

系列篇章💥
AI大模型探索之路-训练篇1:大语言模型微调基础认知
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
AI大模型探索之路-训练篇3:大语言模型全景解读
AI大模型探索之路-训练篇4:大语言模型训练数据集概览
AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化
AI大模型探索之路-训练篇6:大语言模型预训练数据准备-预处理
AI大模型探索之路-训练篇7:大语言模型Transformer库之HuggingFace介绍
AI大模型探索之路-训练篇8:大语言模型Transformer库-预训练流程编码体验
AI大模型探索之路-训练篇9:大语言模型Transformer库-Pipeline组件实践
AI大模型探索之路-训练篇10:大语言模型Transformer库-Tokenizer组件实践
AI大模型探索之路-训练篇11:大语言模型Transformer库-Model组件实践
目录
- 系列篇章💥
- 前言
- 一、在线加载数据集
- 1、加载数据集
- 2、加载数据集合集中的某一项任务
- 3、按照数据集划分进行加载
- 二、查看数据集
- 1、查看索引为1的数据
- 2、查看数据集前2条数据
- 3、获取训练集中标题列的前5个元素
- 4、获取训练集的列名
- 5、获取训练集中的特征信息
- 三、数据集划分
- 1、按占比划分
- 2、按占比划分&分层抽样
- 四、数据集选取,过滤,映射
- 1、索引过滤
- 2、字符过滤
- 3、数据映射过滤
- 4、输入准备
- 5、多进程并行处理
- 6、分批处理
- 7、批处理&移除列
- 五、数据集保存与加载
- 1、保存数据集到本地
- 2、加载本地数据集
- 六、加载本地数据集
- 1、load_dataset直接加载本地文件
- 2、Dataset.from_csv加载本地文件
- 3、pandas库的read_csv方法加载本地文件
- 4、pandas对象转化为数据集
- 5、自定义List加载数据集
- 6、通过JSON加载数据集
- 7、自定义脚本加载数据集
- 七、DataCollator
- 1、加载数据集
- 2、数据处理
- 3、数据填充
- 总结
前言
在AI语言模型学习任务中,数据是至关重要的部分。一个高质量的数据集不仅决定了模型的上限,还影响着模型训练的效率和效果。然而,获取、处理和组织数据往往耗时耗力。为了简化这一过程,Hugging Face推出了Datasets组件,它集成了多种公开数据集,支持在线加载、筛选和预处理等功能。通过本文的介绍,我们将了解到如何利用Datasets组件快速加载和处理数据,为模型训练打下坚实基础。
本文将从在线加载数据集开始,逐步介绍如何查看、划分、选取、过滤和映射数据集。接着,我们将讨论如何保存和加载处理好的数据集,以及如何使用DataCollator进行数据填充等后处理操作。最后,我们还将探讨如何通过自定义脚本加载非标准格式的数据集。通过这些内容,我们将掌握Datasets组件的基本用法,提高数据处理的效率和质量。
官网API:https://huggingface.co/docs/datasets/index
一、在线加载数据集
1、加载数据集
安装依赖
pip install datasets
加载数据集:使用load_dataset函数,可以通过数据集名称、数据集文件路径等方式加载数据集
查看在线数据集信息:
代码实现如下:
from datasets import load_dataset datasets = load_dataset("madao33/new-title-chinese") datasets输出
DatasetDict({ train: Dataset({ features: ['title', 'content'], num_rows: 5850 }) validation: Dataset({ features: ['title', 'content'], num_rows: 1679 }) })2、加载数据集合集中的某一项任务
加载数据集合集中的某一项任务,加载布尔问答任务数据集。
查看在线数据集信息:
代码实现
boolq_dataset = load_dataset("super_glue", "boolq") boolq_dataset输出
DatasetDict({ train: Dataset({ features: ['question', 'passage', 'idx', 'label'], num_rows: 9427 }) validation: Dataset({ features: ['question', 'passage', 'idx', 'label'], num_rows: 3270 }) test: Dataset({ features: ['question', 'passage', 'idx', 'label'], num_rows: 3245 }) })3、按照数据集划分进行加载
1)使用train关键字加载训练数据集
dataset = load_dataset("madao33/new-title-chinese", split="train") dataset输出
Dataset({ features: ['title', 'content'], num_rows: 5850 })2)按区间加载训练数据集
dataset = load_dataset("madao33/new-title-chinese", split="train[10:100]") dataset输出
Dataset({ features: ['title', 'content'], num_rows: 90 })3)按百分比加载数据集
dataset = load_dataset("madao33/new-title-chinese", split="train[:50%]") dataset输出
