

github仓库
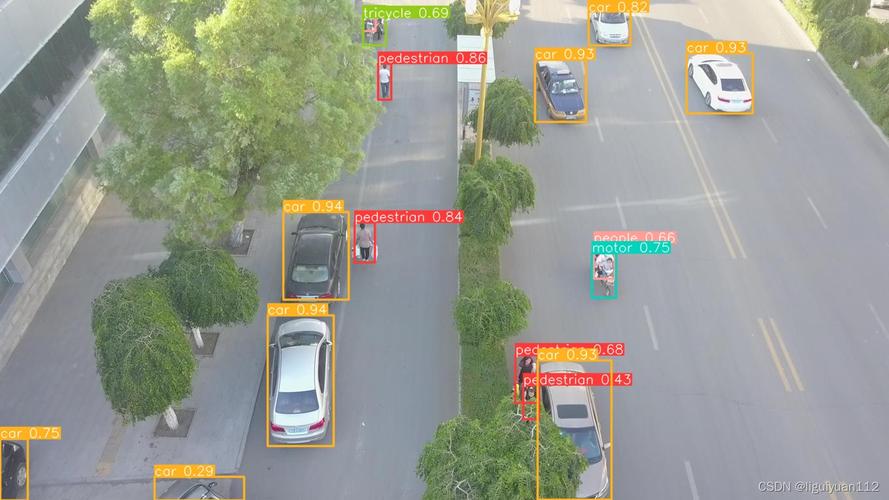
(图片来源网络,侵删)
- 所需:
- 安装了Ubuntu20系统的RK3588
- 安装了Ubuntu18的电脑或者虚拟机一、yolov5 PT模型获取
anaconda教程
YOLOv5教程
 (图片来源网络,侵删)
(图片来源网络,侵删)经过上面两个教程之后,你应该获取了自己的best.pt文件
二、PT模型转onnx模型- 将models/yolo.py文件中的class类下的forward函数由:
def forward(self, x): z = [] # inference output for i in range(self.nl): x[i] = self.m[i](x[i]) # conv bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85) x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous() if not self.training: # inference if self.dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]: self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i) if isinstance(self, Segment): # (boxes + masks) xy, wh, conf, mask = x[i].split((2, 2, self.nc + 1, self.no - self.nc - 5), 4) xy = (xy.sigmoid() * 2 + self.grid[i]) * self.stride[i] # xy wh = (wh.sigmoid() * 2) ** 2 * self.anchor_grid[i] # wh y = torch.cat((xy, wh, conf.sigmoid(), mask), 4) else: # Detect (boxes only) xy, wh, conf = x[i].sigmoid().split((2, 2, self.nc + 1), 4) xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy wh = (wh * 2) ** 2 * self.anchor_grid[i] # wh y = torch.cat((xy, wh, conf), 4) z.append(y.view(bs, self.na * nx * ny, self.no)) return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)改为:
def forward(self, x): z = [] # inference output for i in range(self.nl): x[i] = self.m[i](x[i]) # conv return x- 将export.py文件中的run函数下的语句:
shape = tuple((y[0] if isinstance(y, tuple) else y).shape) # model output shape
改为:
shape = tuple((y[0] if isinstance(y, tuple) else y)) # model output shape
- 将你训练模型对应的run/train/目录下的exp/weighst/best.pt文件移动至与export.py同目录下
- 保证工作目录位于yolov5主文件夹,在控制台执行语句:
cd yolov5 python export.py --weights best.pt --img 640 --batch 1 --include onnx --opset 12
- 然后在主文件夹下出现了一个best.onnx文件,在Netron中查看模型是否正确
- 点击左上角菜单->Properties…
- 查看右侧OUTPUTS是否出现三个输出节点,是则ONNX模型转换成功。
- 如果转换好的best.onnx模型不是三个输出节点,则不用尝试下一步,会各种报错。三、onnx模型转rknn模型
-
我使用的是VMWare虚拟机安装的Ubuntu18.04系统,注意,不是在RK3588上,是在你的电脑或者虚拟机上操作这一步骤。
-
rknn-toolkit2-1.4.0所需python版本为3.6所以需要安装Miniconda来帮助管理。
-
安装Miniconda for Linux
- 进入到下载得到的Miniconda3-latest-Linux-x86_64.sh所在目录
chmod +x Miniconda3-latest-Linux-x86_64.sh ./Miniconda3-latest-Linux-x86_64.sh
- 提示什么都一直同意,直到安装完毕。
- 安装成功后,重新打开终端。
- 如果安装成功,终端最前面应该会有一个(base)
- 安装失败的去参考别的Miniconda3安装教程。
- 创建虚拟环境:
conda create -n rknn3.6 python=3.6
- 激活虚拟环境:
conda activate rknn3.6
- 激活成功时,终端最前面应该会有一个(rknn3.6)
-
下载rknn-toolkit2-1.4.0
- 到Ubuntu,下载源代码下的RK356X/RK3588 RKNN SDK
