

一、结构体
1、作用:
2、语法:
struct 结构体类型名
{
数据成员列表;
};
eg:
描述学生这种类型:
struct student
{
char name[20]; //成员变量 各个成员变量之间 用分号隔开
unsigned char age;//0~255 -128~127
float score;
//...
}; //注意: 最后这个分号(;) 表示 --- 结构体类型定义完成
3、类型与变量:
struct student //学生数据类型 struct student s; //s这种类型的一个变量
eg:定义一位名叫张三的同学的信息
struct student s = {"zhangsan",23,134};
4、结构体变量初始化与赋值:
初始化:struct student s = {"zhangsan",23,134};
结构体变量赋值:结构体不能整体赋值
struct student s;
s = {"tom",20,89.5,100}; // error
struct student s1 = {"tom",20,89.5,100};
struct student s2;
s2 = s1; //true
5、访问结构体:
类型一: 结构体变量名.成员变量名 // . 是结构体成员运算符 类型二: -> //用于结构体类型的指针变量的
结构体类型的变量.成员变量名
结构体类型的指针->成员变量名
eg: s.name //可访问到结构体中的name成员 struct student *s = &s1; s->name
练习:
老师
struct
名字
工号
工资
练习:
定义学生类型的结构体
封装函数,从键盘输入3个学生的信息
封装函数,将三个学生的信息打印出来
练习:
找出 成绩最高的学生 ,输出它的信息
//函数
找最大值
//
练习:
排序
qsort
name sno score
分别
按照 名字,学号,分数排序输出
6、结构体的对齐规则:
0.(有冲突1,2服从3,4)
1.在32位的平台上,起始默认都是按4字节对齐(地址能被4整除)的。 //64位的平台 默认是8字节
2.对于成员变量,各自在自己的自然边界上对齐。(地址能被自己自身所拥有的类型大小整除)
自然边界对齐
int -- 4字节 --- 能被4整除的地址编号上
short -- 2字节 --- 能被2整除的地址编号上
char -- 1字节 --- 能被1整除的地址编号上
//整个结构体的对齐
3.如果成员变量中有比4字节大。
此时 整个结构体按照4字节对齐。 //32位的平台
4.如果 成员变量中没有有比4字节大。
此时 整个结构体按照最大的那个成员对齐。
注意:
1.结构体类型,可以定义在函数里面,但是此时作用域就被限定在改函数中
2.结构体的定义的形式
//形式1 先定义类型,后定义变量
struct stu
{
...
};
struct stu s;
//形式2 定义类型的同时定义变量
struct stu
{
...
}s1,s2,*s3,s4[10];
struct stu s;
//形式3 省略了类型名 --如果只用一次,可以这样写
struct
{
...
}s1,s2,*s3,s4[10];
二、共用体
1、定义:
有时需要使几种不同类型的变址存放到同一段内存单元中。例如,可把一个整型变
量、一个字符型变量、一个实型变量放在同一个地址开始的内存单元中
2、定义一个共用体类型,定义一个共用体变量:
union 共用体名
{
成员列表; //各个变量
}; //表示定义一个共用体类型
union emo s1; //s1就是共用体变量
3、注意:
a、共用体的初始化 --- 只能给一个值,默认是给到第一个成员变量的
union emo
{
int a;
