

目錄
1.VGG網絡簡介
一.VGG概述
二.VGG結構簡介
2.VGG的優點
3.VGG亮點所在
計算量
感受野
1.VGG網絡簡介
一.VGG概述
VGGNet是牛津大學視覺幾何組(Visual Geometry Group)提出的模型,該模型在2014ImageNet圖像分類與定位挑戰賽 ILSVRC-2014中取得在分類任務第二,定位任務第一的優異成績。VGGNet突出的貢獻是證明了很小的卷積,通過增加網絡深度可以有效提高性能。VGG很好的繼承了Alexnet的衣缽同時擁有着鮮明的特點。相比Alexnet ,VGG使用了更深的網絡結構,證明了增加網絡深度能夠在一定程度上影響網絡性能。
說得簡單點,VGG就是五次卷積的卷積神經網絡。
二.VGG結構簡介
我們上文已經說了,VGG其實就是五層卷積。我們來看這個圖:

這個圖是作者當時六次實驗的結果圖。在介紹這個圖前,我先進行幾個概念說明:卷積層全部爲3*3的卷積核,用conv3-xxx來表示,xxx表示通道數。
在這個表格中,我們可以看到,
第一組(A)就是個簡單的卷積神經網絡,沒有啥花裏胡哨的地方。
第二組(A-LRN)在第一組的卷積神經網絡的基礎上加了LRN(小白們不用太過了解這個,現在已經不是主流了,LRN是Alexnet中提出的方法,在Alexnet中有不錯的表現 )
第三組(B)在A的基礎上加了兩個conv3,即多加了兩個3*3卷積核
第四組(C)在B的基礎上加了三個conv1,即多加了三個1*1卷積核
第五組(D)在C的基礎上把三個conv1換成了三個3*3卷積核
第六組(E)在D的基礎上又加了三個conv3,即多加了三個3*3卷積核
初高中就告訴我們,實驗要控制變量(單一變量),你看,用到了吧
那麽,我們從這一組實驗中能得到什麽結果呢?
1.第一組和第二組進行對比,LRN在這裏并沒有很好的表現,所以LRN就讓他一邊去吧
2.第四組和第五組進行對比,cov3比conv1好使
3.統籌看這六組實驗,會發現随着網絡層數的加深,模型的表現會越來越好
據此,咱們可以簡單總結一下:論文作者一共實驗了6種網絡結構,其中VGG16和VGG19分類效果最好(16、19層隐藏層),證明了增加網絡深度能在一定程度上影響最終的性能。 兩者沒有本質的區别,隻是網絡的深度不一樣。
接下來,以VGG16爲例作具體講解:

相信有小白會疑惑:組号下面那個weight layers 是啥意思?别急,看下面:
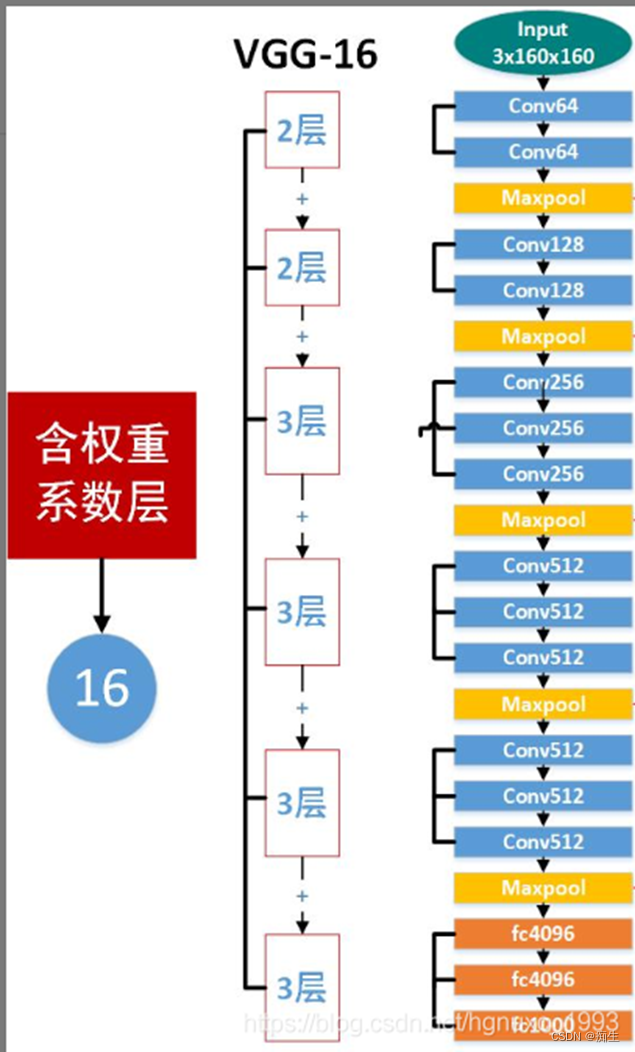
看這幾個數字加起來,是不是就是16?