- 进入百度网盘:RKNN_SDK-> RK_NPU_SDK_1.4.0 下载 rknn-toolkit2-1.4.0
- 下载到Ubuntu后,进入rknn-toolkit2-1.4.0目录
pip install packages/rknn_toolkit2-1.4.0_22dcfef4-cp36-cp36m-linux_x86_64.whl
- 等待安装完毕检查是否安装成功:
python from rknn.api import RKNN
- 如果没有报错则成功。
- 如果报错:
- 1.是否处于rknn3.6虚拟环境下;
- 2.pip install packages/rknn_toolkit2-1.4.0_22dcfef4-cp36-cp36m-linux_x86_64.whl是否报错;
- 3.pip install报错的时候,提示缺什么就用pip install或者sudo apt-get install安装什么;
-
上述所需都安装并且验证成功,则开始下一步。
-
将best.onnx模型转换为best.rknn模型
- 进入转换目录:
cd examples/onnx/yolov5
- 最好是复制一份test.py出来进行修改:
cp test.py ./mytest.py
- 将一开始定义的文件进行修改,这是我修改之后的:
ONNX_MODEL = 'best.onnx' #待转换的onnx模型 RKNN_MODEL = 'best.rknn' #转换后的rknn模型 IMG_PATH = './1.jpg' #用于测试图片 DATASET = './dataset.txt' #用于测试的数据集,内容为多个测试图片的名字 QUANTIZE_ON = True #不修改 OBJ_THRESH = 0.25 #不修改 NMS_THRESH = 0.45 #不修改 IMG_SIZE = 640 #不修改 CLASSES = ("person") #修改为你所训练的模型所含的标签 - 将if __name__ == '__main__':中的语句:
rknn.config(mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]])
- 修改为
rknn.config(mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]], target_platform='rk3588')
- 想要程序执行完,展示推理效果,将以下语句:
# cv2.imshow("post process result", img_1) # cv2.waitKey(0) # cv2.destroyAllWindows() - 注释打开:
cv2.imshow("post process result", img_1) cv2.waitKey(0) cv2.destroyAllWindows() - 终端执行:
python mytest.py
- 运行完展示效果,以及文件夹中出现best.rknn则该步骤成功。四、在RKNN3588上部署rknn模型并实时摄像头推理检测
- 在RKNN3588的Ubuntu20系统上安装Miniconda,需要注意的是,RKNN3588的Ubuntu20系统为aarch架构因此下载的Miniconda版本和之前有所不同,需要选择对应的aarch版本。
- aarchMiniconda下载
- 安装不再赘述。
- 创建虚拟环境,因为在RK3588上要用到rknn-toolkit-lite2所以需要安装python3.7:
- conda create -n rknnlite3.7 python=3.7
- conda activate rknnlite3.7
- 下载rknn-toolkit-lite2到RK3588,也就是下载rknn-toolkit2-1.4.0,不再赘述。
- 安装rknn-toolkit-lite2
- 进入rknn-toolkit2-1.4.0/rknn-toolkit-lite2目录
pip install packages/rknn_toolkit_lite2-1.4.0-cp37-cp37m-linux_aarch64.whl
- 等待安装完毕
- 测试是否安装成功:
python from rknnlite.api import RKNNLite
- 不报错则成功
- 在example文件夹下新建一个test文件夹
- 在其中放入你转换成功的best.rknn模型以及文章开头github仓库下的detect.py文件
- detect.py文件中需要修改的地方:
- 定义
RKNN_MODEL = 'best.rknn' #你的模型名称 IMG_PATH = './1.jpg' #测试图片名 CLASSES = ("cap") #标签名 - if __name__ == '__main__'::
capture = cv2.VideoCapture(11) #其中的数字为你Webcam的设备编号
- 关于设备编号,在终端中运行:
v4l2-ctl --list-devices
- 打印出的Cam之类的字眼对应的/dev/video11中的11就是你的设备编号。
- 运行脚本:
python detect.py
- 部署完成。
- 关于设备编号,在终端中运行:
- 定义
- 进入rknn-toolkit2-1.4.0/rknn-toolkit-lite2目录
- 进入转换目录:
- 进入到下载得到的Miniconda3-latest-Linux-x86_64.sh所在目录
-
- 将export.py文件中的run函数下的语句:
- 将models/yolo.py文件中的class类下的forward函数由:







