

一、 概述
對于企業和消費者來講,人工智能是非常有用的工具,那又該如何使用人工智能技術來保護敏感信息?通過快速處理數據并預測分析,AI可以完成從自動化系統到保護信息的所有工作。盡管有些黑客利用技術手段來達到自己的目的,但保護數據安全是人工智能技術的一個重要作用。我們越是利用人工智能技術來提供安全防護,就越有可能與高水準的黑客進行作戰。
人工智能在信息安全領域的應用十分廣泛,包括生物特征識别、漏洞檢測、惡意代碼分析等諸多方面。
基于生物特征的身份認證和訪問控制是目前人工智能技術應用最成功的信息安全領域。從前制約生物特征識别技術在信息安全領域應用的關鍵問題是漏報率與誤報率達不到實用要求。而利用以深度學習爲核心的人工智能技術,科研人員已經将人臉、語音、指紋等等生物特征的識别率大大提升。以人臉識别爲例,目前的準确率已經達到99%以上,技術的進步爲生物特征識别的應用打下了良好基礎。目前,已經有人臉支付等相關産品面世。支付領域的應用涉及社會和金融安全,在人臉識别的漏報、誤報和檢測準确率這些指标沒有大幅提升的前提下是不可想象的。
在信息安全中尤爲重要的漏洞檢測技術領域,目前還缺乏高效、準确的漏洞分析自動化技術,很多安全威脅和風險需要專業工作人員的經驗作深度的分析和最後的判斷。人工智能在處理海量數據方面極具優勢,通過對樣本的訓練可以模拟大量的攻擊模式,可以基于人類已有經驗也可以抛開人類經驗進行全新的樣本空間學習和探索,這樣的技術解決思路将大大提高漏洞檢測的全面性、準确性和時效性。
在惡意代碼檢測領域也是一樣。傳統的網絡安全技術應急響應速度慢,不能适應惡意代碼的叠代進化速度。而人工智能擁有強大的自主學習和數據分析能力,能夠加速響應的流程,提升自動化和響應效率,縮短從發現到響應的間隔。這就爲提前預知危險,及時預警并處理,将危險扼殺在搖籃中提供了可能,進而大大提高網絡安全防禦的敏捷性。

二、具體應用
2.1. 惡意代碼檢測
惡意代碼的數量和種類日趨增多,加上代碼迷惑技術的興起,使得檢測惡意代碼變得越來越困難。傳統的基于簽名的檢測技術被商業殺毒防毒軟件普遍使用,但是它必須要在獲取一類病毒的簽名之後才能有效的檢測這類病毒,而簽名一般都在感染後才被獲取。這個特點使得計算機系統受到惡意代碼威脅的可能性提高了。近年來,數據挖掘和機器學習技術應用于惡意代碼檢測領域,它之所以成爲研究的重點,是因爲它可以利用數據挖掘從已存在的大量代碼數據中挖掘出有意義的模式,利用機器學習可以幫助歸納出已知惡意代碼的識别知識,以此來進行相似性搜索,幫助發現未知惡意代碼。本文采用數據挖掘和機器學習技術檢測惡意代碼。
克隆檢測主要包括源代碼檢測以及二進制代碼檢測,廣泛應用于漏洞發現,代碼克隆檢測,用戶 端崩潰分析等,目前,惡意代碼分析變得比以往任何時候都更加重要。随着科技的日益發展,大量的物聯網設備投入使用,據 Gartner 分析在 2017 年時全球已經有 84 億物聯網設備投入使用,比 2016 年 增長 31%,預測到 2020 年将達到 204 億。而物聯網的快速發展,導緻各種網絡攻擊以及惡意代碼也随之增多,因此,惡意代碼分析變的十分迫切。而人工智能在惡意代碼檢測發揮着越來越多的作用。
CNN 進行特征提取:對構成的文本特征進行建模,CNN 利用卷積濾波器提取句子不同 位置的 n-gram 特征。