char b;
};
int main()
{
union emo s = {1};
return 0;
}
b、共用体用的数据最终存储的 --- 应该是最后一次给到的值
但是只能影响到自己数据类型对应的空间中的数据
union emo
{
int a;
char b;
};
int main()
{
union emo s1 = {'a'};
s1.a = 0x12345678;
s1.b = 0x11;
printf("%#x\n",s1.a); //0x12345611 ,验证了存储方式,也验证了是大端存储还是小端存储,证明是小端存储
printf("%#x\n",s1.b); //0x11
return 0;
}
c、共用体的大小 --- 是成员变量中最大的那个成员的大小
d、小技巧,可以用共用体判断大小端
union emo
{
int a;
char b;
};
int main()
{
union emo s1 = {1};
s1.a = 1; //1在内存中的存储格式是0000 0000 0000 0001
printf("%d",s1.b); //1 证明是小端存储
return 0;
}
e、实际用途
a.节省空间
b.进行数据转换
192.168.1.169 //ip本质是个 32位的数值
f、共用体加结构体
struct stu
{
char name[20];
int sno;
float score;
}
struct teacher
{
char name[20];
int Tno;
float salary;
}
struct member
{
char name[20];
int no;
union
{
float score;
float salary;
}d;
}
g、共用体类型可以是函数参数,也可以是函数返回值类型
共用体,结构体类型定义出来之后,
a.定义变量
b.定义数组
c.定义指针
d.做函数参数,返回值类型
三、枚举
1、定义:
如果一个变量只有几种可能的值,则可以定义为枚举类型。所谓“枚举”是指将变量的值一一列举出来,变量的值只限于列举出来的值的范围内。
2、关键字:
emum
3、格式:
enum 枚举类型名
{
sun, //名字 --- 代表一个整形值,不做定义的时候默认是从0依次向后定义 --- 符号常量
mon,
tue,
wed,
thu,
fri,
sat
};
练习:
无人机的状态
0 --flying
1 --stop
2 --holding
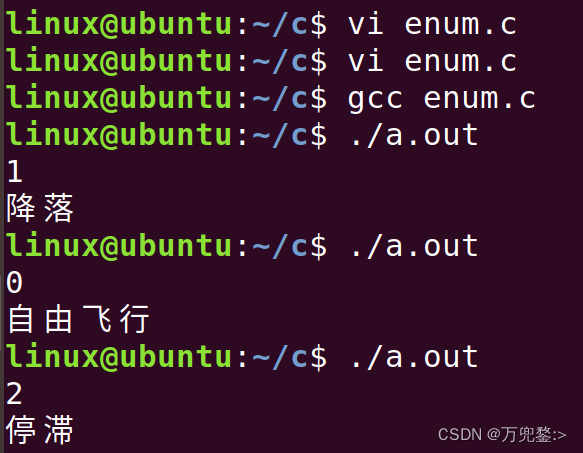
从键盘输入0~2 打印无人机的状态
#include
enum plan
{
flaying,
// flaying = 1; //这里不是赋值,是指定他是什么整形常量,不写默认为0而后后边的依次按顺序默认定义,写了就按照此时定义好的值依次按顺序定义
stop,
holding
};
int main()
{
// falying = 1; //error flaying是整形常量,不能赋值
int i = 0;
scanf("%d",&i);
switch(i)
{
case flaying:
// case 0: //or
printf("自由飞行\n");
break;
case stop:
// case 1: //or
printf("降落\n");
break;
case holding:
// case 2: //or
printf("停滞\n");
break;
default:
printf("重新输入0-2以内的数字\n");
}
return 0;
}
4、注意:
1.枚举 提高了代码可读性
2.枚举 本质上是int类型
枚举 与 整型 类型兼容
3.不足
