

文章目录
- 1. 理解混合专家
- 定义和组成部分
- 稀疏MoE层和专家的作用
- 门网络的功能
- 2. 挑战和解决方案
- 训练和推理的挑战
- 训练挑战
- 推理挑战
- 解决方案和策略
- 3. 历史背景和演变
- 在自然语言处理和其他领域的进展
- 4. 稀疏性原则
- 稀疏性概念
- 门控机制
- 5. Transformers中的MoEs
- 6. 使用Switch Transformers的突破
- 7. MoE的微调
- 8. 实际应用和未来方向
- 9. 开源和可访问性
- 结论
混合专家(MoE)提供了一种独特的方法,可以在保持或甚至改善性能的同时有效地扩展模型。
传统上,模型训练的权衡是在大小和计算资源之间进行的。更大的模型通常承诺更好的性能,但代价是更大的计算需求。MoE通过使模型能够以较少的计算量进行预训练来挑战这种规范。这种方法允许在与传统密集模型相同的计算预算内大幅增加模型或数据集的大小。因此,在预训练阶段,预计MoE模型能够更快地达到与其密集对应物相当的质量。
1. 理解混合专家
定义和组成部分
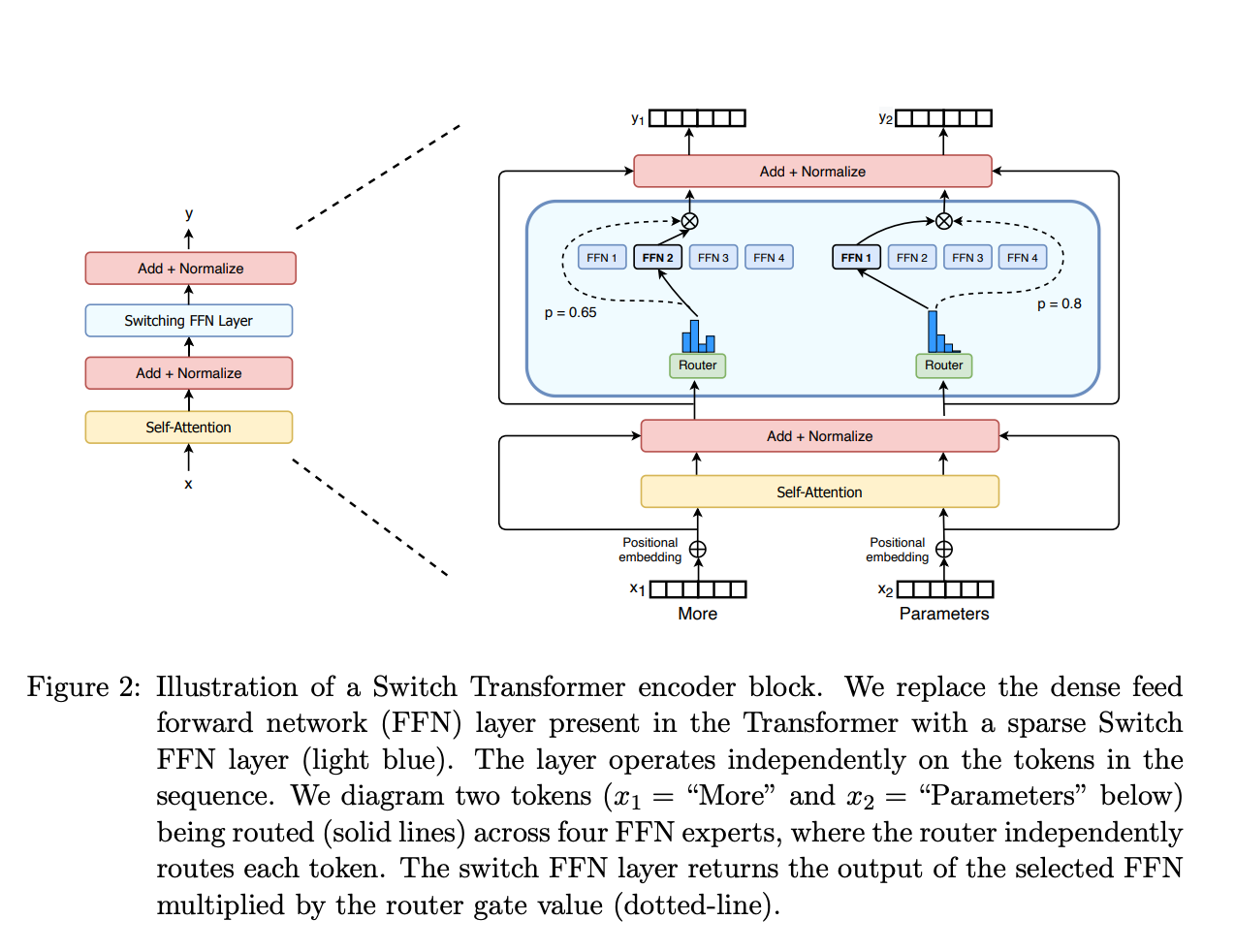
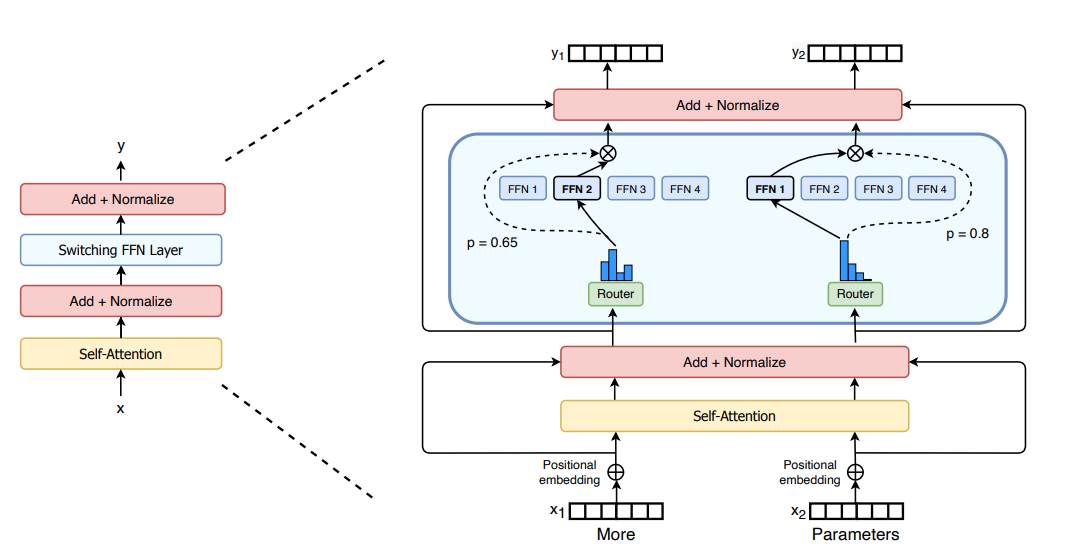
在其核心,MoE,特别是在转换器模型的上下文中,由两个主要元素组成:稀疏的MoE层和一个门网络(或路由器)。
稀疏MoE层和专家的作用
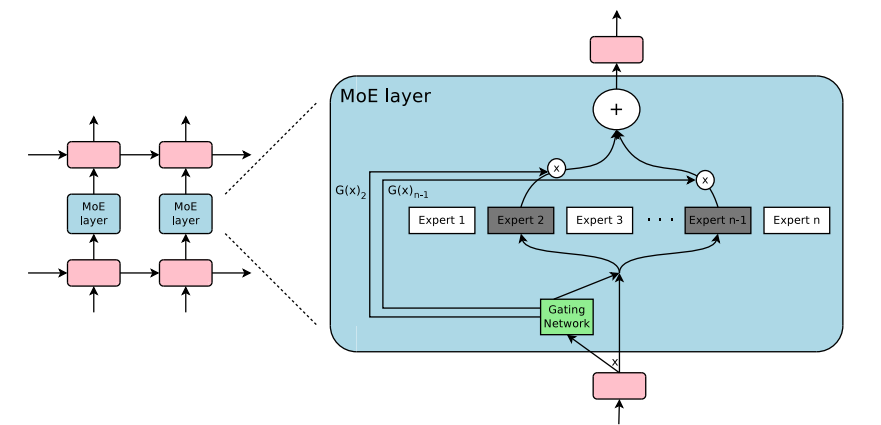
