

说明
随便找了一批车道线的图片数据制作图森数据集(tusimple),tusimple数据集LaneNet模型的标准数据集,便于后期实现基于LaneNet模型的车道线检测。
内容写的太详细,太细节,所以看上去可能会有一点多或者乱,感谢大家留下宝贵的意见。
一、数据标注
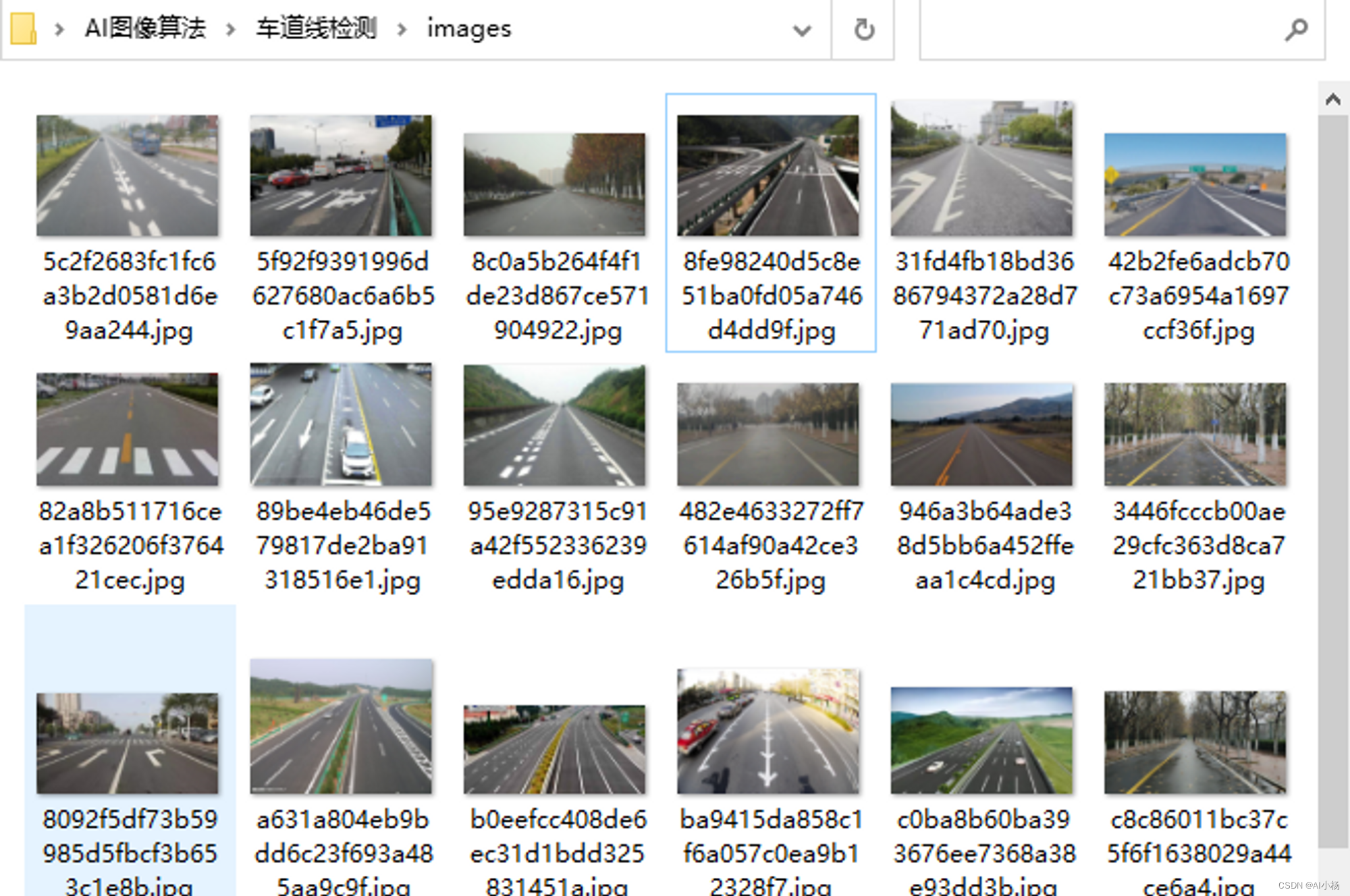
1、数据样式
因为后期要实现的是车道线检测功能,所有数据如下:
2、数据标注
数据标注使用的是labelme标注工具,labelme:
pip install labelme
labelme标注工具的安装就不详细介绍了,我在此篇文章中有详细介绍:labelme工具安装与使用
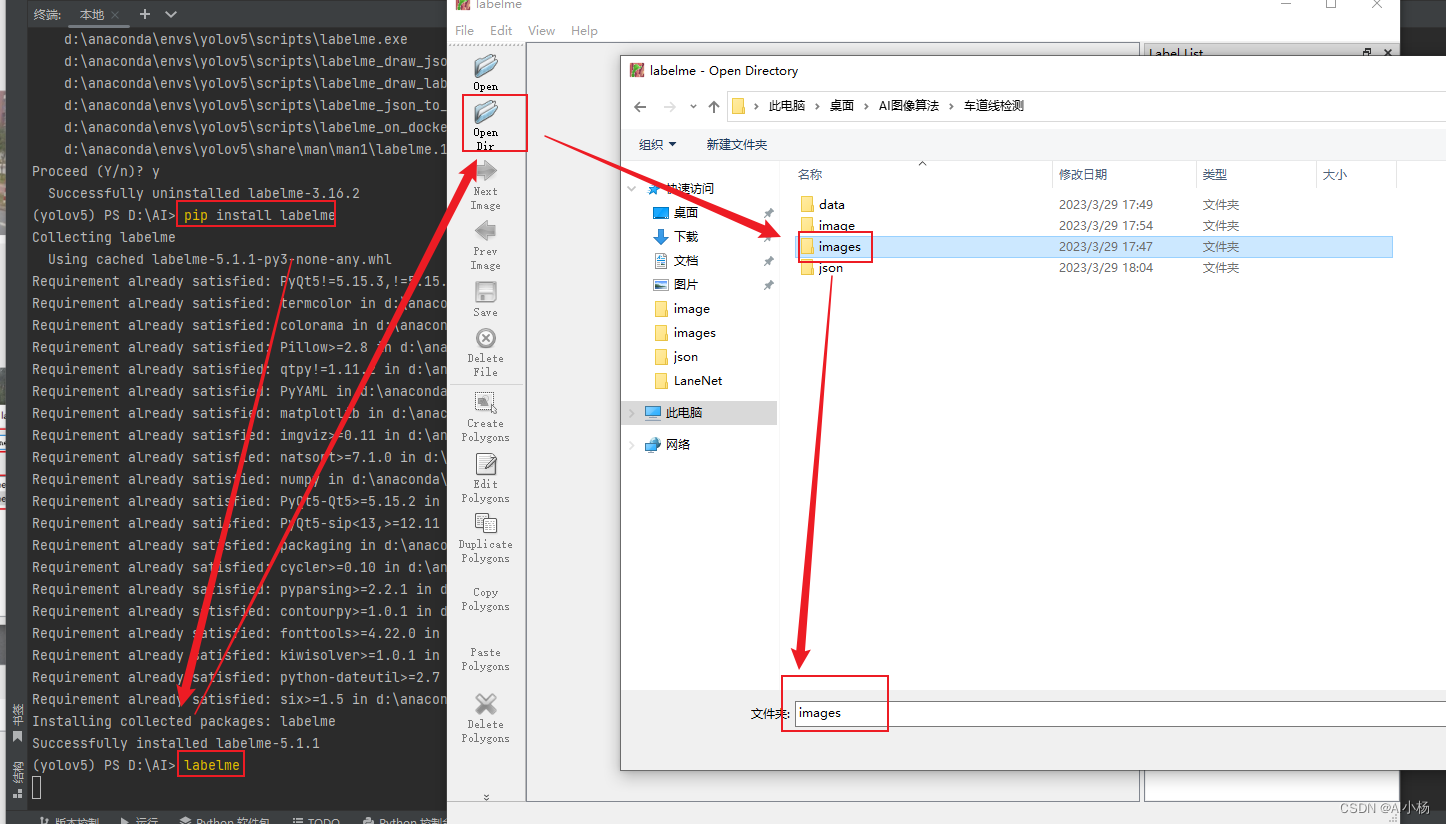
在终端中输入labelme启动标注工具,加载需要标注的图片:
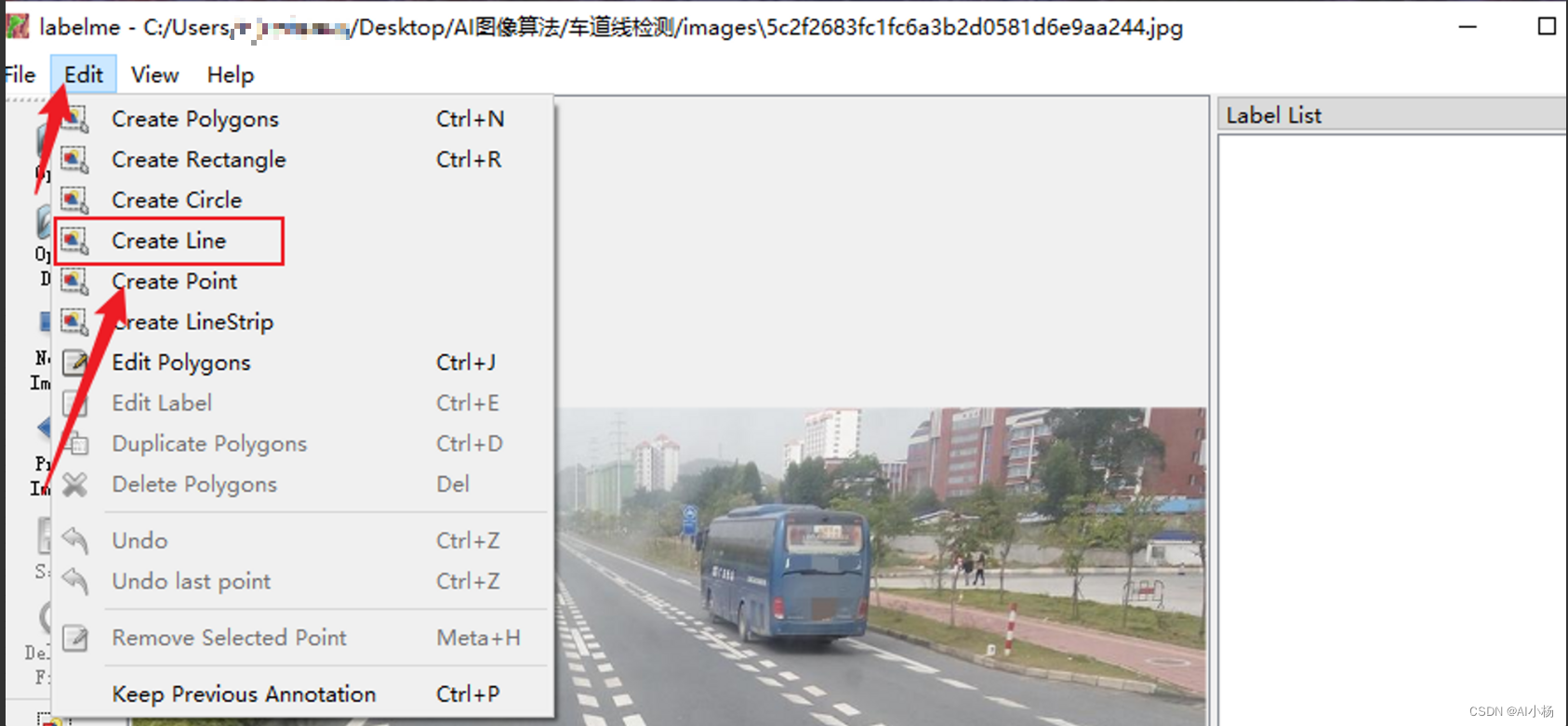
选择标注框,因为是车道线标注,所以选择Create Line:
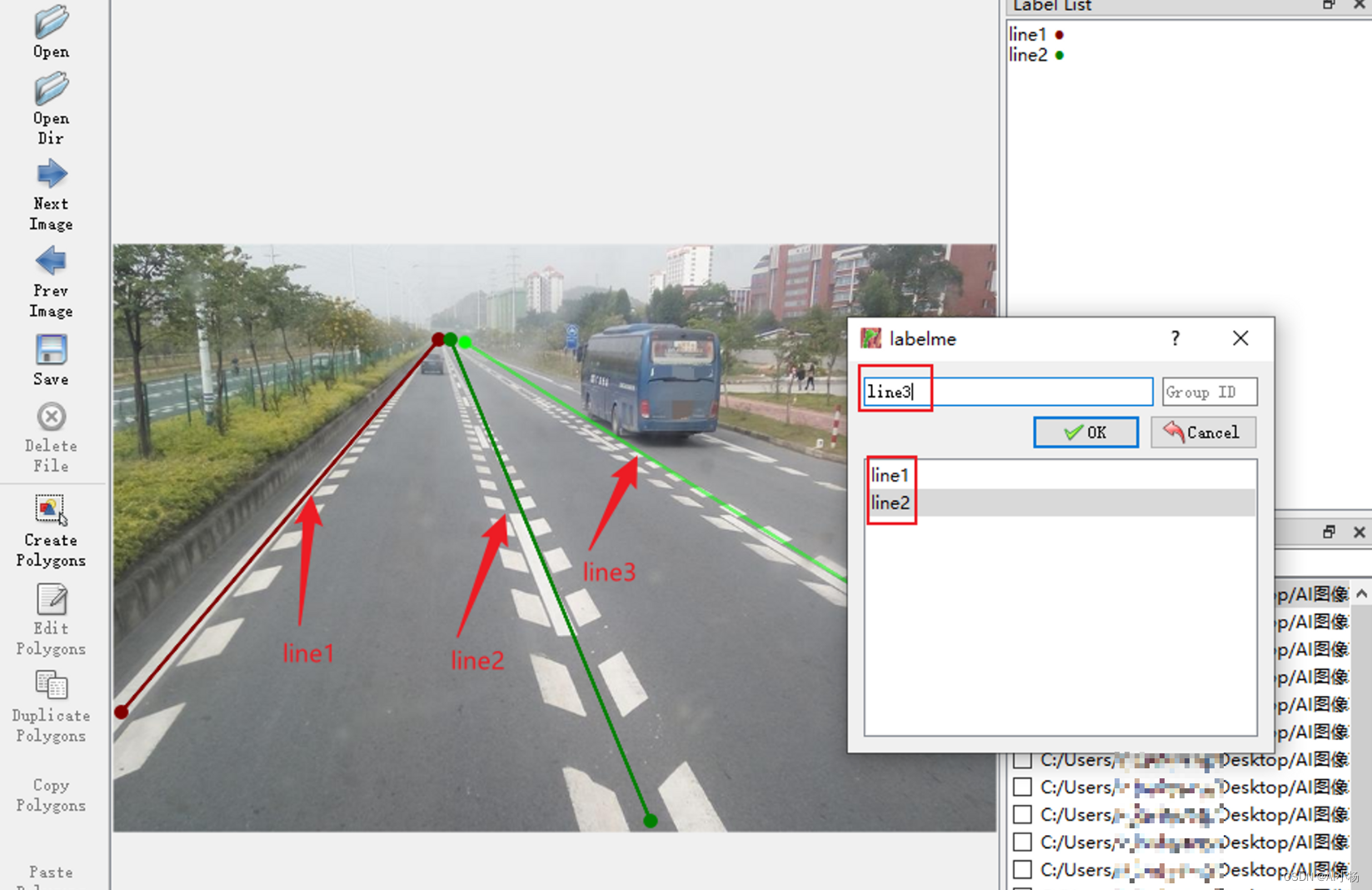
进行标注,第一条车道线标签值为line1,以此类推line2、line3、…linen:
一直进行标注,直到全部标注完成,退出:
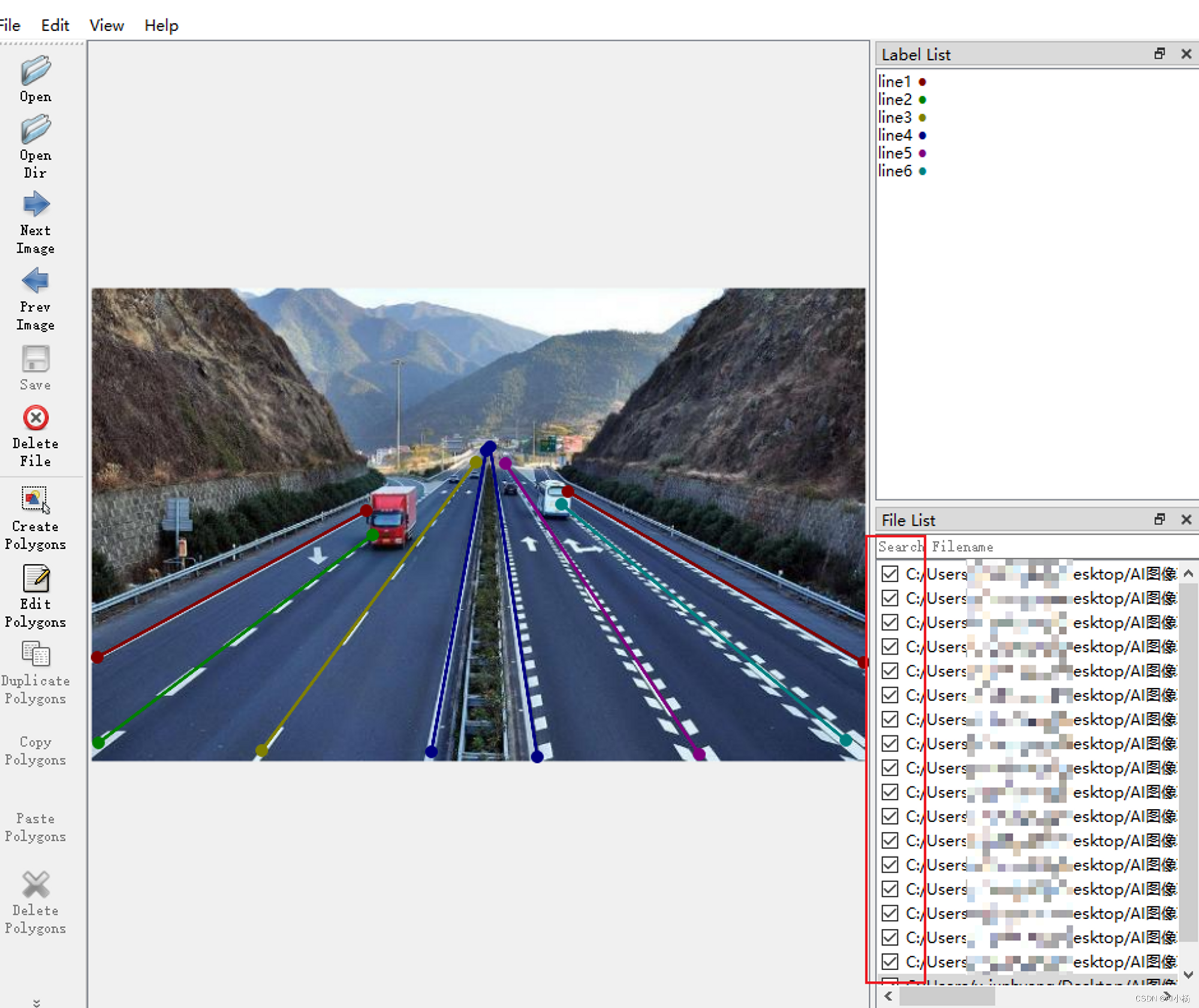
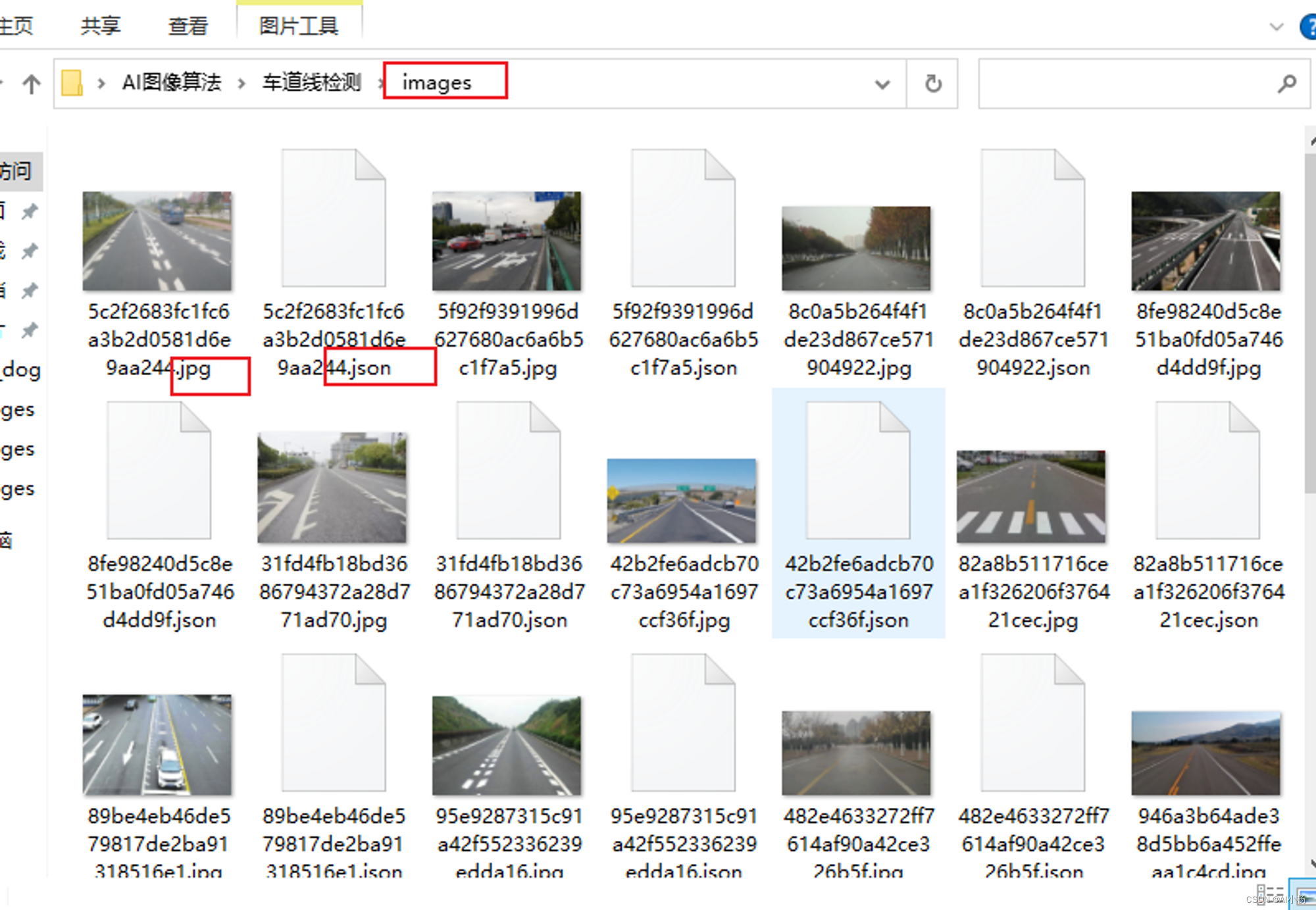
此时,标注的图片的目录下生成了图片标注对应结果的json格式的文件:
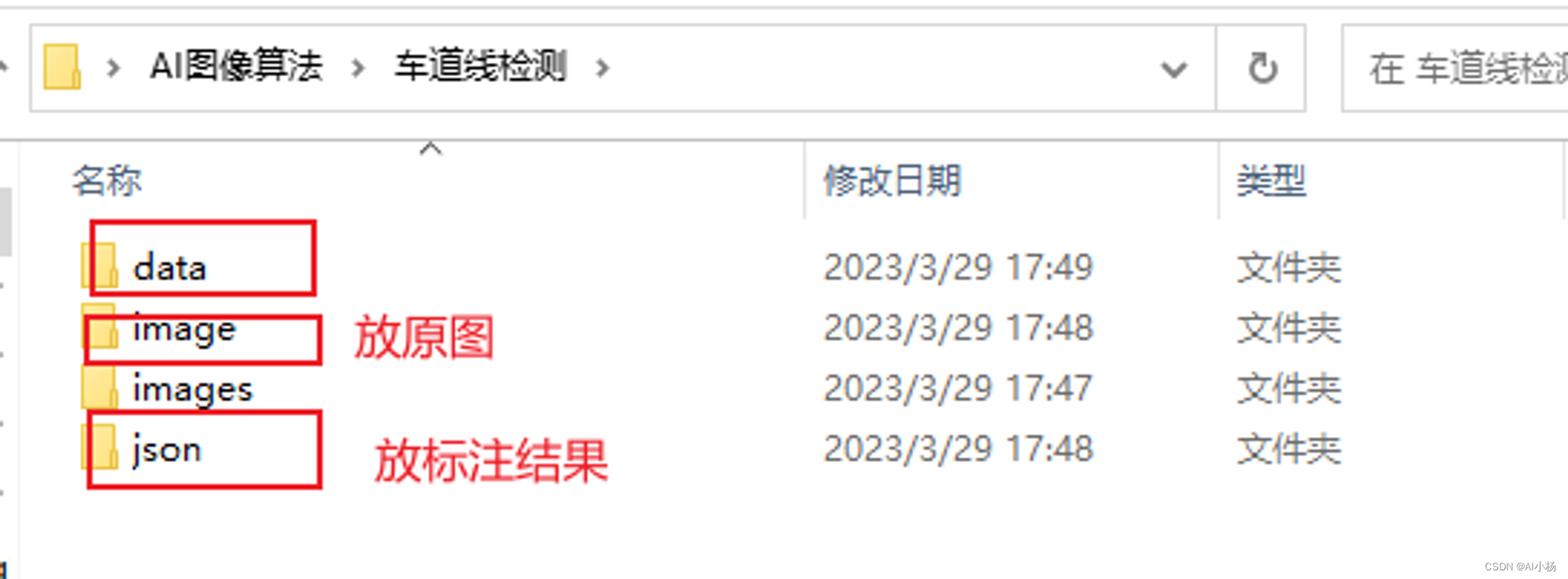
创建这几个文件夹方便完成后续操作(跟着自己的想法来,随便创建)
二、提取指定格式文件
1、分别提取原图和标注结果到指定文件夹
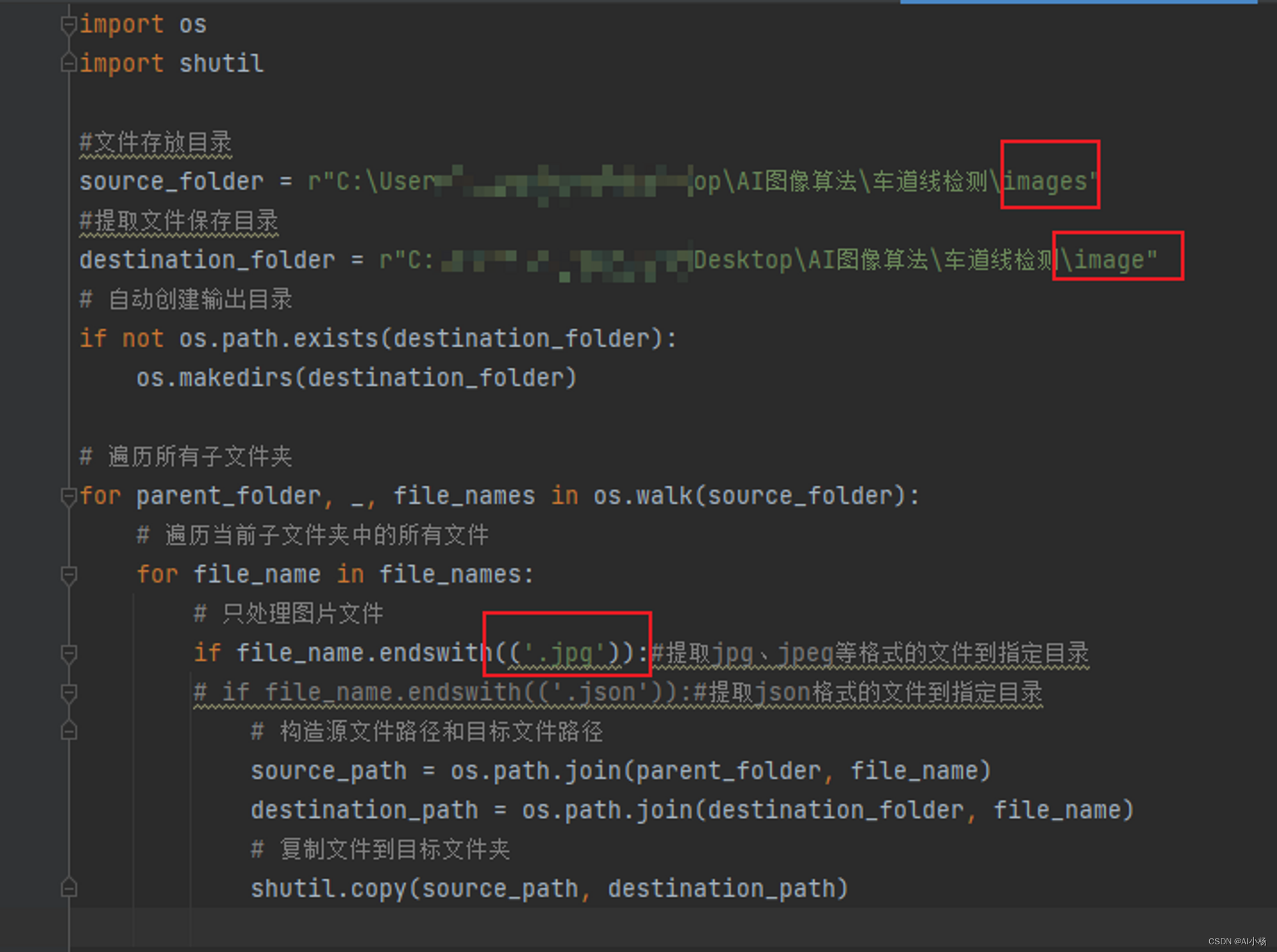
代码如下:
import os
import shutil
#文件存放目录
source_folder = r"C:\Users\xxx\Desktop\AI图像算法\车道线检测\images"
#提取文件保存目录
destination_folder = r"C:\Users\xxx\Desktop\AI图像算法\车道线检测\image"
# 自动创建输出目录
if not os.path.exists(destination_folder):
