

随着卷積神經網絡的發展和普及,我們了解到增加神經網絡的層數可以提高模型的訓練精度和泛化能力,但簡單地增加網絡的深度,可能會出現“梯度彌散”和“梯度爆炸”等問題。傳統對應的解決方案則是權重的初始化(normalized initializatiton)和批标準化(batch normlization),這樣雖然解決了梯度的問題,但深度加深了,卻帶來了另外的問題,就是網絡性能的退化問題。
一、什麽是網絡的退化問題?

由上圖可以看出,56-layer(層)的網絡比20-layer的網絡在訓練集和測試集上的表現都要差【注意:這裏不是過拟合(過拟合是在訓練集上表現得好,而在測試集中表現得很差)】,說明如果隻是簡單的增加網絡深度,可能會使神經網絡模型退化,進而丢失網絡前面獲取的特征。
網絡退化:在增加網絡層數的過程中,training accuracy (精度)逐漸趨于飽和,繼續增加層數,training accuracy 就會出現下降的現象,而這種下降不是由過拟合造成的。實際上較深模型後面添加的不是恒等映射,而是一些非線性層。
退化問題的實質:通過多個非線性層來近似恒等映射可能是困難的(恒等映射亦稱恒等函數:是一種重要的映射,對任何元素,象與原象相同的映射)。神經網絡在反向傳播過程中要不斷傳播梯度,而當層數加深,梯度在傳播過程中逐漸消失【而梯度消失則是導緻網絡退化的一個重要因素】,導緻無法對前面網絡的權重進行有效調整(這裏大家可以想一下一條很長的繩子從頭抖一下,有時候是不能影響末端的。
二、殘差網絡解決的問題
神經網絡越來越深的時候,反傳回來的梯度之間的相關性會越來越差,最後接近白噪聲。因爲我們知道圖像是具備局部相關性的,那其實可以認爲梯度也應該具備類似的相關性,這樣更新的梯度才有意義,如果梯度接近白噪聲,那梯度更新可能根本就是在做随機擾動。
何凱明提出殘差網絡概念的論文地址:https://arxiv.org/abs/1512.03385
基于網絡退化問題,論文(https://arxiv.org/pdf/1702.08591.pdf)的作者通過淺層網絡等同映射構造深層模型,結果深層模型并沒有比淺層網絡有等同或更低的錯誤率,推斷退化問題可能是因爲深層的網絡并不是那麽好訓練,也就是求解器很難去利用多層網絡拟合同等函數。
如果深層網絡的後面那些層是恒等映射,那麽模型就退化爲一個淺層網絡。那當前要解決的就是學習恒等映射函數了。 但是直接讓一些層去拟合一個潛在的恒等映射函數:,比較困難,這可能就是深層網絡難以訓練的原因。但是,如果把網絡設計爲:
1.殘差塊原理:
一個殘差塊的數學模型如下圖示。殘差網絡和之前的網絡最大的不,同就是多了一條identity的捷徑分支。而因爲這一條分支的存在,使得網絡在反向傳播時,損失可以通過這條捷徑将梯度直接傳向更前的網絡,從而減緩了網絡退化的問題。在第二節分析網絡退化的原因時,我們了解到梯度之間是有相關性的。我們在有了梯度相關性這個指标之後,作者分析了一系列的結構和激活函數,發現resnet在保持梯度相關性方面很優秀,從梯度流來看,有一路梯度是保持原樣不動地往回傳,這部分的相關性是非常強的。除此之外,殘差網絡并沒有增加新的參數,隻是多了一步加法。而在GPU的加速下,這一點額外的計算量幾乎可以忽略不計。
不過我們可以看到,因爲殘差塊最後是 F ( x ) + x F(x) + x F(x)+x的操作,那麽意味着 F ( x ) F(x) F(x) 與 x x x的shape必須一緻。但在實際的網絡搭建中,還可以利用1x1的卷積改變通道數目。
如圖1。
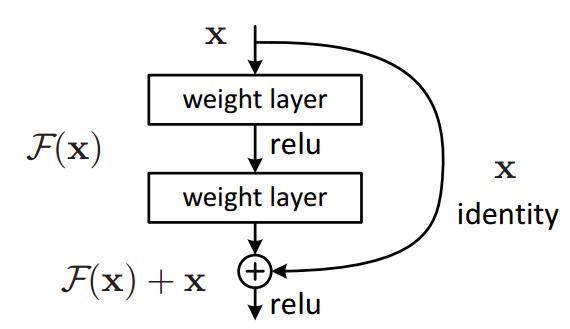
我們可以轉換爲學習一個殘差函數:,隻要:
就構成了一個恒等映射:
而且,拟合殘差肯定更加容易。
F是求和前網絡映射,H是從輸入到求和後的網絡映射。比如把5映射到5.1,那麽引入殘差前是:
,
引入殘差後是:,
,
這裏的和
都表示網絡參數映射,引入殘差後的映射對輸出的變化更敏感。比如S輸出從5.1變到5.2,映射的輸出
增加了2%,而對于殘差結構輸出從5.1到5.2,映射F是從0.1到0.2,增加了100%。明顯後者輸出變化對權重的調整作用更大,所以效果更好。殘差的思想都是去掉相同的主體部分,從而突出微小的變化。