与转换器模型中通常使用的密集前馈网络(FFN)层不同,MoE使用稀疏的MoE层。每个层包含多个“专家”,每个专家都是一个神经网络,通常是FFN的形式。这些专家的复杂性可以不同,并且有趣的是,它们甚至可以包含MoE本身,从而创建出分层的MoE结构。
门网络的功能
门网络在确定将令牌路由到适当的专家方面起着关键作用。例如,在给定的情况下,令牌“More”可能被定向到一个专家,而“Parameters”则被定向到另一个专家。这种路由不仅对MoE的功能至关重要,而且还带来了关于令牌路由的决策复杂性,其中路由器本身是在网络的预训练过程中演变的一个学习实体。
2. 挑战和解决方案
训练和推理的挑战
虽然MoE在预训练和更快的推理方面提供了效率,但它们并不是没有挑战的。
训练挑战
一个重要的障碍在于在微调过程中泛化MoE,它可能倾向于过拟合。
推理挑战
尽管MoE具有大量的参数,但在推理过程中只有其中的一部分参数是活跃的,从而加快了处理速度。然而,这也意味着需要大量的内存,因为所有参数都必须加载到RAM中,而不管它们在推理过程中的活动状态如何。
解决方案和策略
为了解决这些挑战,采用了各种策略。这些策略包括负载平衡,以防止某些专家的过度使用,并引入辅助损失以确保所有专家之间的公平训练。
3. 历史背景和演变
MoE的概念可以追溯到1991年,当时发表了论文“自适应局部专家混合”。这项早期工作通过提出一个系统,在这个系统中,由一个门控网络引导,不同的网络(专家)处理不同的训练样例子集。
在自然语言处理和其他领域的进展
2010年至2015年期间取得了显著的进展,这些进展对MoE的发展做出了贡献。这些包括将MoE作为更深层网络中的组件进行探索,以及由Yoshua Bengio引入的条件计算,根据输入数据动态激活网络组件。