SLSTM 模型的輸入由兩部分組成,部分是 CNN 提取的高級窗口表示,另一部分是 系統調用函數的圖形嵌入表示。同一個樣本中的每個自定義函數的 CFG 對應的相同的系統調用函數 圖(AFCG),即每個自定義函數的反彙編代碼文本對應于同樣的系統調用圖結構特征,因爲雖然是 不同自定義函數但都來源于同一個樣本。
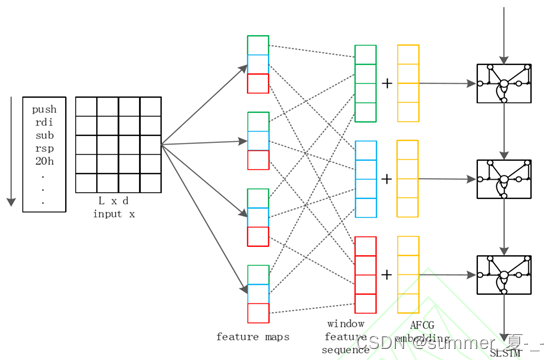
圖.語義模型的 CNN-SLSTM 的體系結構
2.2. 自動釣魚檢測
互聯網釣魚欺詐,簡稱網絡釣魚(**釣魚,是指攻擊者通過發送欺騙性垃圾郵件,即時通你留言等方式,騙取用戶點擊訪問建假仿冒的釣魚網站,意圖引誘用戶洩露其敏感信息如用戶名,口令,影号,ATM PIN碼或信用卡詳細信息)的一種攻擊方式”**被攻擊用戶,輕則丢失個人私密信息,重則遭受嚴重的經濟損失,造成極其惡劣的影響,截至2020年6月31.8%有網絡購物經曆的網民曾依網購過程中直接碰到釣魚網站或詐騙網站,且每年因釣魚網站或詐騙網站給網民造成的損失不低于308個億”,因此,網絡約魚行爲對互聯網的健康發展已經造成了巨大的負面影響。

不法分子模拟可信實體大量的網絡釣魚網站獲取您的數據,如您的信用卡的登錄、密碼、号碼和 CV 等等。機器學習算法對于一次性地銷毀這種方案具有很大的幫助作用。
ML 可以通過類似于電子郵件垃圾郵件過濾器的郵件分類幫助。最初的訓練數據是由用戶手動标記郵件或報告可疑鏈接的人群來源。與以往一樣,通過不斷學習的過程, ML 算法可以提高精度。
2.3.自動數據盜竊檢測
數據洩露是當今組織面臨的最常見的威脅載體之一。爲了緩解這樣的問題,基于機器學習的算法可以被用來通過隐蔽的通道(如深網或暗網)爬行,并識别惡意用戶匿名共享的數據。
互聯網的最後一層是黑暗的網絡。它比表面或深度網絡更難訪問,因爲它隻能通過特殊的浏覽器(如 Tor 浏覽器)訪問。
雖然深度網絡隻能通過匿名加密的對等通信信道訪問,但需要應用某些保護措施,如 CAPTCHA 。反過來, AI 必須欺騙這些系統,使其相信收集數據的代理是人類的,并且可以從解決簡單的 captc 到使用 NLP 來向惡意各方的私人社區發出邀請。利用機器視覺,可以在實時中分析圖像。
爲了使 ML 算法有效,需要:
- 能夠檢測不同類型的數據元素(用戶定義的類型、基元類型、數據轉換的沿襲、硬編碼的文本、注釋的類型、對環境數據的引用标識符等等)
- 能夠基于使用自然語言處理的受監管模型将這些檢測到的類型分類爲敏感的,該模型被訓練成遵從命令的集合。
- 跟蹤此類敏感類型的所有轉換、血統和來源
- 最後,測量這些敏感類型是否違反了當前( SOC-2、 GDPR )或即将到來( CCPA )的法規遵從性約束。
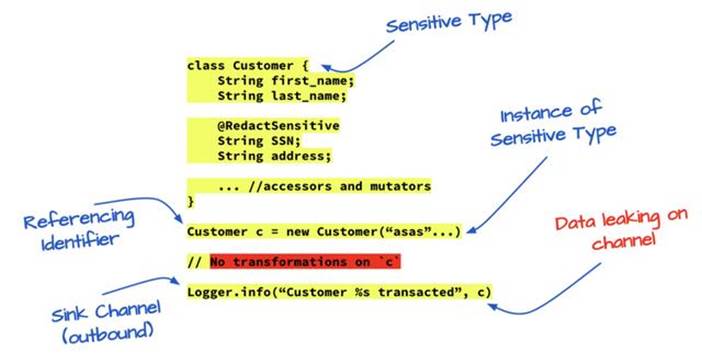
圖.不同類型的數據元素
2.4. 感知上下文的行爲分析
這更像一個概念或模型,情境感知行爲分析建立在異常行爲可能引發攻擊的前提之上。這種類型的評估是通過大數據和機器學習來确定用戶活動的風險在近實時。
這種方法也被稱爲 UBA ,它拼寫來自用戶行爲分析。
所有的安全産品都在二值術語的世界中:流量不好或好,文件感染與否。那麽如何檢測較小的信号呢?詳細闡述正常用戶行爲的标準模式有助于解決這一問題。