2、殘差塊代碼示例:
import torch
import torch.nn as nn
#殘差塊
class Res_Block(nn.Module):
def __init__(self,c):
super(Res_Block, self).__init__()
#殘差網絡要求整個模型輸入和輸出的通道一樣
self.layer=nn.Sequential(
#增加Padding是爲了保持通道一樣
nn.Conv2d(in_channels=c, out_channels=c, kernel_size=3, stride=1,padding=1,bias=False),
nn.BatchNorm2d(c),#批标準化
nn.ReLU(),
nn.Conv2d(c, c, 3, 1,1),
nn.BatchNorm2d(c),
nn.ReLU(),
)
def forward(self,x):
#殘差網絡的應用+x
return self.layer(x)+x
if __name__ == '__main__':
net=Res_Block(3)
x=torch.randn(1,3,28,28)
y=net.forward(x)
print(y.shape)三、殘差網絡讨論
至于爲何shortcut(捷徑)的輸入是X,而不是X/2或是其他形式。作者的另一篇文章中探讨了這個問題,對以下6種結構(圖2)的殘差結構進行實驗比較,shortcut是X/2的就是第二種,結果發現還是第一種效果好。
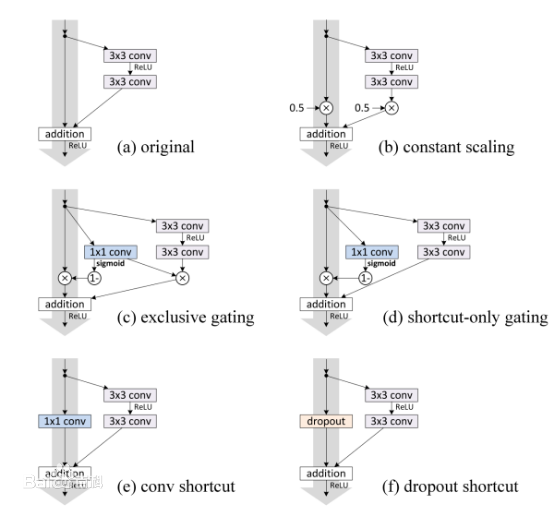
這種殘差學習結構可以通過前向神經網絡+shortcut連接實現,如結構圖1所示。而且shortcut連接相當于簡單執行了同等映射,不會産生額外的參數,也不會增加計算複雜度。 而且,整個網絡可以依舊通過端到端的反向傳播訓練。
根據多層的神經網絡理論上可以拟合任意函數,那麽可以利用一些層來拟合函數。問題是直接拟合 還是殘差函數
,拟合殘差函數更簡單。雖然理論上兩者都能得到近似拟合,但是後者學習起來顯然更容易。作者說,這種殘差形式是由退化問題激發的。根據前文,如果增加的層被構建爲同等函數,那麽理論上,更深的模型的訓練誤差不應當大于淺層模型,但是出現的退化問題表明,求解器很難去利用多層網絡拟合同等函數。但是,殘差的表示形式使得多層網絡近似起來要容易的多,如果`同等函數可被優化近似,那麽多層網絡的權重就會簡單地逼近0來實現同等映射,即
。
實際情況中,同等映射函數可能不會那麽好優化,但是對于殘差學習,求解器根據輸入的同等映射,也會更容易發現擾動,總之比直接學習一個同等映射函數要容易的多。根據實驗,可以發現學習到的殘差函數通常響應值比較小,同等映射(shortcut)提供了合理的前提條件。
通過shortcut同等映射
F(x)與x相加就是就是逐元素相加,但是如果兩者維度不同,需要給x執行一個線性映射來匹配維度:
用來學習殘差的網絡層數應當大于1,否則退化爲線性。文章實驗了layers = 2或3,更多的層也是可行的。
用卷積層進行殘差學習:以上的公式表示爲了簡化,都是基于全連接層的,實際上當然可以用于卷積層。加法随之變爲對應channel間的兩個feature map逐元素相加。
1.網絡結構
作者由VGG19設計出了plain 網絡和殘差網絡,如圖3中部和右側網絡。然後利用這兩種網絡進行實驗對比。
設計網絡的規則:
1.對于輸出feature map大小相同的層,有相同數量的filters,即channel數相同;
2. 當feature map大小減半時(池化),filters數量翻倍。
對于殘差網絡,維度匹配的shortcut連接爲實線,反之爲虛線。維度不匹配時,同等映射有兩種可選方案:直接通過zero padding 來增加維度(channel)、乘以W矩陣投影到新的空間。實現是用1x1卷積實現的,直接改變1x1卷積的filters數目。這種會增加參數。
圖3:

ResNet推薦參數如上圖所示,作者還用全局平均池化替代了全連接層,一方面減少了參數量,另一方面全連接層易于過拟合并且嚴重依賴于 dropout 正則化,而全局平均池化本身就是起到了正則化作用,其本身防止整體結構的過拟合。此外,全局平均池彙總了空間信息,因此對輸入的空間轉換更加健壯。
2.殘差網絡代碼實現:
import torch
import torch.nn as nn
DEVICE=torch.device( "cuda"if torch.cuda.is_available()else"cpu")
#殘差塊
class Res_Block(nn.Module):
def __init__(self,c):
super(Res_Block, self).__init__()
#殘差網絡要求整個模型輸入和輸出的通道一樣
self.layer=nn.Sequential(
nn.Conv2d(c, c, 3, 1,padding=1),#增加Padding是爲了保持通道一樣
nn.ReLU(),
nn.Conv2d(c, c, 3, 1, padding=1),
nn.ReLU(),
)
def forward(self,x):
#殘差網絡的應用+x
return self.layer(x)+x
#封裝Net類
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.layer=nn.Sequential(
nn.Conv2d(1,64,3,1,padding=1),
nn.ReLU(),
Res_Block(64),#實例化對象
Res_Block(64),
Res_Block(64),
Pool(64,128),
Res_Block(128),
Res_Block(128),
Res_Block(128),
Res_Block(128),
Pool(128, 256),
Res_Block(256),
Res_Block(256),
Res_Block(256),
Res_Block(256),
Res_Block(256),
Pool(256,512),
Res_Block(512),
Res_Block(512),
# nn.Linear(512*32*32,10)
)
self.layer2=nn.Sequential(
nn.Linear(512*32*32,10)
)
def forward(self, x):
OUT=self.layer(x)
OUT=OUT.reshape(-1,512*32*32)
return self.layer2(OUT)
#實現下采樣
class Pool(nn.Module):
def __init__(self,c_in,c_out):
super(Pool, self).__init__()
self.layer=nn.Sequential(
nn.Conv2d(c_in,c_out,3,1,padding=1),
nn.ReLU(),
nn.Conv2d(c_out,c_out,3,1,padding=1),
nn.ReLU()
)
def forward(self,x):
return self.layer(x)
if __name__ == '__main__':
res=Net()
x=torch.randn(32,1,32,32)
y=res.forward(x)
print(y.shape)
# print(res)作者探索的更深的網絡。 考慮到時間花費,将原來的building block(殘差學習結構)改爲瓶頸結構,如圖4。首端和末端的1x1卷積用來削減和恢複維度,相比于原本結構,隻有中間3x3成爲瓶頸部分。這兩種結構的時間複雜度相似。此時投影法映射帶來的參數成爲不可忽略的部分(以爲輸入維度的增大),所以要使用zero padding的同等映射。替換原本ResNet的殘差學習結構,同時也可以增加結構的數量,網絡深度得以增加。生成了ResNet-50,ResNet-101,ResNet-152. 随着深度增加,因爲解決了退化問題,性能不斷提升。
總結:
關于殘差網絡的我還在不斷學習中,以上内容大多數來自網絡,我隻是把他們整理了一下,并用代碼實現了,後面可能會對殘差網絡再進行一次深入學習,拜拜。