因为枚举类型 --- 本质上是个整型类型,
所以枚举类型的变量的值,并不能真正限定在指定的哪些值范围中
4.枚举类型
可以做函数 形参 和 返回值
定义数组也可以,本质上就是整型数据
四、链表( C语言阶段:有头单向链表 )
数组:
int a[10] = {1,2,3,4,5,6,7,8,9,10}; //连续性,有序性,单一性
数组的优点:随机访问 方便
数组的缺点:增加数据 不方便
删除数据 不方便

1、链表的定义:
链式的数据表
2、链表的特点:
链表的优点:增加,删除数据很方便
链表的缺点:找数据不大方便
3、节点:
存放链式数据的结构:节点
节点的形式:[数据|另外一个节点指针] ---- [数据域|指针域]
节点举例:
struct Node
{
//数据域
struct stu s;
//指针域
struct Node *p; //指针类型
};
4、链表的种类与空链表:
有头链表 -- 可以更方便的处理链表
无头链表
空链表的特点:
只有头节点
并且头节点的指针域为NULL //相当于是尾节点
strcut Node head = {0,NULL}; //创建了一个头节点
struct Node *p = &head; //取头结点的地址
5、列表的插入
插入: 创建一个新的节点,将节点链接起来
方式一:尾插
思路:
s1.创建一个新的节点
struct Node *pNew = malloc(sizeof(struct Node));
//放在了堆区
s2.找到尾节点
struct Node *p = &head; //此时p在头节点
while( p->next != NULL )
{
p = p->next; //让p指向下一个节点
}
s3.链接到尾节点后面
p->next = pNew;
pNew->next = NULL; //尾节点
代码:
void pushBack(struct Node *head)
{
s1.创建一个新的节点
struct Node *pNew = malloc(sizeof(struct Node));
//放在了堆区
//
s2.找到尾节点
struct Node *p = head; //此时p在头节点
while( p->next != NULL )
{
p = p->next; //让p指向下一个节点
}
s3.链接到尾节点后面
p->next = pNew;
pNew->next = NULL; //尾节点
}
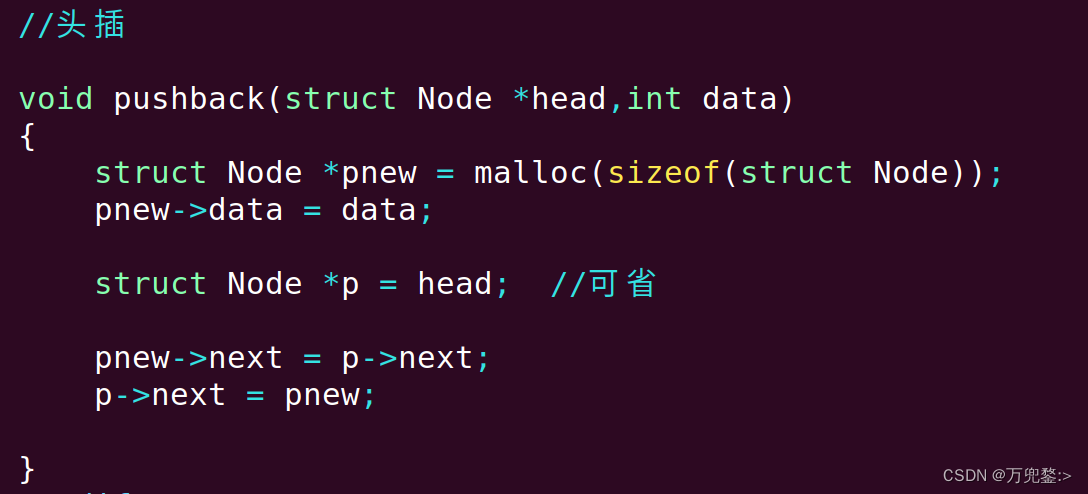
方式二:头插
void pushFront(struc Node *head,int data)
{
//1.创建新节点
pNew
//2.链接
pNew->next = p->next;
p->next = pNew;
}
int length(struct Node *head)
{
//统计有效节点的个数
}
6、链表的删除:
方式一:头删
void popFront(struct Node *head)
{
//1.p指针变量 指向首节点
//2.断开链表
head->next = p->next;
//3.释放p所在的节点
free(p);
}

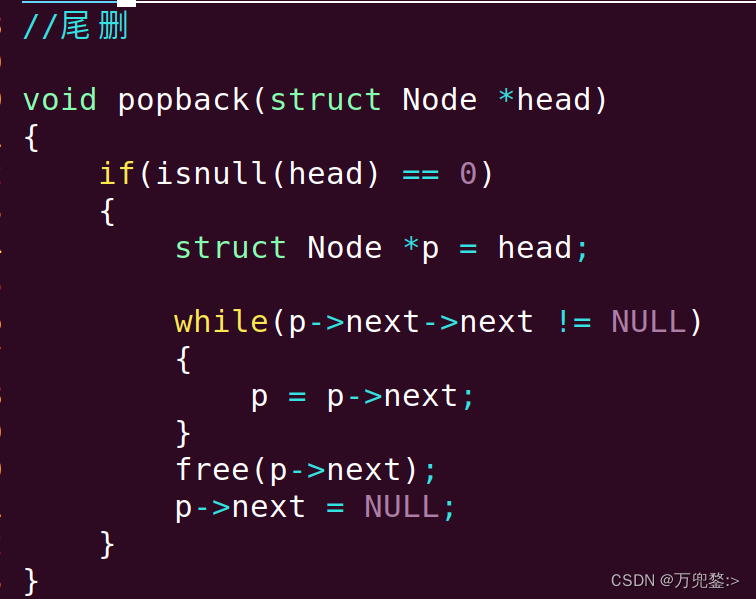
方式二:尾删
void void popBack(struct Node *head)
{
//1.p定位到尾节点的前一个节点
while (p->next->next != NULL)
{
p = p->next;
}
//2.释放 p->next
//3.p所在节点成为了新的尾节点
p->next = NULL;
}
操作:
1.创建空链表
2.头插
3.尾插
4.链表遍历
5.链表的长度







