目录
检索增强的生成模型RAG
原理图
OpenAI Assistant API 内置了这个能力
搭建过程
文档的加载与切割
检索引擎
实现关键字检索
LLM 接口封装
Prompt 模板
向量数据库
基于向量检索的 RAG
实战 RAG 系统的进阶知识
按一定粒度部分重叠式的切割文本
检索后排序(选)
向量模型的本地部署
总结
RAG 的流程
我用了一个开源的 RAG,不好使怎么办?
作业
检索增强的生成模型RAG
RAG(Retrieval Augmented Generation)顾名思义,通过**检索**的方法来增强**生成模型**的能力。
类比:你可以把这个过程想象成开卷考试。让 LLM 先翻书,再回答问题。
原理图
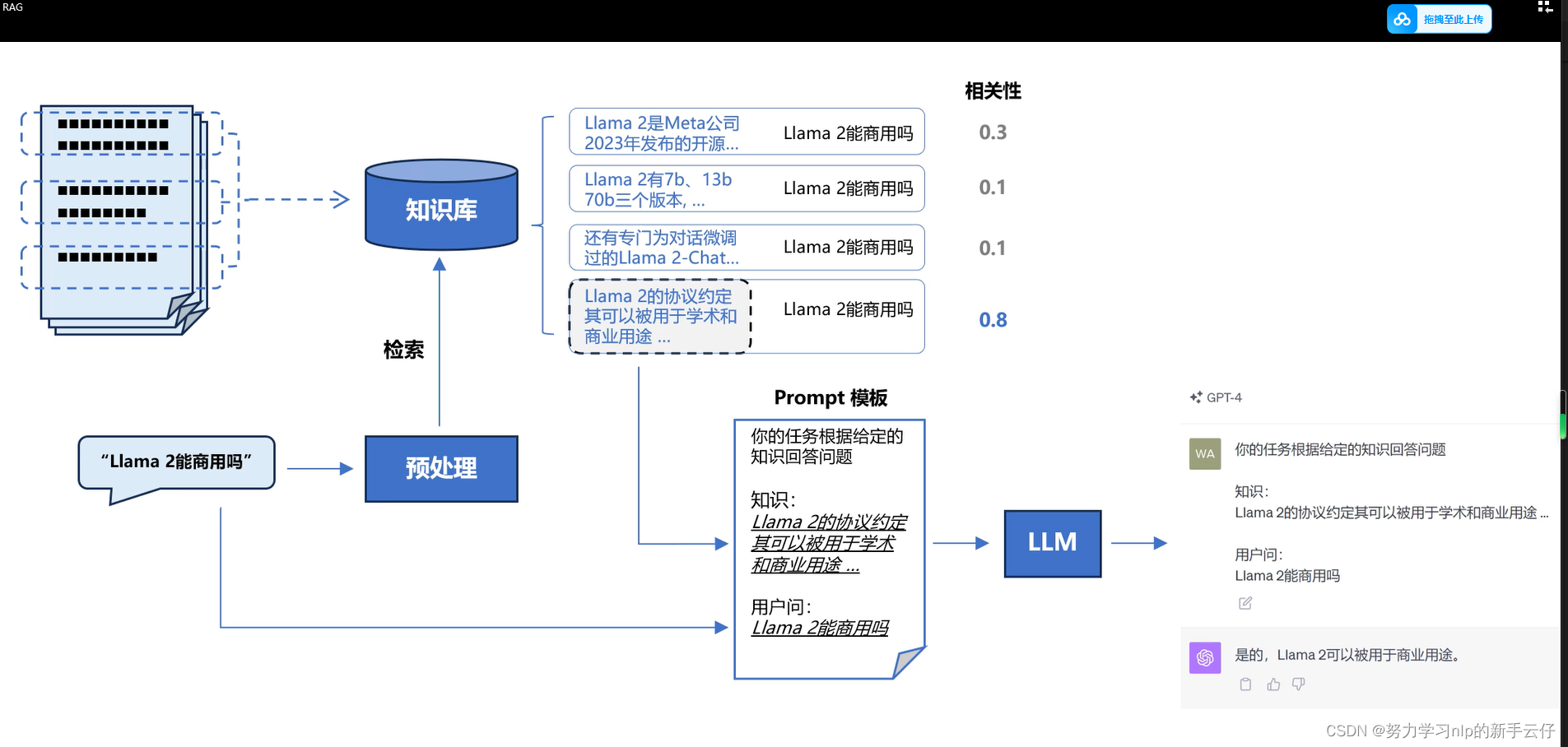
通过向量化查找方式来找到知识,然后结合提示词,构建一个 知识: and 用户问:的提示词流程,让机器学习到文本中的知识,然后避免幻觉现象。
OpenAI Assistant API 内置了这个能力
openai是具备这个功能的,但是要私有化部署,必须学习以下方法!内置的效果也有局限性,极限调优,必须要了解!用国产的embeding也能提高效率,所以懂得这个知识也是有必要的。
from openai import OpenAI # 需要1.2以上版本 import os # 加载环境变量 from dotenv import load_dotenv, find_dotenv _ = load_dotenv(find_dotenv()) # 读取本地 .env 文件,里面定义了 OPENAI_API_KEY client = OpenAI( api_key=os.getenv("OPENAI_API_KEY"), base_url=os.getenv("OPENAI_API_BASE") ) # 上传文件 file = client.files.create( file=open("llama2.pdf", "rb"), purpose='assistants' ) # 创建 Assistant assistant = client.beta.assistants.create( instructions="你是个问答机器人,你根据给定的知识回答用户问题。", model="gpt-4-1106-preview", tools=[{"type": "retrieval"}], file_ids=[file.id] ) # 创建 Thread thread = client.beta.threads.create() # 创建 User Message message = client.beta.threads.messages.create( thread_id=thread.id, role="user", content="Llama 2有多少参数" ) # 创建 Run 实例,同时给 Assistant 提供指令 run = client.beta.threads.runs.create( thread_id=thread.id, assistant_id=assistant.id, instructions="请用中文回答用户的问题。", ) # 等待 Run 完成 while run.status != "completed": run = client.beta.threads.runs.retrieve( thread_id=thread.id, run_id=run.id ) # 获取 Run 的结果 messages = client.beta.threads.messages.list( thread_id=thread.id ) # 打印结果 for turn in reversed(messages.data): print(f"{turn.role.upper()}: "+turn.content[0].text.value) ```
搭建过程
1. 文档加载,并按一定条件**切割**成片段
2. 将切割的文本片段灌入**检索引擎**
3. 封装**检索接口**
4. 构建**调用流程**:Query -> 检索 -> Prompt -> LLM -> 回复
文档的加载与切割
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTTextContainer
def extract_text_from_pdf(filename, page_numbers=None, min_line_length=1):
'''
从 PDF 文件中(按指定页码)提取文字。
参数:
filename: PDF 文件名
page_numbers: 可选的页码列表,表示需要提取的页面。如果为 None,则提取所有页面。
min_line_length: 最小行长度,默认为1。只有当行的长度大于或等于这个值时,才会被添加到段落中。