就像上圖展示的,除了黃色的maxpool(池化層),其他所有層數的總和,就是16,同理,VGG19也一樣。
那麽,爲什麽不算池化層呢?
這是因爲,池化層沒有權重系數,而其他層都有,所以.....
那麽,我們接下來去看VGG是如何工作的:
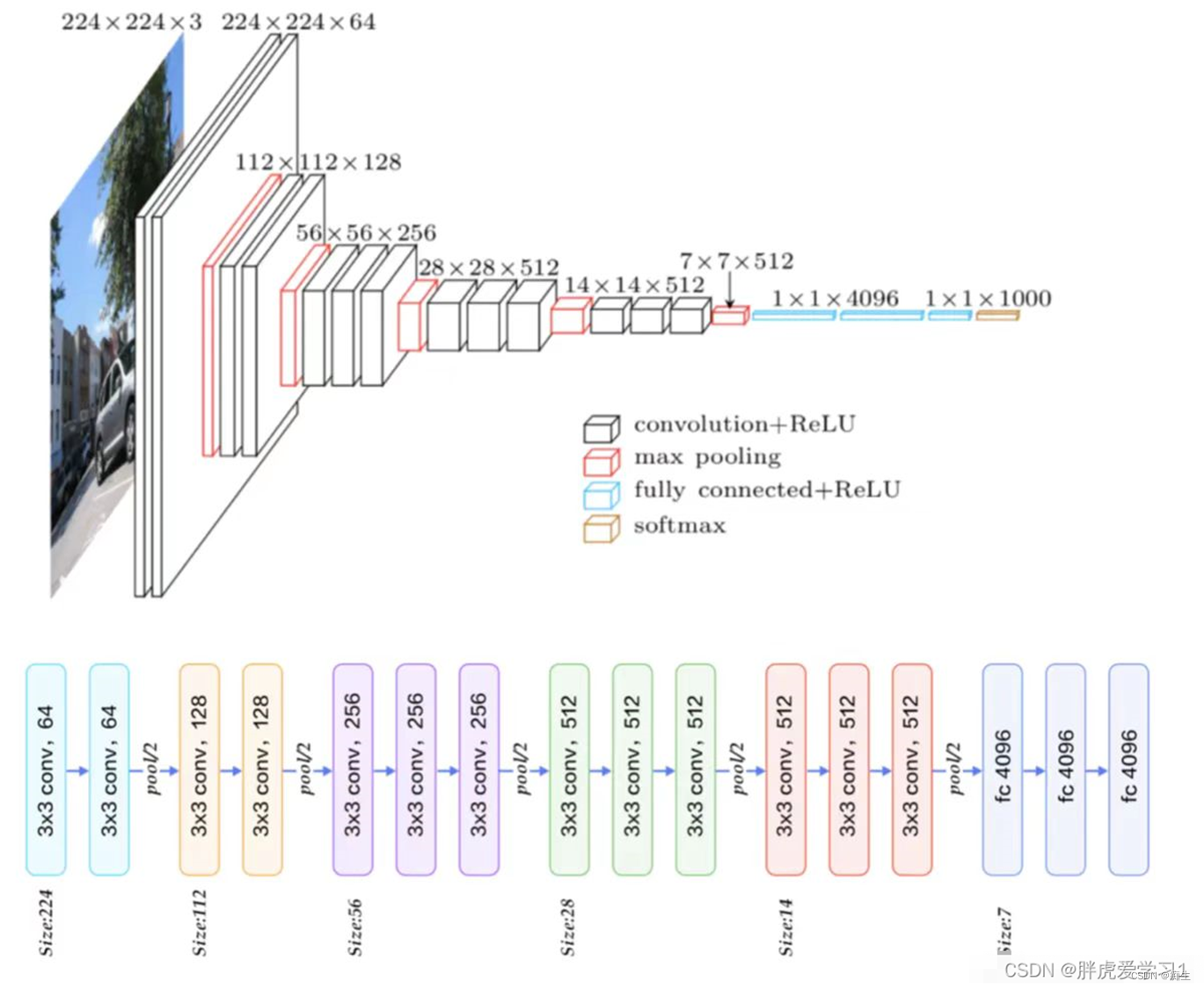
看,一個長224,寬224,通道數3的圖,經過第一個模塊,通道數增加到64,随後經過池化層長寬減半。然後到第二個模塊,通道數增加到128,到池化層長寬再減半......
