

大模型训练——PEFT与LORA介绍
- 0. 简介
- 1. LORA原理介绍
- 2. 补充资料:低显存学习方法
- 3. PEFT对LORA的实现
0. 简介
朋友们好,我是练习NLP两年半的算法工程师常鸿宇,今天介绍一下大规模模型的轻量级训练技术LORA,以及相关模块PEFT。Parameter-Efficient Fine-Tuning (PEFT),是huggingface开发的一个python工具,项目地址:
https://Github.com/huggingface/peft
其可以很方便地实现将普通的HF模型变成用于支持轻量级fine-tune的模型,使用非常便捷,目前支持4种策略,分别是:
- LoRA: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
- Prefix Tuning: Prefix-Tuning: Optimizing Continuous Prompts for Generation, P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
- P-Tuning: GPT Understands, Too
- Prompt Tuning: The Power of Scale for Parameter-Efficient Prompt Tuning
今天要介绍的,是其中之一,也是最近比较热门的LORA (LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS)。
1. LORA原理介绍
LORA的论文写的比较难读懂,但是其原理其实并不复杂。简单理解一下,就是在模型的Linear层,的旁边,增加一个“旁支”,这个“旁支”的作用,就是代替原有的参数矩阵W进行训练。
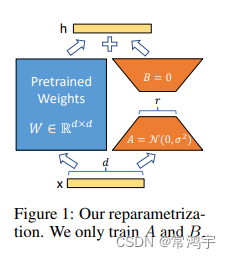
结合上图,我们来直观地理解一下这个过程,输入 x x x,具有维度 d d d,举个例子,在普通的transformer模型中,这个 x x x可能是embedding的输出,也有可能是上一层transformer layer的输出,而 d d d一般就是768或者1024。按照原本的路线,它应该只走左边的部分,也就是原有的模型部分。
而在LORA的策略下,增加了右侧的“旁支”,也就是先用一个Linear层A,将数据从 d d d维降到 r r r,这个 r r r也就是LORA的秩,是LORA中最重要的一个超参数。一般会远远小于 d d d,尤其是对于现在的大模型, d d d已经不止是768或者1024,例如LLaMA-7B,每一层transformer有32个head,这样一来 d d d就达到了4096.
接着再用第二个Linear层B,将数据从 r r r变回 d d d维。最后再将左右两部分的结果相加融合,就得到了输出的hidden_state。
对于左右两个部分,右侧看起来像是左侧原有矩阵 W W W的分解,将参数量从 d ∗ d d*d d∗d变成了 d ∗ r + d ∗ r d*r+d*r d∗r+d∗r,在 r