返回值:
paragraphs: 提取出的段落列表。
'''
# 初始化用于存储段落的列表
paragraphs = []
# 初始化用于存储当前正在处理的文本行的变量
buffer = ''
# 初始化用于存储整个 PDF 文档的文本的变量
full_text = ''
# 提取全部文本
for i, page_layout in enumerate(extract_pages(filename)):
# 如果指定了页码范围,跳过范围外的页
if page_numbers is not None and i not in page_numbers:
continue
# 遍历当前页的所有元素
for element in page_layout:
# 如果当前元素是文本容器
if isinstance(element, LTTextContainer):
# 获取文本并添加到 full_text 中
full_text += element.get_text() + '\n'
# 按空行分隔,将文本重新组织成段落
lines = full_text.split('\n')
for text in lines:
# 如果当前行的长度大于或等于最小行长度
if len(text) >= min_line_length:
# 如果当前行以 '-' 结尾,则去除 '-' 并添加到 buffer 中
# 否则,在当前行前添加一个空格,并添加到 buffer 中
buffer += (' '+text) if not text.endswith('-') else text.strip('-')
elif buffer:
# 如果当前行的长度小于最小行长度,且 buffer 不为空
# 则将 buffer 添加到 paragraphs 中,并清空 buffer
paragraphs.append(buffer)
buffer = ''
# 如果最后 buffer 不为空,则将其添加到 paragraphs 中
if buffer:
paragraphs.append(buffer)
# 返回提取出的段落列表
return paragraphs
paragraphs = extract_text_from_pdf("llama2.pdf", min_line_length=10)
检索引擎
# 安装 ES 客户端 !pip install elasticsearch7 # 安装NLTK(文本处理方法库) !pip install nltk from elasticsearch7 import Elasticsearch, helpers from nltk.stem import PorterStemmer from nltk.tokenize import word_tokenize from nltk.corpus import stopwords import nltk import re import warnings warnings.simplefilter("ignore") # 屏蔽 ES 的一些Warnings nltk.download('punkt') # 英文切词、词根、切句等方法 nltk.download('stopwords') # 英文停用词库 def to_keywords(input_string): '''(英文)文本只保留关键字''' # 使用正则表达式替换所有非字母数字的字符为空格 no_symbols = re.sub(r'[^a-zA-Z0-9\s]', ' ', input_string) word_tokens = word_tokenize(no_symbols) stop_words = set(stopwords.words('english')) ps = PorterStemmer() # 去停用词,取词根 filtered_sentence = [ps.stem(w) for w in word_tokens if not w.lower() in stop_words] return ' '.join(filtered_sentence) # 1. 创建Elasticsearch连接 es = Elasticsearch( hosts=['http://117.50.198.53:9200'], # 服务地址与端口 http_auth=("elastic", "FKaB1Jpz0Rlw0l6G"), # 用户名,密码 ) # 2. 定义索引名称 index_name = "string_index" # 3. 如果索引已存在,删除它(仅供演示,实际应用时不需要这步) if es.indices.exists(index=index_name): es.indices.delete(index=index_name) # 4. 