一直到最後一次池化,得到7×7×512的結果,然後通過三個全連接層,變成最後的1×1×1000的分類結果(也不一定是一千,這裏的1000是當時的比賽結果)
2.VGG的優點
1.小卷積核組:作者通過堆疊多個3*3的卷積核(少數使用1*1)來替代大的卷積核,以減少所需參數;
2.小池化核:相比較于AlexNet使用的3*3的池化核,VGG全部爲2*2的池化核;
3.網絡更深特征圖更寬:卷積核專注于擴大通道數,池化專注于縮小高和寬,使得模型更深更寬的同時,計算量的增加不斷放緩;
4.将卷積核替代全連接:作者在測試階段将三個全連接層替換爲三個卷積,使得測試得到的模型結構可以接收任意高度或寬度的輸入。
5.多尺度:作者從多尺度訓練可以提升性能受到啓發,訓練和測試時使用整張圖片的不同尺度的圖像,以提高模型的性能。
6.去掉了LRN層:作者發現深度網絡中LRN(Local Response Normalization,局部響應歸一化)層作用不明顯。
3.VGG亮點所在
在AlexNet中,作者使用了11x11和5x5的大卷積,但大多數還是3x3卷積,對于stride=4的11x11的大卷積核,理由在于一開始原圖的尺寸很大因而冗餘,最爲原始的紋理細節的特征變化可以用大卷積核盡早捕捉到,後面更深的層數害怕會丢失掉較大局部範圍内的特征相關性,後面轉而使用更多3x3的小卷積核和一個5x5卷積去捕捉細節變化。
而VGGNet則全部使用3x3卷積。因爲卷積不僅涉及到計算量,還影響到感受野。前者關系到是否方便部署到移動端、是否能滿足實時處理、是否易于訓練等,後者關系到參數更新、特征圖的大小、特征是否提取的足夠多、模型的複雜度和參數量等。
計算量
VGG16相比AlexNet的一個改進是采用連續的幾個3x3的卷積核代替AlexNet中的較大卷積核(11x11,7x7,5x5)。對于給定的感受野(與輸出有關的輸入圖片的局部大小),采用堆積的小卷積核是優于采用大的卷積核,因爲多層的非線性層可以增加網絡深度來保證學習更複雜的模式,而且代價還比較小(參數更少)。
在VGG中,使用了3個3x3卷積核來代替7x7卷積核,使用了2個3x3卷積核來代替5*5卷積核,這樣做的主要目的是在保證具有相同感知野的條件下,提升網絡的深度,在一定程度上提升神經網絡的效果。
比如,3個3x3連續卷積相當于1個7x7卷積:3個3*3卷積的參數總量爲 3x(3×3×C2) =27C2,1個7x7卷積核參數總量爲1×7×7×C2 ,這裏 C 指的是輸入和輸出的通道數。很明顯,27








