

PaddleSpeech 介绍
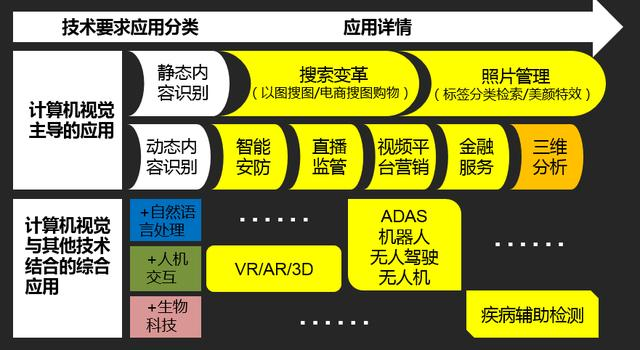
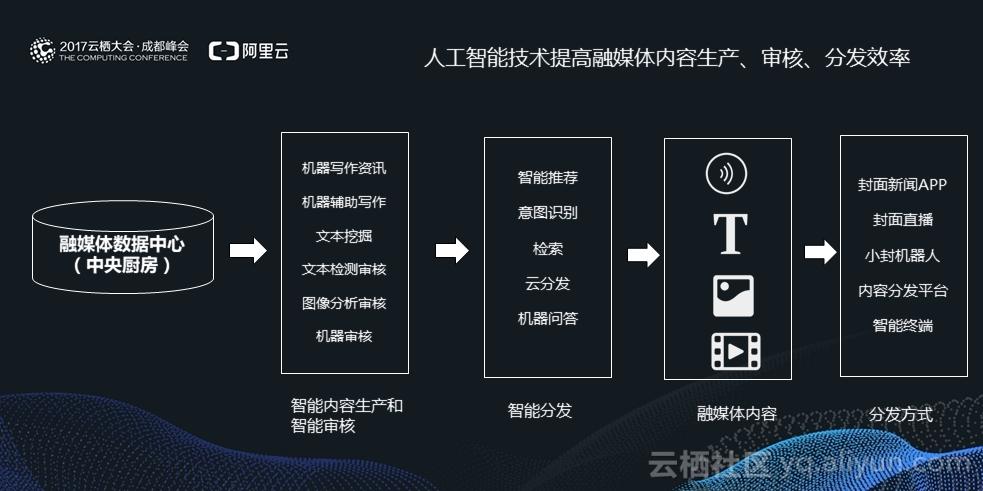
PaddleSpeech是百度飞桨(PaddlePaddle)开源深度学习平台的其中一个项目,它基于飞桨的语音方向模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型。PaddleSpeech支持语音识别、语音翻译(英译中)、语音合成、标点恢复等应用示例。
(图片来源网络,侵删)
安装paddlespeech
PaddleSpeech 快速安装方式有两种,一种是 pip 安装,一种是源码编译(官方推荐)。
使用pip安装paddlespeech
$ pip install pytest-runner $ pip3 install paddleaudio==1.0.1 $ pip3 install paddlespeech==1.0.1
使用源码编译安装
$ git clone https://Github.com/PaddlePaddle/PaddleSpeech.git $ cd PaddleSpeech $ pip install pytest-runner $ pip install .
提示:安装过程可能因为缺少各种的库报错,如:librosa 依赖的系统库,gcc 环境问题,kaldi 安装等可以在网上查找。
(图片来源网络,侵删)
音频示例下载
$ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav $ wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/en.wav
基本使用
语音合成
$ paddlespeech tts --input "你好,欢迎使用百度飞桨深度学习框架!" --output output.wav $ paddlespeech tts --input "你好税软" --output sr.wav
如果报错
$ pip install numpy==1.23.0 $ sudo apt-get install libsndfile1
执行过程
$ ts-paddle /paddle/PaddleSpeech paddlespeech tts --input "你好,欢迎使用百度飞桨深度学习框架!" --output output.wav grep: warning: GREP_OPTIONS is deprecated; please use an alias or script /usr/local/lib/python3.7/dist-packages/librosa/core/constantq.py:1059: DeprecationWarning: `np.complex` is a deprecated alias for the builtin `complex`. To silence this warning, use `complex` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.complex128` here. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations dtype=np.complex, 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 489M/489M [01:01