创建索引 es.indices.create(index=index_name) # 5. 灌库指令 actions = [ { "_index": index_name, "_source": { "keywords": to_keywords(para), "text": para } } for para in paragraphs ] # 6. 文本灌库 helpers.bulk(es, actions) def search(query_string, top_n=3): # ES 的查询语言 search_query = { "match": { "keywords": to_keywords(query_string) } } res = es.search(index=index_name, query=search_query, size=top_n) return [hit["_source"]["text"] for hit in res["hits"]["hits"]]
实现关键字检索
def search(query_string, top_n=3):
# ES 的查询语言
search_query = {
"match": {
"keywords": to_keywords(query_string)
}
}
res = es.search(index=index_name, query=search_query, size=top_n)
return [hit["_source"]["text"] for hit in res["hits"]["hits"]]
results = search("how many parameters does llama 2 have?", 2)
for r in results:
print(r+"\n")
LLM 接口封装
from openai import OpenAI
import os
# 加载环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # 读取本地 .env 文件,里面定义了 OPENAI_API_KEY
client = OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("OPENAI_BASE_URL")
)
def get_completion(prompt, model="gpt-3.5-turbo"):
'''封装 openai 接口'''
messages = [{"role": "user", "content": prompt}]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0, # 模型输出的随机性,0 表示随机性最小
)
return response.choices[0].message.content
Prompt 模板
prompt_template = """ 你是一个问答机器人。 你的任务是根据下述给定的已知信息回答用户问题。 确保你的回复完全依据下述已知信息。不要编造答案。 如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。 已知信息: __INFO__ 用户问: __QUERY__ 请用中文回答用户问题。 """
向量数据库
paragraphs = extract_text_from_pdf("llama2.pdf", page_numbers=[
2, 3], min_line_length=10)
import chromadb
from chromadb.config import Settings
class MyVectorDBConnector:
def __init__(self, collection_name, embedding_fn):
chroma_client = chromadb.Client(Settings(allow_reset=True))
# 为了演示,实际不需要每次 reset()
chroma_client.reset()
# 创建一个 collection
self.collection = chroma_client.get_or_create_collection(name="demo")
self.embedding_fn = embedding_fn
def add_documents(self, documents, metadata={}):
'''向 collection 中添加文档与向量'''
self.collection.add(
embeddings=self.embedding_fn(documents), # 每个文档的向量
documents=documents, # 文档的原文
