset_name) print("using existing dataset: ", dataset.name) except LangSmithError: # if not create a new one with the generated query examples dataset = client.create_dataset( dataset_name=dataset_name, description="NYC test dataset" ) for e in examples: client.create_example( inputs={"query": e["query"]}, outputs={"ground_truths": e["ground_truths"]}, dataset_id=dataset.id, ) print("Created a new dataset: ", dataset.name)4.2 使用数据集进行评估
(1)首先定义评估函数:RunEvalConfig,这里填入的是四个评估指标链
(2)run_on_dataset,执行测试
from langchain.smith import RunEvalConfig, run_on_dataset evaluation_config = RunEvalConfig( custom_evaluators=[ faithfulness_chain, answer_rel_chain, context_rel_chain, context_recall_chain, ], prediction_key="result", ) result = run_on_dataset( client, dataset_name, qa_chain, evaluation=evaluation_config, input_mapper=lambda x: x, )4.3 完整代码
import os os.environ["LANGCHAIN_TRACING_V2"]="true" os.environ["LANGCHAIN_PROJECT"]="test-ragas2" from langchain_community.document_loaders import WebBaseLoader from langchain.indexes import VectorstoreIndexCreator from langchain.chains import RetrievalQA from langchain_community.chat_models import ChatOpenAI # load the Wikipedia page and create index loader = WebBaseLoader("https://baike.baidu.com/item/%E7%BA%BD%E7%BA%A6/6230") loader.requests_kwargs = {'verify':False} index = VectorstoreIndexCreator().from_loaders([loader]) # create the QA chain llm = ChatOpenAI() qa_chain = RetrievalQA.from_chain_type( llm, retriever=index.vectorstore.as_retriever(), return_source_documents=True ) from ragas.metrics import