4. 稀疏性原则
稀疏性概念
稀疏性是基于条件计算原则而引入的,正如Shazeer在对MoEs用于翻译的探索中所介绍的那样。这使得模型的规模可以扩展而不会成比例地增加计算量,从而在每个MoE层中使用数千个专家。
门控机制
已经探索了各种门控机制,例如嘈杂的Top-K门控。这种方法在路由过程中添加噪音,然后选择前k个值,在专家利用效率和多样性之间创建平衡。
5. Transformers中的MoEs
GShard在transformers中实现的MoEs是大规模应用的一个显著例子。它引入了随机路由和专家容量等新概念,确保在规模上实现负载均衡和效率。
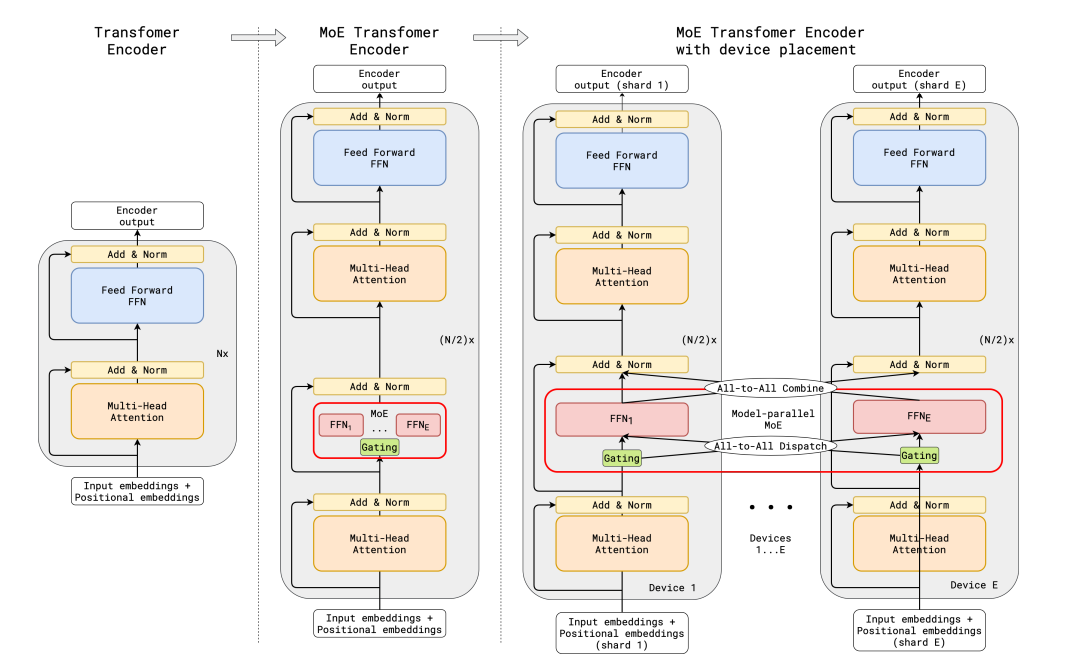
6. 使用Switch Transformers的突破
Switch Transformers在MoE领域中代表了一个重大的进步。它们简化了路由过程并减少了通信成本,同时保持了模型的质量。在这里,对专家容量的概念进行了进一步的改进,以在令牌分布和计算效率之间取得平衡。
7. MoE的微调
MoE的微调面临着独特的挑战,特别是过拟合问题。为了缓解这些问题,采用了诸如在专家中增加正则化和调整辅助损失等策略。此外,在微调过程中选择性冻结MoE层参数已经显示出在保持性能的同时简化流程的潜力。
8. 实际应用和未来方向
MoE在各个领域中都找到了应用,尤其是在语言翻译和大规模模型中。MoE在人工智能领域的潜力是巨大的,目前的研究正在探索新的领域和应用。
进一步的实验是将稀疏的MoE蒸馏回一个参数更少但参数数量相似的稠密模型。