圖.上下文分析
由于編纂什麽行爲可以是“正常”的行爲是很複雜的,因此 ML (機器學習)模型通過查看曆史活動和在對等組中進行比較來爲每個用戶構建基線。它是如何工作的?在檢測到任何異常事件的情況下,評分機制聚集它們以爲每個用戶提供組合的風險得分。
具有較高評分的用戶将被篩選出來并呈現給具有上下文信息的分析師以及他們的角色和職責。下面是這個公式:
風險=可能性X影響
通過跟蹤它,使用 UBA 的應用程序能夠提供可操作的風險智能。
2.5. 基于蜜罐的社會工程防禦
什麽是蜜罐?這隻是一個陷阱, IT 專業人員爲惡意黑客設置,希望他們能以提供有用情報的方式與之互動。這是 IT 中最古老的安全措施之一
随着互聯網的飛速發展,網絡安全已經日趨重要,針對不斷出現的網絡 攻擊技術,主動防禦系統的出現是必然的。主動防禦技術中的蜜罐技術将傳統 攻擊手段中的欺騙技術引入了安全防禦領域,從一個新的方向出發來處理網絡安全問題。設計中應用蜜罐技術的基本思想,模拟設計了一個低交互式的小型蜜罐系統。在VMwar上安裝操作系統,應用網站開發搭建了一個虛拟交互網站。通過對模拟網站的日志文件的自動讀取和處理,最終達到了對網站交互平 台上的訪問者進行判斷,設計中用到了僞裝逼真、數據捕獲和數據分析等技 術,可以在虛拟與真實系統間完成對入侵者重定向的目的。
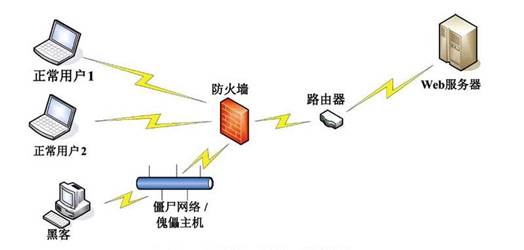
圖.原始網絡拓撲結構
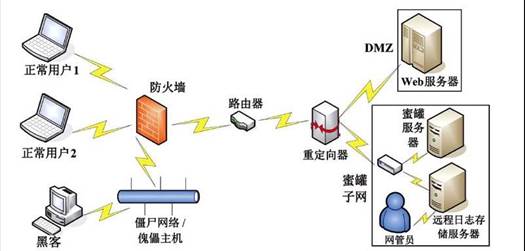
圖.采用蜜罐技術的網絡拓撲結構
另一個不壞的概念,有很大的潛力即将發布。
攻擊者利用人類的心理,能夠獲取個人信息,以危害安全系統,硬件和軟件本身無法阻止這些攻擊。一種可能的對策是利用社交蜜罐、用來誘捕攻擊者的假角色裝飾。
通過充當誘餌用戶,它試圖欺騙攻擊者。由于與蜜罐的所有通信都是未經請求的,所以初始合同很可能是垃圾郵件。ML(機器學習) 用于對發送者是惡意的還是良性的進行分類。這樣的分類然後被自動傳播到所有真實雇員的設備,然後,這些設備将自動阻止來自犯罪一方的進一步通信嘗試。
三、總結
通過對每個惡意軟件樣本進行靜态反彙編分析根據函數的控制流程圖構建其自定義函數的反彙編代碼文本,以及整個樣本的系統函數調用圖爲惡意軟件的特征相結合,然後利用之前的一神經網絡模型(CNN-SLSTM),對惡意代碼組樣本進行分類。該方法能夠很好地提取惡意代碼特征并據此進行分類,提高檢測效率!
總而言之,人工智能将在信息系統安全中發揮着越來越重要的作用,而與此同時,人工智能的發展也将給不法分子帶來可乘之機,對信息系統安全造成威脅。可見,事物都具有兩面性,而我們要取其精華,去其糟粕!
四、參考文獻
[1] https://zhuanlan.zhihu.com/p/105332028
[2] https://blog.csdn.net/linux_hua130/article/details/105509386
[3] https://www.cnblogs.com/linuxprobe/p/12697169.html
