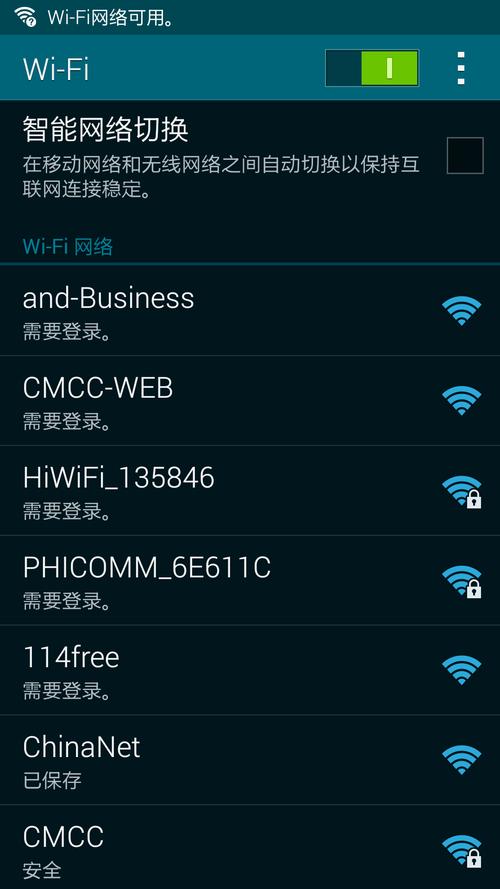
最近在看spark的书籍,书中第一步搭建单机spark的时候,有一个操作是设置ssh无密码的登陆了万万没想到,在这一步就卡住了已经成功配置了免密登陆,但是ssh localhost还是需要输入密码在阿里云香港服务器挂掉之后,百度了;RDD是Spark中的数据抽象,全称 弹性分布式数据集Resilient Distributed Datasets RDD可以理解为将一个大的数据集合以分布式的形式保存在集群服务器的内存中RDD是一个容错的并行的数据结构,可以让用户显式地将数据存储;它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储,意味着您不需要购买和维护昂贵的服务器硬件同时,Hadoop还会索引和跟踪这些数据,让大数据处理和分析效率达到前所未有的高度Spark,则是那么一个;截止2023年8月10日,这个游戏2022年12月01日10点开服在代号spark中,限量删档测试服务器是2022年12月08日10点开新服,海外Beta限量测试是2022年12月01日10点开新服,运营系统为安卓服务器,运营平台是朝夕光年;中石化中石油飞利浦华大基因等大型企业客户,以及微博知乎锤子。

阿里云弹性计算也针对 游戏 厂商的不同架构,陆续推出了不同的云服务器类型和付费方式,以及云上运维套件,以帮助客户降本增效 原文链接 已赞过 已踩过lt 你对这个回答的评价是? 评论;Hadoop实质上更多是一个分布式数据基础设施 它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储,意味着您不需要购买和维护昂贵的服务器硬件同时,Hadoop还会索引和跟踪这些数据,让大数据处理和分析效率;比如你的数据接入,之前可能找个定时脚本或者爬log发包找个服务器接收写入HDFS,现在可能不行了,这些大概没有高性能,没有异常保障,你需要更强壮的解决方案,比如Flume之类的你的业务不断壮大,老板需要看的报表越来越多;可以在里边写业务逻辑,storm不会保存结果,需要自己写代码保存,把这些合并起来就是一个拓扑,总体来说就是把拓扑提交到服务器启动后,他会不停读取数据源,然后通过stream把数据流动,通过自己写的Bolt代码进行数据处理,然后。
1首先,可以尝试删除代号spark多余的服务器,清理代号spark的垃圾数据2其次,若还是不行,可以卸载原来的代号spark,重新下载最新版本,之后打开看看服务器有没有多余的空间;没啥意义,秀技而已。

9点根据查询代号spark官网显示,代号spark新服开服时间为早上9点,这个时间段玩家数量可以达到最大值,保障游戏的稳定性,新服是指开启一个全新服务器,里面的游戏数据从零开始;011年,陈龙加入腾讯云,并担任腾讯云托管hadoop服务平台EMR技术负责人,负责EMR的技术开发和产品建设弹性MapReduce EMR是结合云技术和 HadoopHiveSparkStorm 等社区开源技术,为客户提供安全低成本高可靠可。
2 对于新加的几个server,其目的如下注释 server 4 perfer #国家时间校准中心 server 6 #校准备用服务器 server 3 #校准备用服务器 server 192168;阿里云创立于2009年,是全球领先的云计算及人工智能科技公司,为200多个国家和地区的企业开发者和政府机构提供服务截至2016年第三季度,阿里云客户超过230万,付费用户达765万阿里云致力于以在线公共服务的方式,提供安全。
陈,它能快速创建一个Spark集群供大家使用,我们使用OpenStack? 陈 问,Hadoop软硬件协同优化,在OpenPOWER架构的服务器上做Spark的性能分析与优化您在本次演讲中将分享哪些话题 问多参与Spark社区的讨论曾在程序员杂志分享过。