另一个领域将是MoE的量化。QMoE(2023年10月)是朝着这个方向迈出的一大步,它将MoE量化为每个参数不到1比特,从而将使用3.2TB***的1.6T Switch Transformer压缩到只有160GB。
9. 开源和可访问性
几个开源项目增强了MoE的可访问性。这些资源有助于MoE的训练和实施,为协作和进步的人工智能研究社区做出了贡献。
现在有几个开源项目可以用来训练MoE:
-
Megablocks: https://github.com/stanford-futuredata/megablocks
-
Fairseq: https://github.com/facebookresearch/fairseq/tree/main/examples/moe_lm
-
OpenMoE: https://github.com/XueFuzhao/OpenMoE
在已发布的开放获取的MoE领域,您可以查看:
-
Switch Transformers (Google):基于T5的MoE集合,从8个专家到2048个专家。最大的模型有1.6万亿个参数。
-
NLLB MoE (Meta):NLLB翻译模型的MoE变体。
-
OpenMoE:一个社区努力,已发布了基于Llama的MoE。
-
Mixtral 8x7B (Mistral):一种高质量的MoE,优于Llama 2 70B,并且具有更快的推理速度。还发布了一个经过指导调优的模型。在公告博客文章中了解更多信息。
结论
专家混合模型代表了人工智能领域的一次重大飞跃,为构建大型而强大的AI模型提供了一种可扩展且高效的方法。随着这一领域的研究和发展不断演进,MoE在人工智能的各个领域中的潜在应用和进展是无限的。
-
-