os.makedirs(destination_folder)
# 遍历所有子文件夹
for parent_folder, _, file_names in os.walk(source_folder):
# 遍历当前子文件夹中的所有文件
for file_name in file_names:
# 只处理图片文件
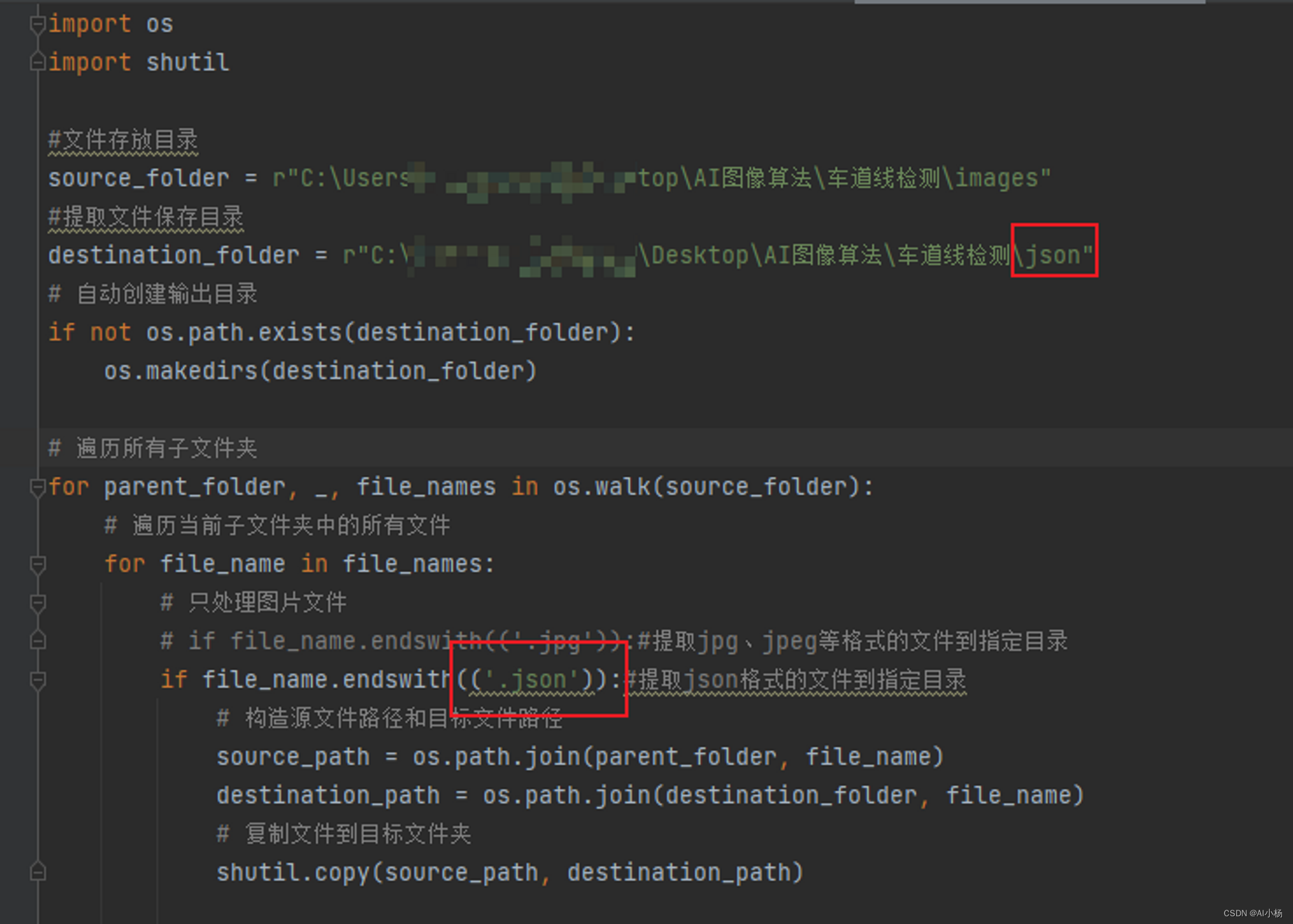
if file_name.endswith(('.jpg')):#提取jpg、jpeg等格式的文件到指定目录
# if file_name.endswith(('.json')):#提取json格式的文件到指定目录
# 构造源文件路径和目标文件路径
source_path = os.path.join(parent_folder, file_name)
destination_path = os.path.join(destination_folder, file_name)
# 复制文件到目标文件夹
shutil.copy(source_path, destination_path)
(1)提取图片
- 运行代码截图如下:
第一个框是原文件夹,第二个框是图片保存的指定文件夹,第三个框是指定提取文件的格式为jpg格式
- 提取结果:
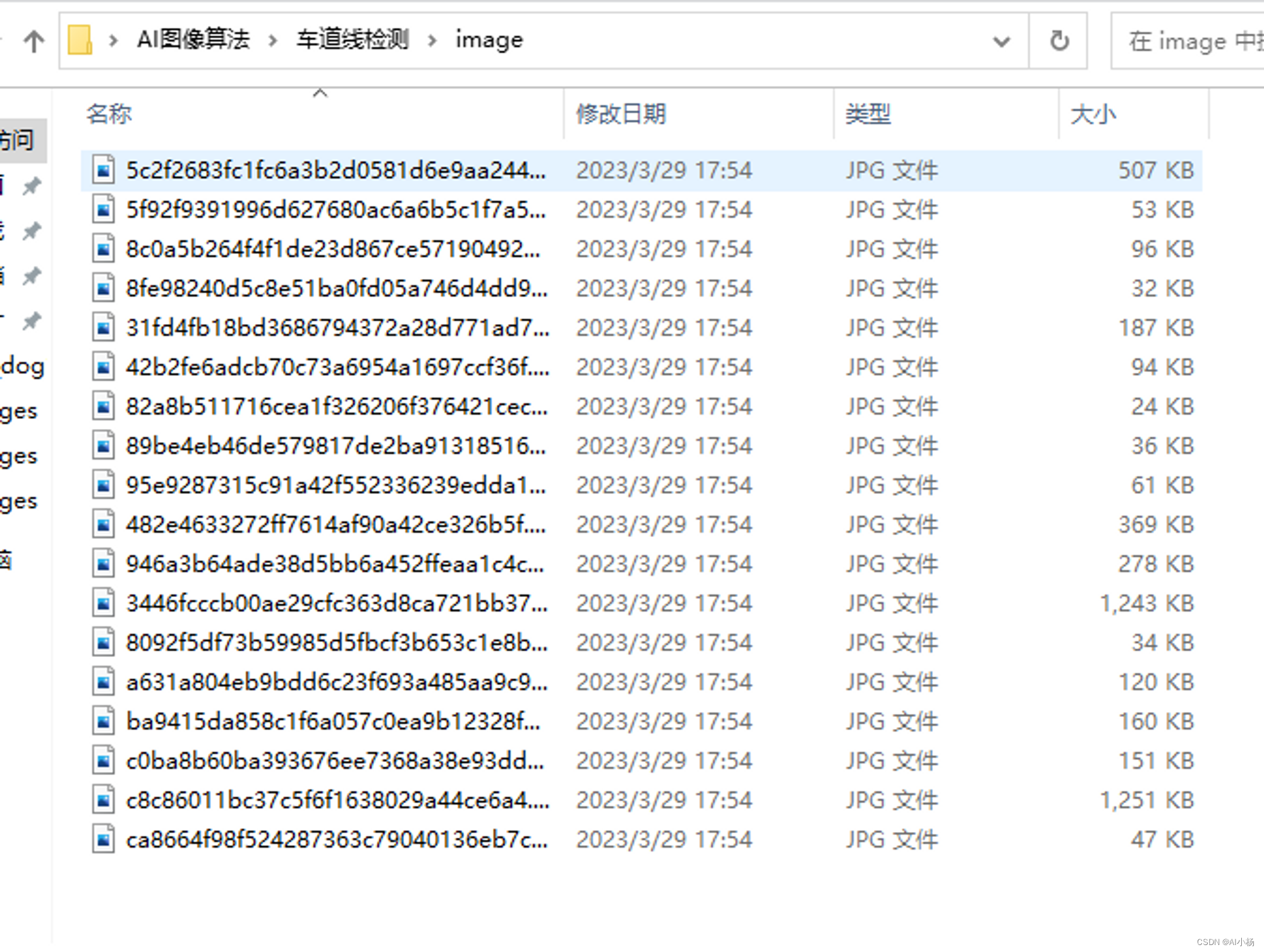
(2)提取标注结果(json格式的文件)
跟上面同理就不做过多赘述:
- 运行截图
- 提取结果:
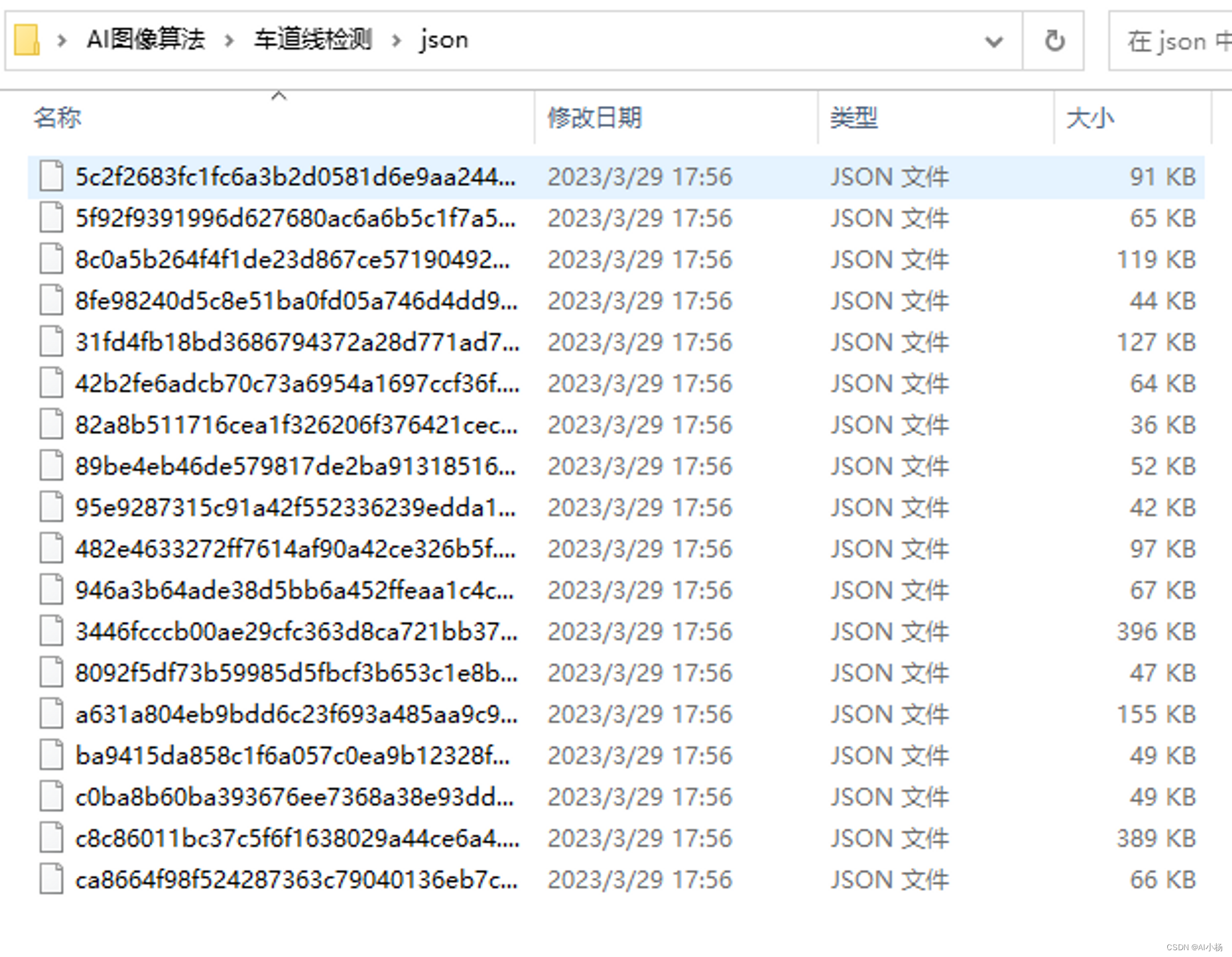
三、labelme批量处理json文件
labelme使用(labelme_json_to_dataset)批量处理json文件(Labelme 批量转 dataset)
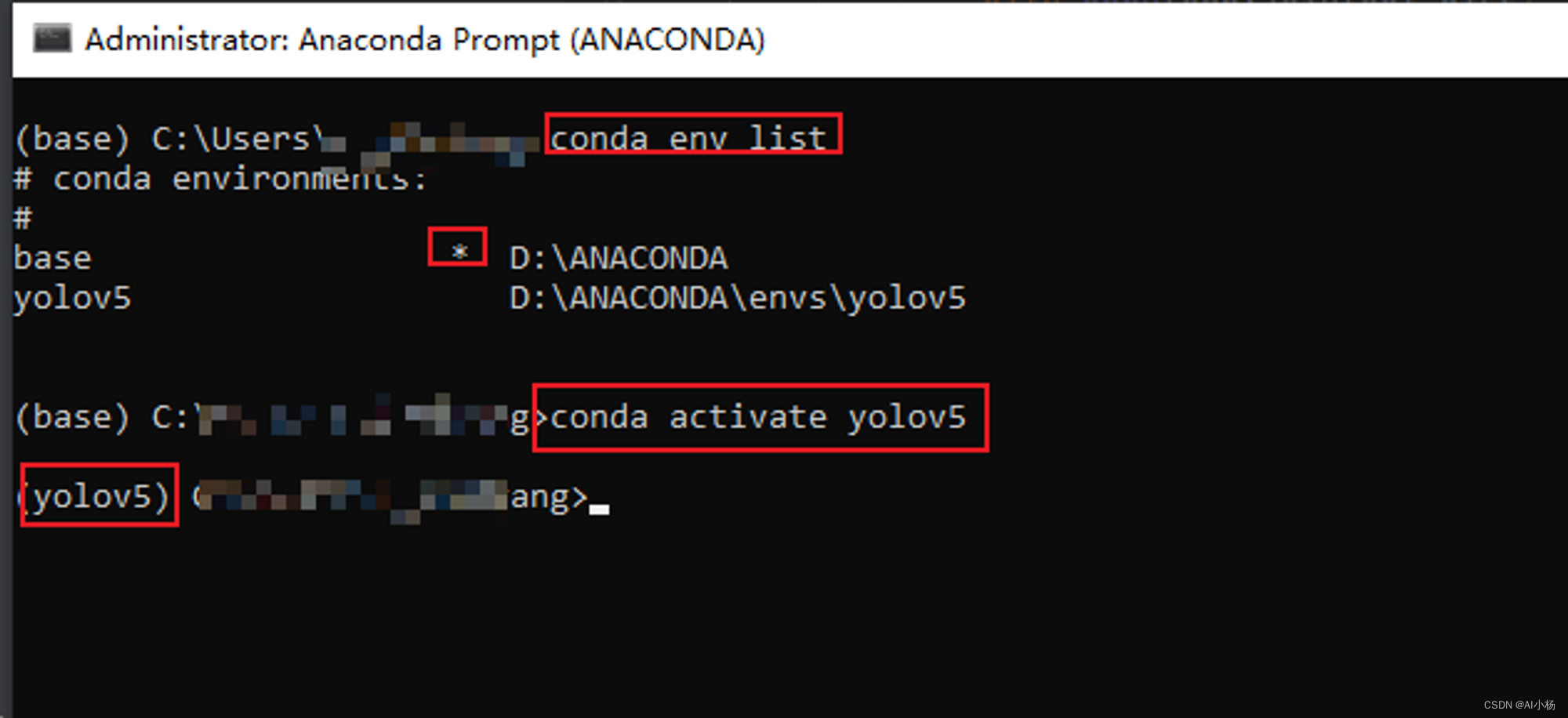
查看pycharm终端中labelme所在的环境:
进入yolov5环境所在的文件夹目录下下,如下图所示找到json_to_dataset.py文件:
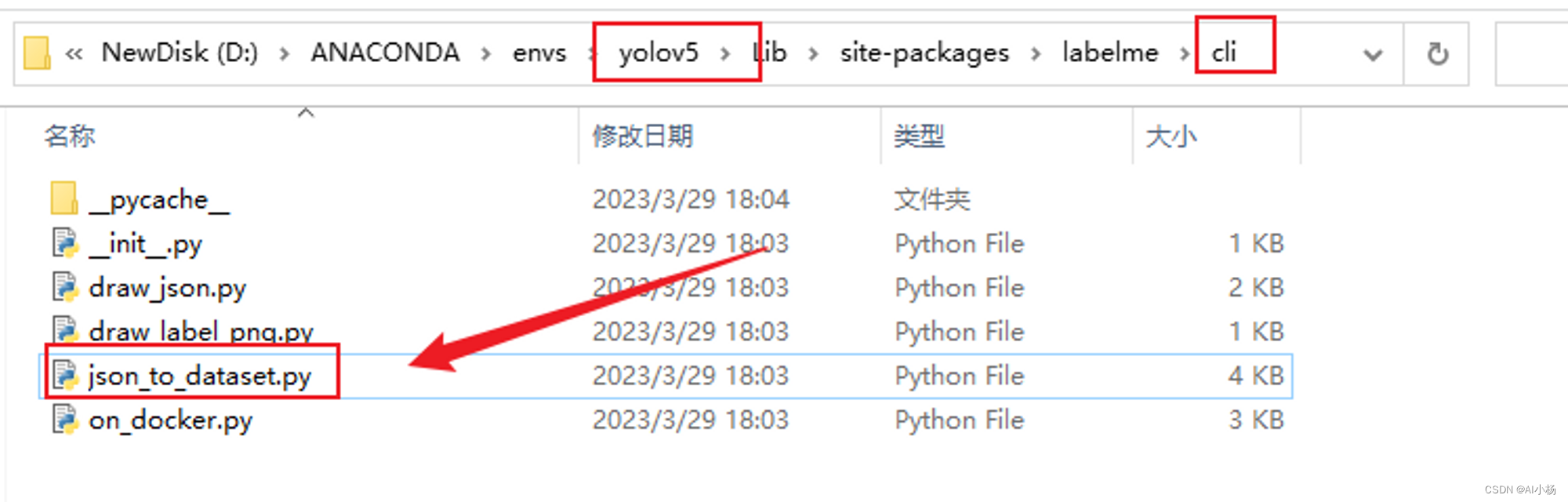
打开此文件,json_to_dataset.py文件里面是实现单个处理的,如果要实现批量处理,则用下面代码,把里面的代码全部替换为如下代码,:
Pythonimport argparse import json import os import os.path as osp import warnings import PIL.Image import yaml from labelme import utils import base64 import numpy as np from skimage import img_as_ubyte def main(): warnings.warn("This script is aimed to demonstrate how to convert the\n" "JSON file to a single image dataset, and not to handle\n" "multiple JSON files to generate a real-use dataset.") parser = argparse.ArgumentParser() parser.add_argument('json_file') parser.add_argument('-o', '--out', default=None) args = parser.parse_args() json_file = args.json_file count = os.listdir(json_file) for i in range(0, len(count)): path = os.path.join(json_file, count[i]) if os.path.isfile(path): data = json.load(open(path)) ############################## # save_diretory out_dir1 = osp.basename(path).replace('.', '_') save_file_name = out_dir1 out_dir1 = osp.join(osp.dirname(path), out_dir1) if not osp.exists(json_file + '\\' + 'labelme_json'): os.mkdir(json_file + '\\' + 'labelme_json') labelme_json = json_file + '\\' + 'labelme_json' out_dir2 = labelme_json + '\\' + save_file_name if not osp.exists(out_dir2): os.mkdir(out_dir2) ######################### if data['imageData']: imageData = data['imageData'] else: imagePath = os.path.join(os.path.dirname(path), data['imagePath']) with open(imagePath, 'rb') as f: imageData = f.read() imageData = base64.b64encode(imageData).decode('utf-8') img = utils.img_b64_to_arr(imageData) label_name_to_value = {'_background_': 0} for shape in data['shapes']: label_name = shape['label'] if label_name in label_name_to_value: label_value = label_name_to_value[label_name] else: label_value = len(label_name_to_value) label_name_to_value[label_name] = label_value # label_values must be dense label_values, label_names = [], [] for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]): label_values.append(lv) label_names.append(ln) assert label_values == list(range(len(label_values))) lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value) captions = ['{}: {}'.format(lv, ln) for ln, lv in label_name_to_value.items()] lbl_viz = utils.draw_label(lbl, img, captions) PIL.Image.fromarray(img).save(out_dir2 + '\\' + save_file_name + '_img.png') # PIL.Image.fromarray(lbl).save(osp.join(out_dir2, 'label.png')) utils.lblsave(osp.join(out_dir2, save_file_name + '_label.png'), lbl) PIL.Image.fromarray(lbl_viz).save(out_dir2 + '\\' + save_file_name + '_label_viz.png') with open(osp.join(out_dir2, 'label_names.txt'), 'w') as f: for lbl_name in label_names: f.write(lbl_name + '\n') warnings.warn('info.yaml is being replaced by label_names.txt') info = dict(label_names=label_names) with open(osp.join(out_dir2, 'info.yaml'), 'w') as f: yaml.safe_dump(info, f, default_flow_style=False) # save png to another directory if not osp.exists(json_file + '\\' + 'mask_png'): os.mkdir(json_file + '\\' + 'mask_png') mask_save2png_path = json_file + '\\' + 'mask_png' utils.lblsave(osp.join(mask_save2png_path, save_file_name + '_label.png'), lbl) print('Saved to: %s' % out_dir2) if __name__ == '__main__': main()进入anaconda Prompt工具:
进入yolov5环境:
运行如下代码实现批量处理:
Pythonlabelme_json_to_dataset xxx/xxx/json#标注结果json文件所在的目录比如说我在这个目录:
我的执行代码如下:
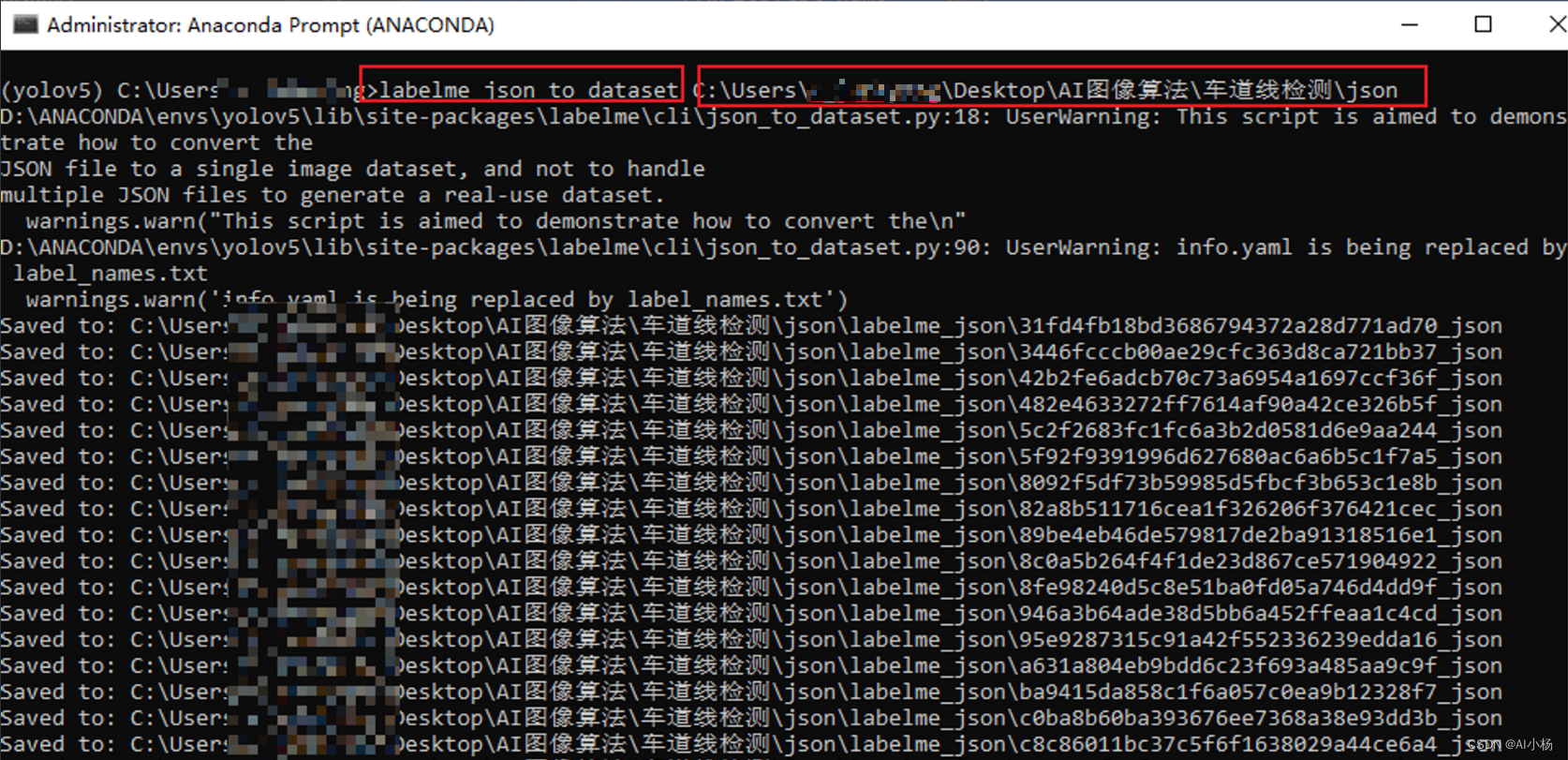
注意,如果此处报错为:
AttributeError: module ‘labelme.utils’ has no attribute ‘draw_label’
则移步到此处解决:解决方案
运行完成后,会在json文件所在的文件夹下生成两个文件夹:labelme_json和mask_png:
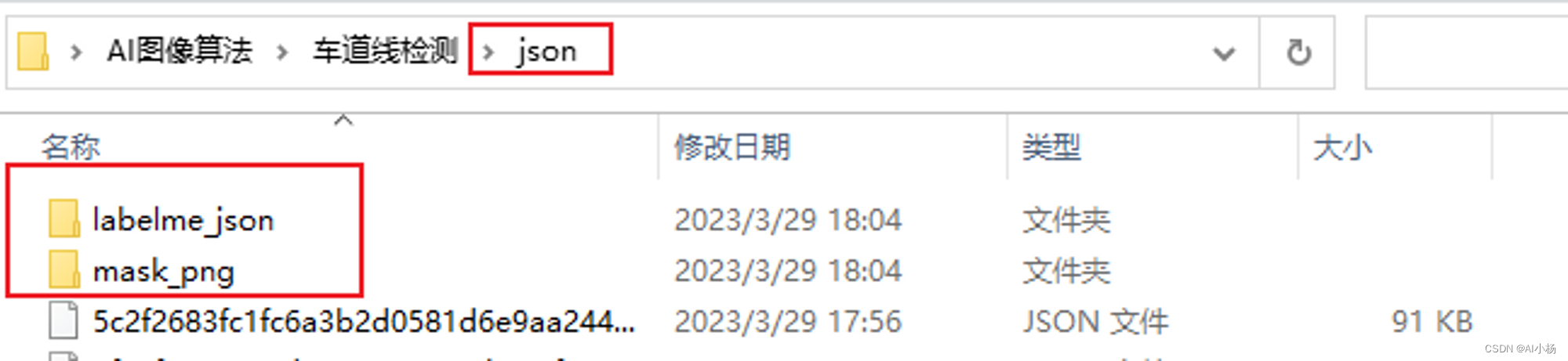
两个文件夹下的内容分别如下:
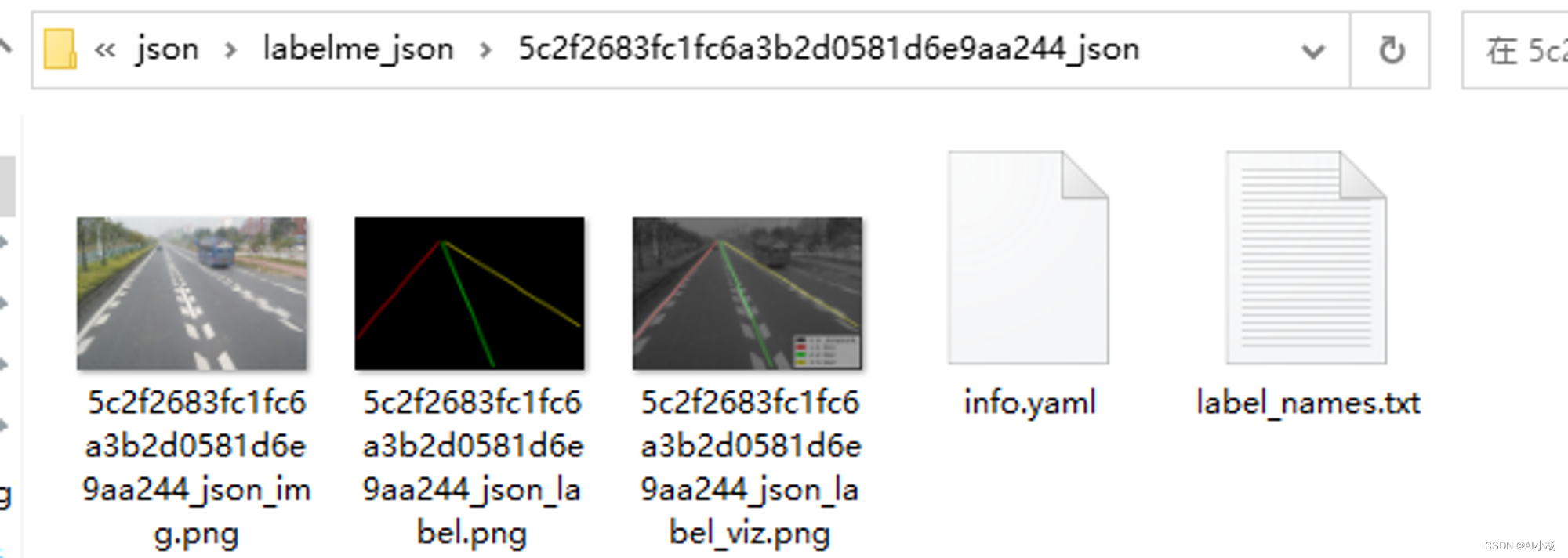
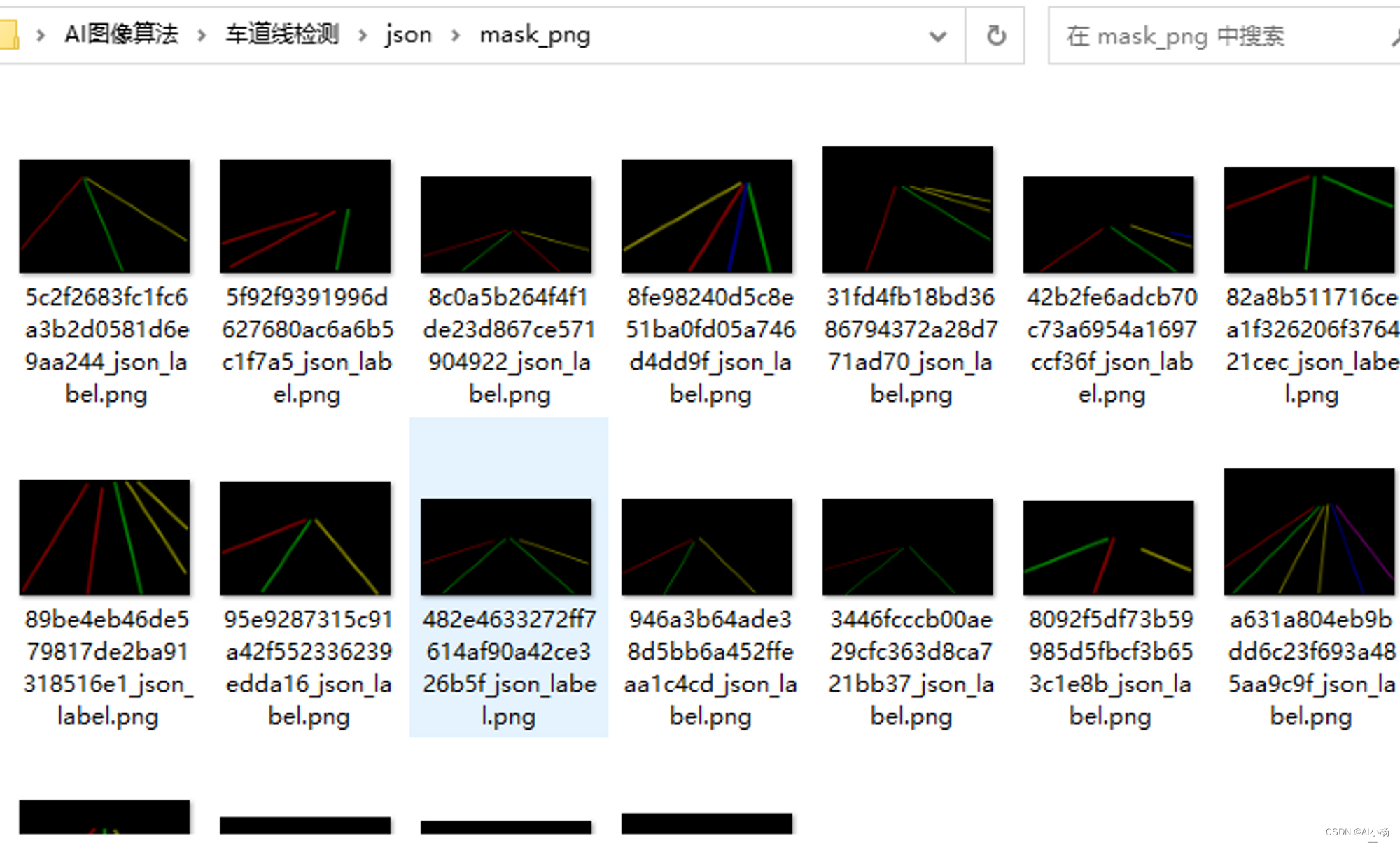
进入labelme_json文件夹下复制粘贴所有文件:
复制到上面事先准备好的data/datset/annotations文件夹下:
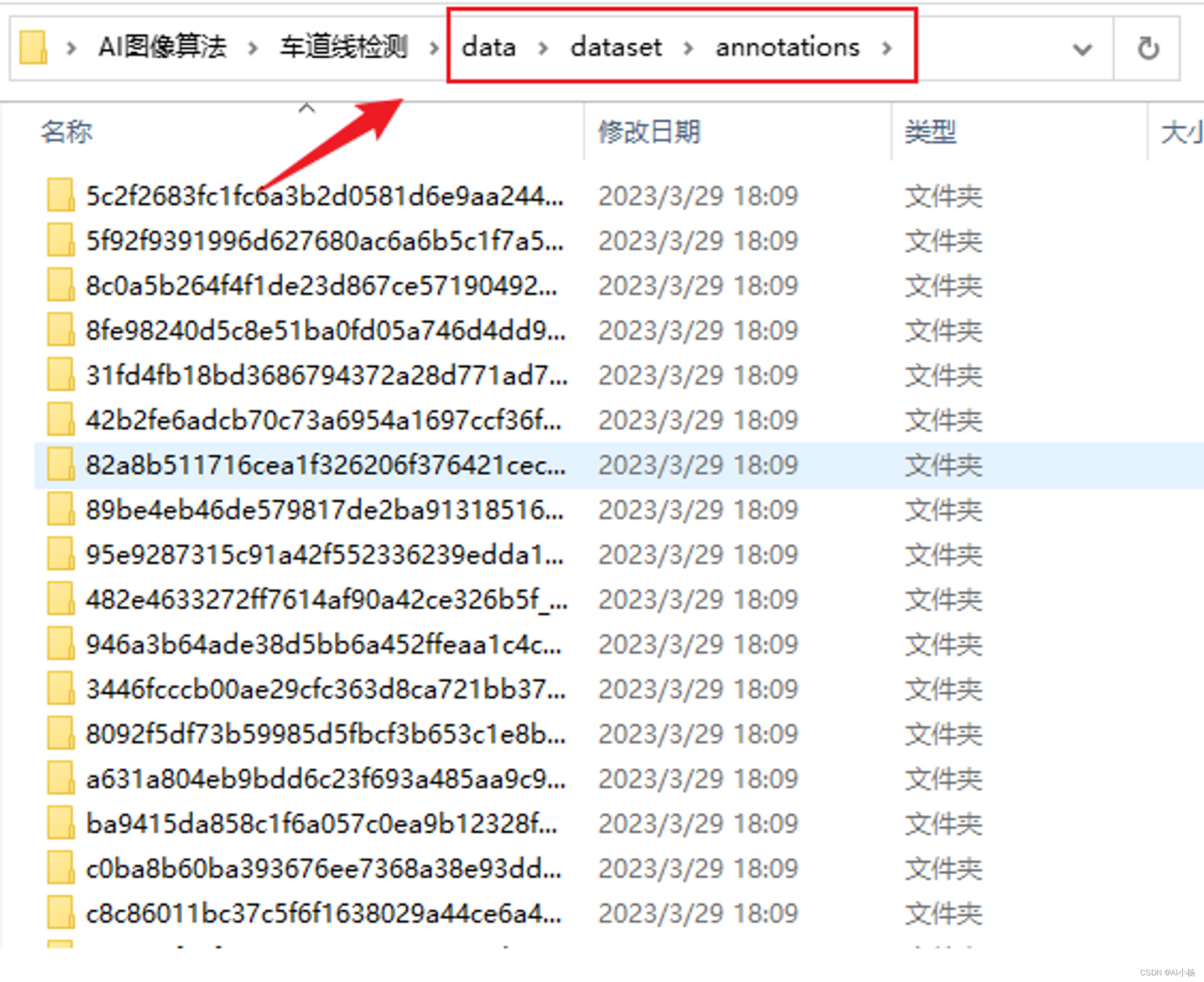
四、tusimple数据集处理
代码如下:
Pythonimport cv2 from skimage import measure, color from skimage.measure import regionprops import numpy as np import os import copy def skimageFilter(gray): binary_warped = copy.copy(gray) binary_warped[binary_warped > 0.1] = 255 gray = (np.dstack((gray, gray, gray)) * 255).astype('uint8') labels = measure.label(gray[:, :, 0], connectivity=1) dst = color.label2rgb(labels, bg_label=0, bg_color=(0, 0, 0)) gray = cv2.cvtColor(np.uint8(dst * 255), cv2.COLOR_RGB2GRAY) return binary_warped, gray def moveImageTodir(path, img_name, targetPath, name): if os.path.isdir(path): image_name = "dataset/image/" + str(name) + ".png" binary_name = "dataset/gt_image_binary/" + str(name) + ".png" instance_name = "dataset/gt_image_instance/" + str(name) + ".png" os.makedirs("dataset/image/", exist_ok=True) os.makedirs("dataset/gt_image_binary/", exist_ok=True) os.makedirs("dataset/gt_image_instance/", exist_ok=True) train_rows = image_name + " " + binary_name + " " + instance_name + "\n" origin_img = cv2.imread(path + f"/{img_name}_img.png") origin_img = cv2.resize(origin_img, (1280, 720)) cv2.imwrite(targetPath + "/" + image_name, origin_img) img = cv2.imread(path + f'/{img_name}_label.png') img = cv2.resize(img, (1280, 720)) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) binary_warped, instance = skimageFilter(gray) cv2.imwrite(targetPath + "/" + binary_name, binary_warped) cv2.imwrite(targetPath + "/" + instance_name, instance) print("success create data name is : ", train_rows) return train_rows return None if __name__ == "__main__": count = 1 with open("./dataset/train.txt", 'w+') as file: for images_dir in os.listdir(r"C:\Users\xxx\Desktop\AI图像算法\车道线检测\data"): # images为待labelme标记的文件以及标记后转换的图片位置 dir_name = os.path.join(r"C:\Users\xxx\Desktop\AI图像算法\车道线检测\data", images_dir + "/annotations") # 这两个路径需要根据自己的存放的位置进行修改 for annotations_dir in os.listdir(dir_name): json_dir = os.path.join(dir_name, annotations_dir) if os.path.isdir(json_dir): train_rows = moveImageTodir(json_dir, annotations_dir, "./", str(count).zfill(4)) file.write(train_rows) count += 1创建.py文件,复制上面到改文件中,我的文件名为chul.py
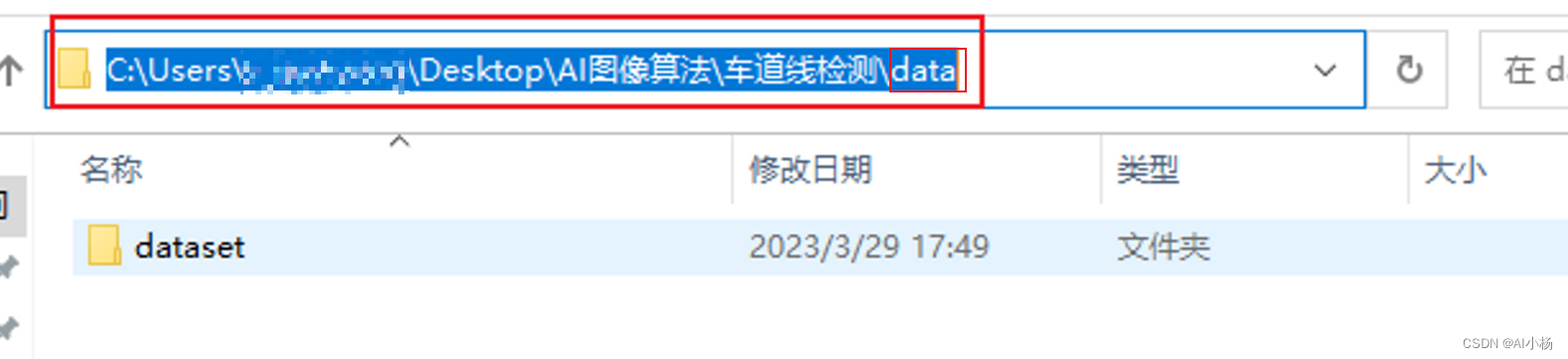
复制上面的data/datset/annotations路径,到data处:
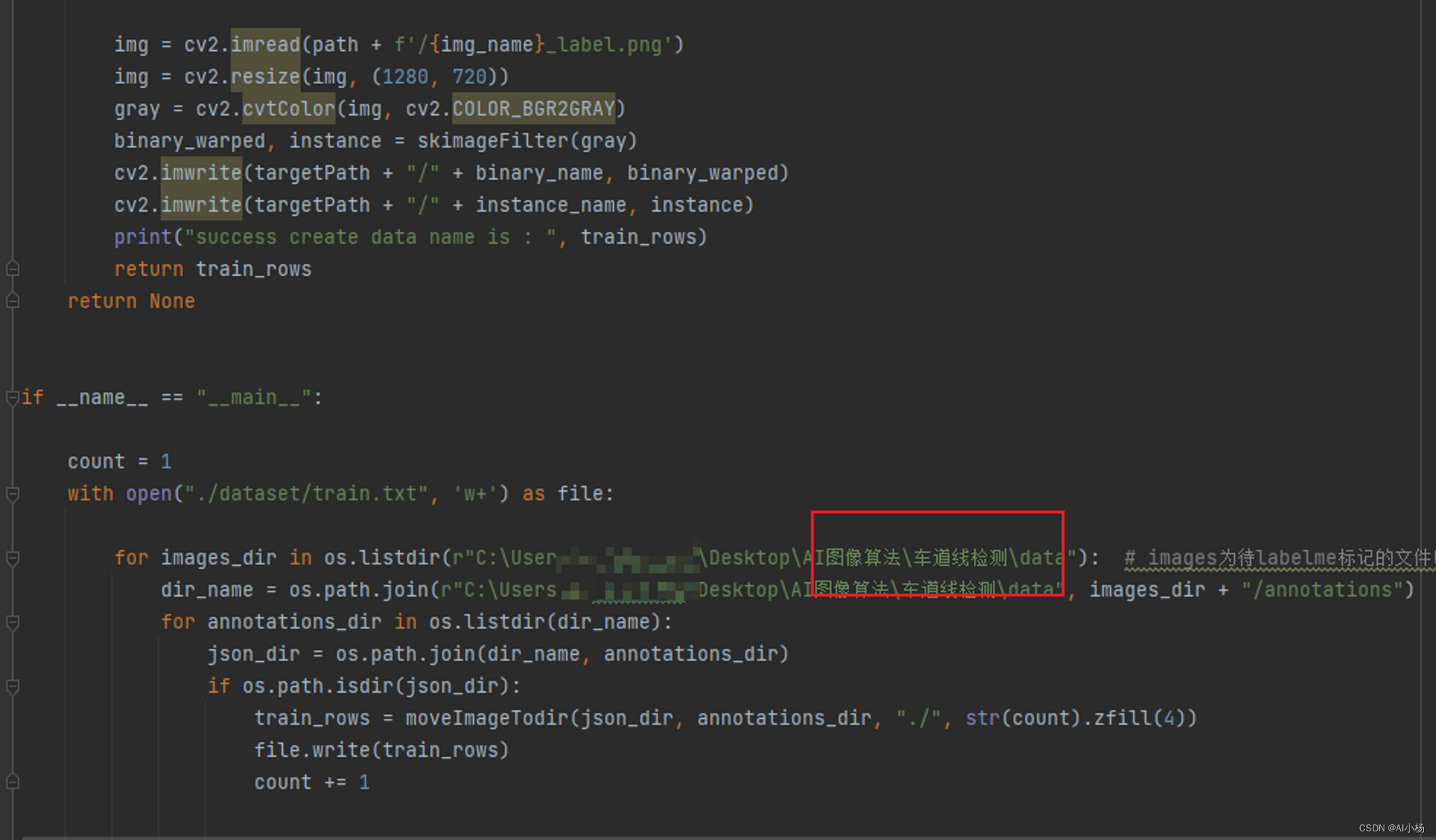
代码需要修改的位置:
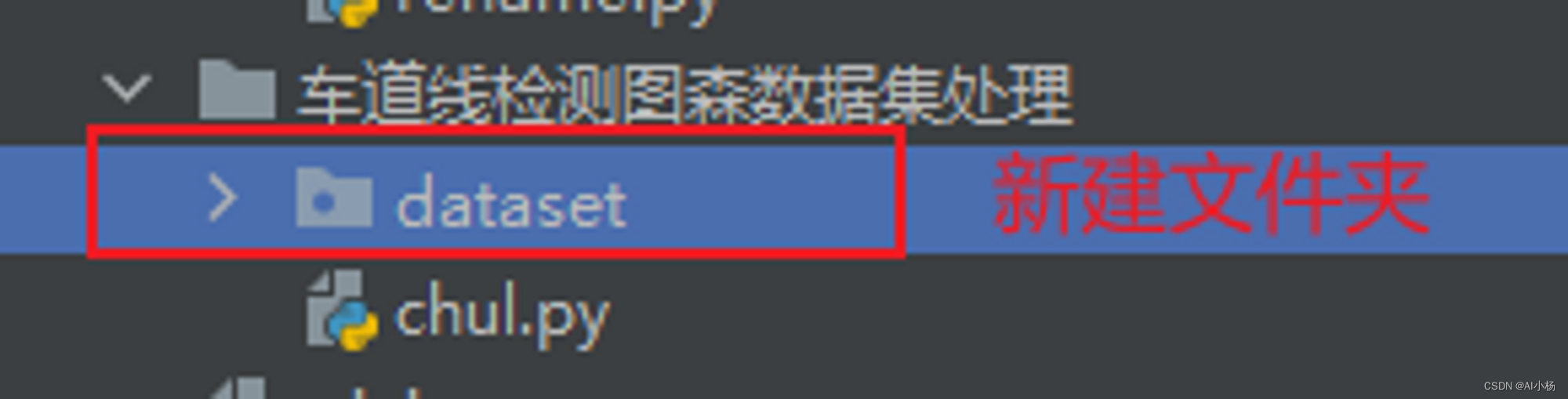
在chul.py文件的当前目录下创建dataset文件夹:
点击运行chul.py文件,在dataset目录下生成我们需要的数据集,如下:
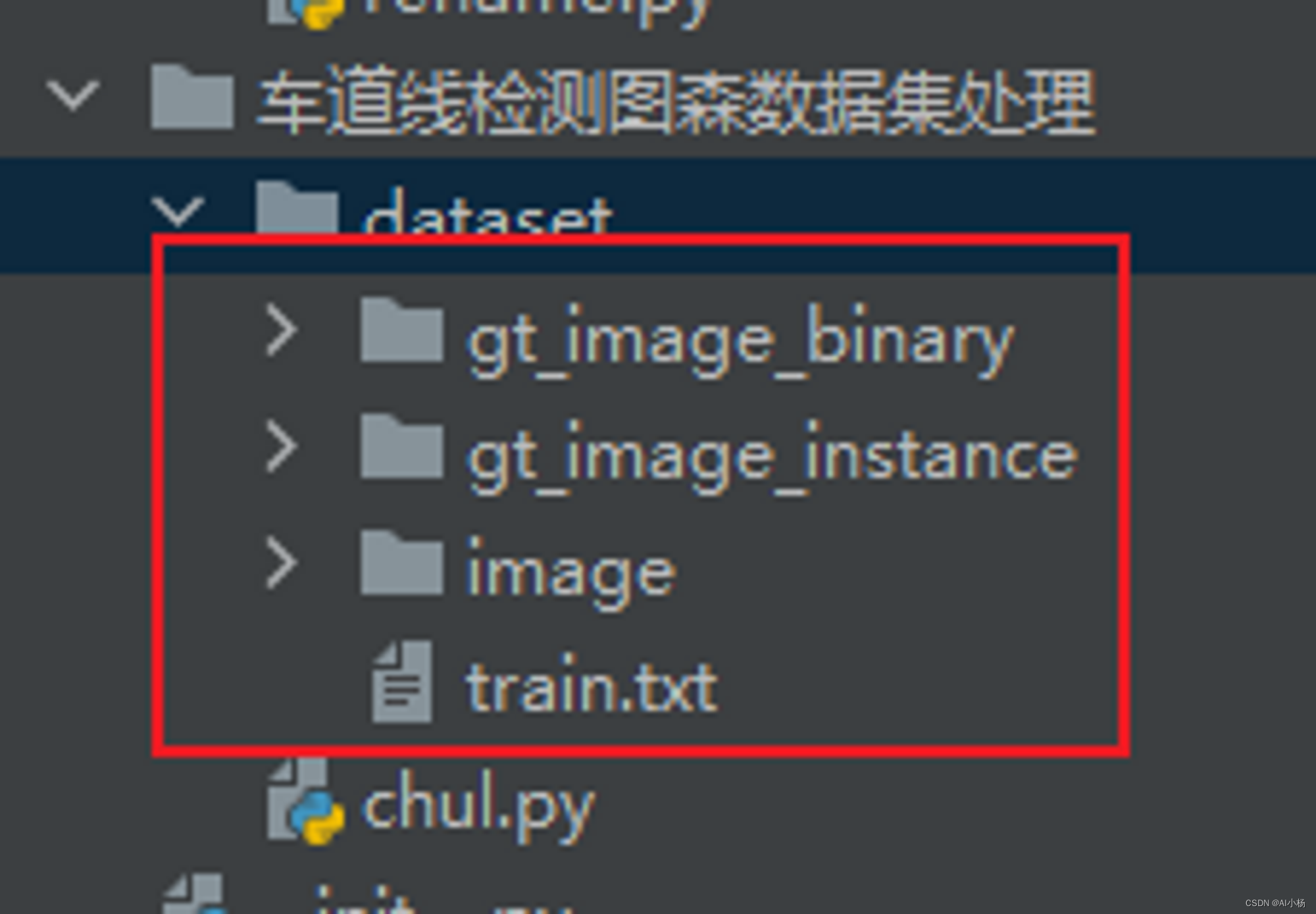
不过这个代码好像有一点bug,只生成了训练集的train.txt文件,没有生成验证集的val.txt,不过问题不大,我们可以自己创建一个val.txt文件,去train.txt中剪切一部分数据到val.txt中,比例大概按照训练集:验证集=7:2左右。
- 示例:
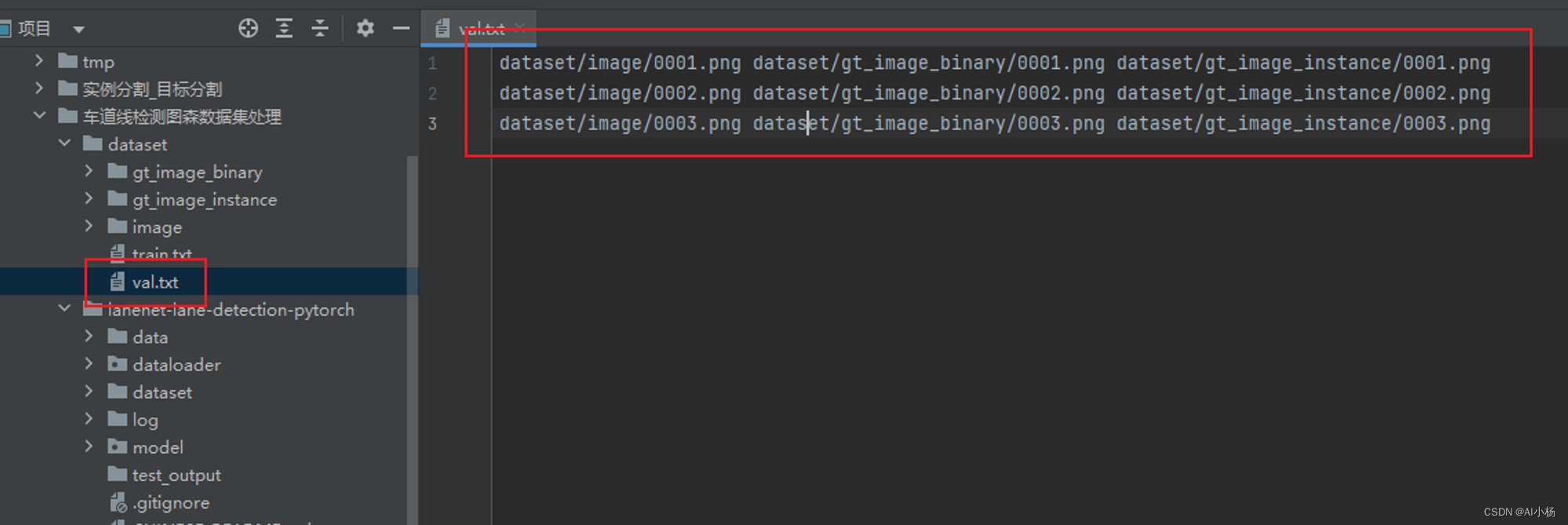
整个dataset文件夹就是我们需要的数据集。
至此,lanenet模型的标准数据集准备就绪,下期将基于lanenet模型的车道线检测实现。
欢迎大家提出宝贵的意见。
- 示例:
- 运行截图