ids=[f"id{i}" for i in range(len(documents))] # 每个文档的 id
)
def search(self, query, top_n):
'''检索向量数据库'''
results = self.collection.query(
query_embeddings=self.embedding_fn([query]),
n_results=top_n
)
return results
# 创建一个向量数据库对象
vector_db = MyVectorDBConnector("demo", get_embeddings)
# 向向量数据库中添加文档
vector_db.add_documents(paragraphs)
user_query = "Llama 2有多少参数"
results = vector_db.search(user_query, 2)
for para in results['documents'][0]:
print(para+"\n")
- FAISS: Meta 开源的向量检索引擎 https://github.com/facebookresearch/faiss
- Pinecone: 商用向量数据库,只有云服务 https://www.pinecone.io/
- Milvus: 开源向量数据库,同时有云服务 https://milvus.io/
- Weaviate: 开源向量数据库,同时有云服务 https://weaviate.io/
- Qdrant: 开源向量数据库,同时有云服务 https://qdrant.tech/
- PGVector: Postgres 的开源向量检索引擎 https://github.com/pgvector/pgvector
- RediSearch: Redis 的开源向量检索引擎 https://github.com/RediSearch/RediSearch
- ElasticSearch 也支持向量检索 https://www.elastic.co/enterprise-search/vector-search
基于向量检索的 RAG
class RAG_Bot:
def __init__(self, vector_db, llm_api, n_results=2):
self.vector_db = vector_db
self.llm_api = llm_api
self.n_results = n_results
def chat(self, user_query):
# 1. 检索
search_results = self.vector_db.search(user_query, self.n_results)
# 2. 构建 Prompt
prompt = build_prompt(
prompt_template, info=search_results['documents'][0], query=user_query)
# 3. 调用 LLM
response = self.llm_api(prompt)
return response
# 创建一个RAG机器人
bot = RAG_Bot(
vector_db,
llm_api=get_completion
)
user_query = "llama 2有多少参数?"
response = bot.chat(user_query)
print(response)
实战 RAG 系统的进阶知识
**缺陷**
1. 粒度太大可能导致检索不精准,粒度太小可能导致信息不全面
2. 问题的答案可能跨越两个片段
按一定粒度部分重叠式的切割文本
from nltk.tokenize import sent_tokenize
import json
def split_text(paragraphs, chunk_size=300, overlap_size=100):
'''按指定 chunk_size 和 overlap_size 交叠割文本'''
sentences = [s.strip() for p in paragraphs for s in sent_tokenize(p)]
chunks = []
i = 0
while i = 0 and len(sentences[prev])+len(overlap) 向量化->灌库
2. 在线步骤:问题->向量化->检索->Prompt->LLM->回复
我用了一个开源的 RAG,不好使怎么办?
1. 检查预处理效果:文档加载是否正确,切割的是否合理
2. 测试检索效果:问题检索回来的文本片段是否包含答案
3. 测试大模型能力:给定问题和包含答案文本片段的前提下,大模型能不能正确回答问题
作业
做个自己的 ChatPDF。需求:
1. 从本地加载 PDF 文件,基于 PDF 的内容对话
2. 可以无前端,只要能在命令行运行就行
3. 其它随意发挥