[4] Bencs´ath, G. P´ek, L. Butty´an, and M. F´elegyh´azi, “The cousins of stuxnet: Duqu, flame, and gauss. Future Internet 4 (4): 971–1003,” 2012.
[5] N. Kalchbrenner, E. Grefenstette, and P. Blunsom, “A convolutional neural network for modelling sentences,” Eprint Arxiv, vol. 1, 2014.
[6] 諸葛建偉,韓心慧,周勇林等.HoneyBow:一個基于高交互式蜜罐技術的惡意代碼自動捕獲器.
[7] http://www.eepw.com.cn/article/201911/406680.htm
[8]劉巍偉,石勇,郭煜,韓臻等.一種基于深度學習的惡意代碼識别方法.
[9]賈菲,劉威.基于機器學習惡意代碼逆向分析技術的研究.
[10]http://www.gjbmj.gov.cn/n1/2018/0530/c411145-30023895.html
[11]夏天天.基于數據挖掘和機器學習的惡意代碼檢測技術研究
[12]張朝陽.一種基于深度學習的蜜罐防禦方法
[13] S. Deerwester, S. T. Dumais, G. W. Furnas, T. K. Landauer, and R. Harshman, “Indexing by latent semantic analysis,” Journal of the American society for information science, vol. 41, no. 6, pp. 391–407, 1990.
[14]趙澤茂,朱芳.信息安全技術.西安:西安電子科技大學出版社,2009
[15][李鎖](https://xueshu.baidu.com/s?wd=author%3A(李鎖) &tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&sc_f_para=sc_hilight%3Dperson),[吳毅堅](https://xueshu.baidu.com/s?wd=author%3A(吳毅堅) &tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&sc_f_para=sc_hilight%3Dperson),[趙文耘](https://xueshu.baidu.com/s?wd=author%3A(趙文耘) &tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&sc_f_para=sc_hilight%3Dperson).基于代碼克隆檢測的代碼來源分析方法
[16]L. Prechelt, G. Malpohl, and M. Philippsen, “Finding plagiarisms among a set of programs with JPlag,” Journal of Universal Computer Science, vol. 8, no. 11, pp. 1016–1038, 2002.