faithfulness, answer_relevancy, context_relevancy, context_recall from ragas.langchain.evalchain import RagasEvaluatorChain # create evaluation chains faithfulness_chain = RagasEvaluatorChain(metric=faithfulness) answer_rel_chain = RagasEvaluatorChain(metric=answer_relevancy) context_rel_chain = RagasEvaluatorChain(metric=context_relevancy) context_recall_chain = RagasEvaluatorChain(metric=context_recall) # 测试数据集 eval_questions = [ "纽约市的名字是怎么得来的?", ] eval_answers = [ "纽约市的名字“纽约”来源于荷兰战败后将新阿姆斯特丹割让给英国的事件。", ] examples = [{"query": q, "ground_truths": [eval_answers[i]]} for i, q in enumerate(eval_questions)] # dataset creation from langsmith import Client from langsmith.utils import LangSmithError client = Client() dataset_name = "ragas test data" try: # check if dataset exists dataset = client.read_dataset(dataset_name=dataset_name) print("using existing dataset: ", dataset.name) except LangSmithError: # if not create a new one with the generated query examples dataset = client.create_dataset( dataset_name=dataset_name, description="NYC test dataset" ) for e in examples: client.create_example( inputs={"query": e["query"]}, outputs={"ground_truths": e["ground_truths"]}, dataset_id=dataset.id, ) print("Created a new dataset: ", dataset.name) from langchain.smith import RunEvalConfig, run_on_dataset evaluation_config = RunEvalConfig( custom_evaluators=[ faithfulness_chain, answer_rel_chain, context_rel_chain, context_recall_chain, ], prediction_key="result", ) result = run_on_dataset( client, dataset_name, qa_chain, evaluation=evaluation_config, input_mapper=lambda x: x, )注意:这里与前面方法的区别在于,利用测试数据集来测试时,不用再自己调用大模型获取result了,也不用自己再一个一个调用评估链了,也就是下面的代码不用了,这些在run_on_dataset就帮你做了。
# # testing it out question = "纽约市的名字是怎么得来的?" result = qa_chain({"query": question}) # result["result"] print("========= chain result ==========") print(result) result['ground_truths'] = "纽约市的名字“纽约”来源于荷兰战败后将新阿姆斯特丹割让给英国的事件。"# evaluate for name, eval_chain in eval_chains.items(): score_name = f"{name}_score" print(f"{score_name}: {eval_chain(result)[score_name]}")5. LangSmith助力LangChain学习
这里是一点意外收获,跟大家分享一下。
在使用 LangSmith 看运行过程的时候,发现它将 RetrievalQA 的详细过程列出来了:
- 首先是使用了Retriever
- 然后是使用了StuffDocumentsChain下的LLMChain,LLMChain下调用了LLM
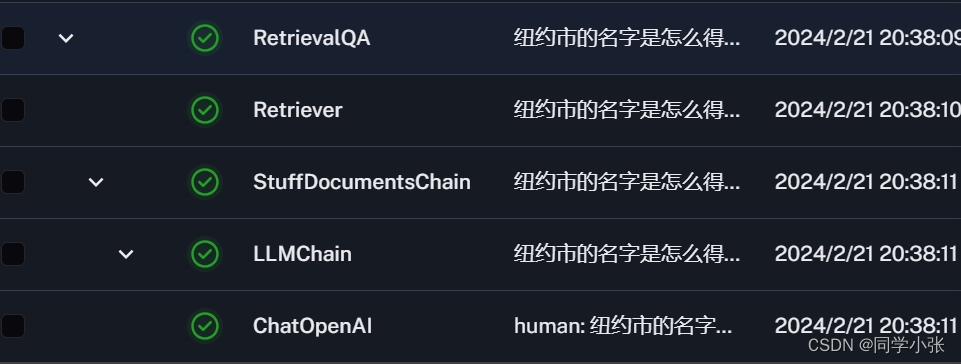
而这个过程,在我们的代码中,仅一行:result = qa_chain({"query": question})。对于像我一样不知道 RetrievalQA 工作机制的人来说,从上面这个过程可以学习到一些内容,不用看源码就知道它里面首先自己进行了检索,然后内部自己调用了LLM。
这只是一个简单的感受,就是 LangSmith 的 Traces 功能有时候能帮助我们更好地了解LangChain内部的工作机制和工作步骤。
6. 遗留问题
我的LangSmith平台上关于评估链的信息是这样的:
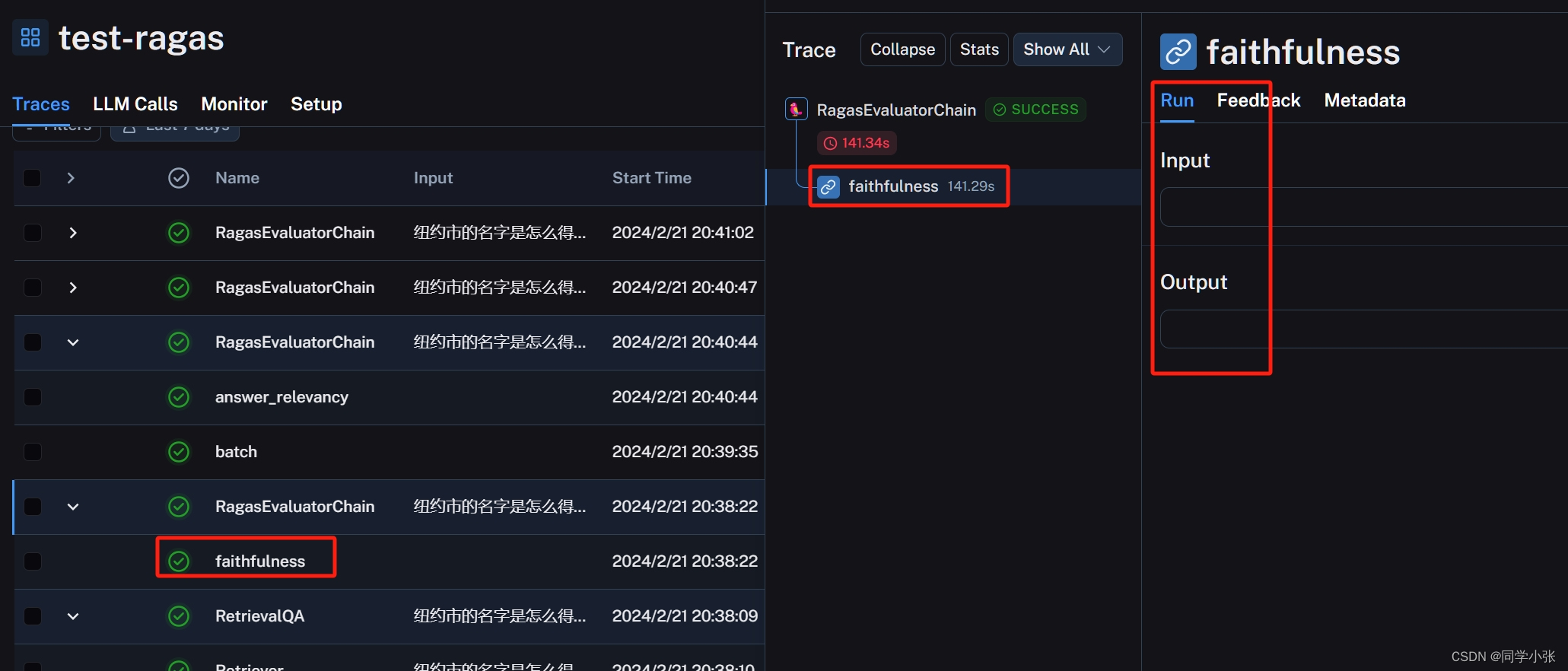
它并没有跟踪到详细运行步骤,从前面文章中我们知道这几个指标都需要调用LLM,但这里没有跟踪到。网上的例子可以跟踪到评估链调用大模型的过程(当然这个教程(https://blog.langchain.dev/evaluating-rag-pipelines-with-ragas-langsmith/)时间好早了):
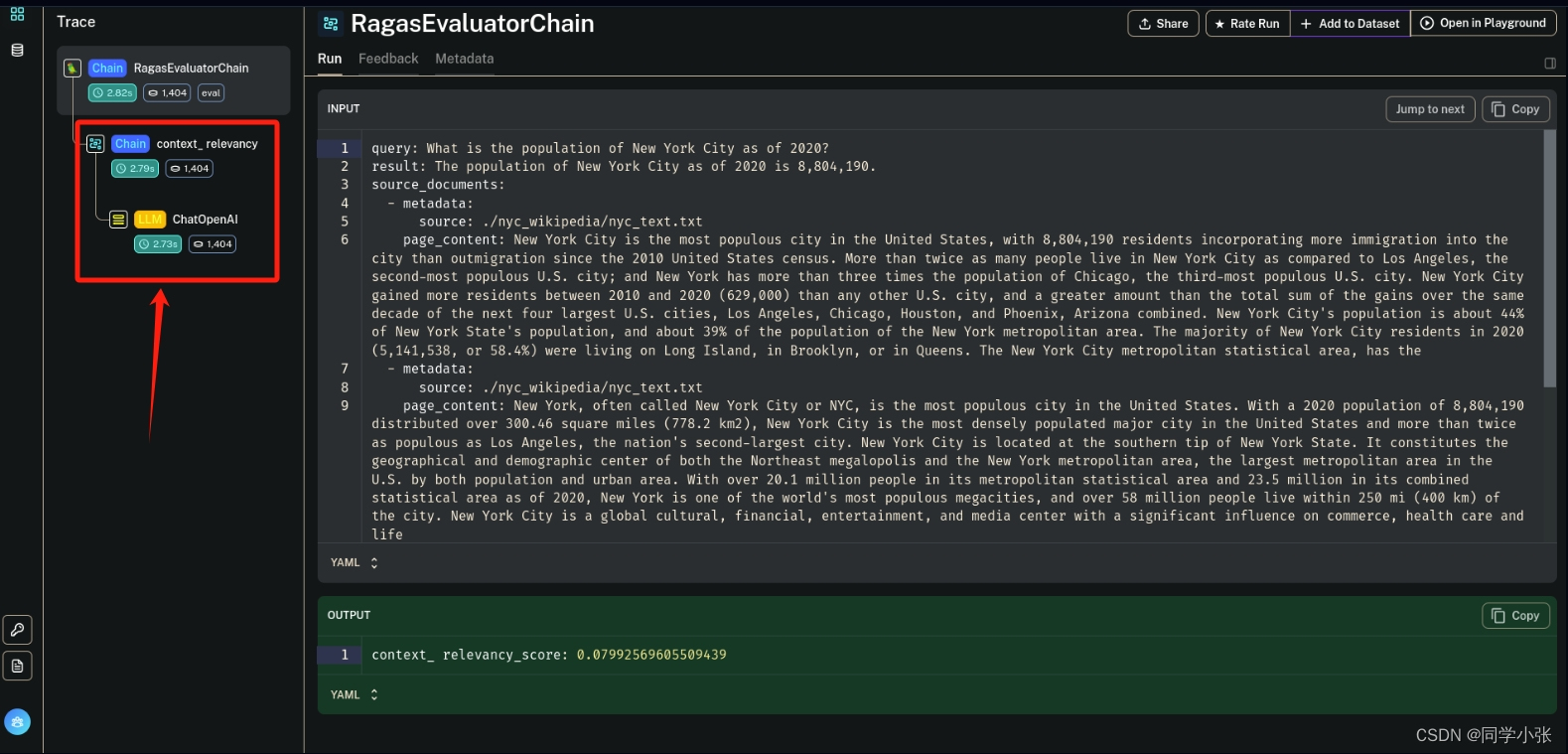
不知道是不是因为LangChain现在不兼容RAGAS导致的。后续再看看吧。
如果觉得本文对你有帮助,麻烦点个赞和关注呗 ~~~
- 大家好,我是同学小张,日常分享AI知识和实战案例
- 欢迎 点赞 + 关注 👏,持续学习,持续干货输出。
- +v: jasper_8017 一起交流💬,一起进步💪。
- 微信公众号也可搜【同学小张】 🙏
本站文章一览:
- 【AI大模型应用开发】【LangSmith: 生产级AI应用维护平台】1. 快速上手数据集与测试评估过程
- 【AI大模型应用开发】【LangSmith: 生产级AI应用维护平台】0. 一文全览Tracing功能,让你的程序运行过程一目了然
- 如果安装了高版本的 ragas,例如 >= 0.1 版本,运行本文的代码会报错:
- 安装 langchain 和 ragas,注意安装ragas的 0.0.22 版本