Dataset({ features: ['title', 'content'], num_rows: 2925 })加载名为"madao33/new-title-chinese"的数据集,并将其划分为训练集的前50%和后50%
dataset = load_dataset("madao33/new-title-chinese", split=["train[:50%]", "train[50%:]"]) dataset输出
[Dataset({ features: ['title', 'content'], num_rows: 2925 }), Dataset({ features: ['title', 'content'], num_rows: 2925 })]二、查看数据集
可以使用索引、切片等方式查看数据集中的部分数据
datasets = load_dataset("madao33/new-title-chinese") datasets输出
DatasetDict({ train: Dataset({ features: ['title', 'content'], num_rows: 5850 }) validation: Dataset({ features: ['title', 'content'], num_rows: 1679 })1、查看索引为1的数据
datasets["train"][1]
输出
{'title': '大力推进高校治理能力建设', 'content': '在推进“双一流”高校建设进程中,我们要紧紧围绕为党育人、为国育才,找准问题、破解难题,以一流意识和担当精神,大力推进高校的治理能力建设。\n增强政治引领力。坚持党对高校工作的全面领导,始终把政治建设摆在首位,增强校党委的政治领导力,全面推进党的建设各项工作。落实立德树人根本任务,把培养社会主义建设者和接班人放在中心位置。紧紧抓住思想政治工作这条生命线,全面加强师生思想政治工作,推进“三全育人”综合改革,将思想政治工作贯穿学校教育管理服务全过程,努力让学生成为德才兼备、全面发展的人才。\n提升人才聚集力。人才是创新的核心要素,创新驱动本质上是人才驱动。要坚持引育并举,建立绿色通道,探索知名专家举荐制,完善“一事一议”支持机制。在大力支持自然科学人才队伍建设的同时,实施哲学社会科学人才工程。立足实际,在条件成熟的学院探索“一院一策”改革。创新科研组织形式,为人才成长创设空间,建设更加崇尚学术、更加追求卓越、更加关爱学生、更加担当有为的学术共同体。\n培养学生竞争力。遵循学生成长成才的规律培育人才,着力培养具有国际竞争力的拔尖创新人才和各类专门人才,使优势学科、优秀教师、优质资源、优良环境围绕立德树人的根本任务配置。淘汰“水课”,打造“金课”,全力打造世界一流本科教育。深入推进研究生教育综合改革,加强事关国家重大战略的高精尖急缺人才培养,建设具有国际竞争力的研究生教育。\n激发科技创新力。在国家急需发展的领域挑大梁,就要更加聚焦科技前沿和国家需求,狠抓平台建设,包括加快牵头“武汉光源”建设步伐,积极参与国家实验室建设,建立校级大型科研仪器设备共享平台。关键核心技术领域“卡脖子”问题,归根结底是基础科学研究薄弱。要加大基础研究的支持力度,推进理论、技术和方法创新,鼓励支持重大原创和颠覆性技术创新,催生一批高水平、原创性研究成果。\n发展社会服务力。在贡献和服务中体现价值,推动合作共建、多元投入的格局,大力推进政产学研用结合,强化科技成果转移转化及产业化。探索校城融合发展、校地联动发展的新模式,深度融入地方创新发展网络,为地方经济社会发展提供人才支撑,不断拓展和优化社会服务网络。\n涵育文化软实力。加快体制机制改革,优化学校、学部、学院三级评审机制,充分发挥优秀学者特别是德才兼备的年轻学者在学术治理中的重要作用。牢固树立一流意识、紧紧围绕一流目标、认真执行一流标准,让成就一流事业成为普遍追求和行动自觉。培育具有强大凝聚力的大学文化,营造积极团结、向上向善、干事创业的氛围,让大学成为吸引和留住一大批优秀人才建功立业的沃土,让敢干事、肯干事、能干事的人有更多的荣誉感和获得感。\n建设中国特色、世界一流大学不是等得来、喊得来的,而是脚踏实地拼出来、干出来的。对标一流,深化改革,坚持按章程办学,构建以一流质量标准为核心的制度规范体系,扎实推进学校综合改革,探索更具活力、更富效率的管理体制和运行机制,我们就一定能构建起具有中国特色的现代大学治理体系,进一步提升管理服务水平和工作效能。\n(作者系武汉大学校长)'}2、查看数据集前2条数据
datasets["train"][:2]
3、获取训练集中标题列的前5个元素
datasets["train"]["title"][:5]
输出
['望海楼X国打“WW牌”是危险的赌博', '大力推进高校治理能力建设', '坚持事业为上选贤任能', '“大朋友”的话儿记心头', '用好可持续发展这把“金钥匙”']
4、获取训练集的列名
datasets["train"].column_names
输出
['title', 'content']
5、获取训练集中的特征信息
datasets["train"].features
输出
{'title': Value(dtype='string', id=None), 'content': Value(dtype='string', id=None)}三、数据集划分
1、按占比划分
使用train_test_split方法将数据集划分为训练集和测试集,其中测试集占比为0.1
dataset = datasets["train"] dataset.train_test_split(test_size=0.1)
输出
DatasetDict({ train: Dataset({ features: ['title', 'content'], num_rows: 5265 }) test: Dataset({ features: ['title', 'content'], num_rows: 585 }) })2、按占比划分&分层抽样
使用train_test_split方法将数据集划分为训练集和测试集,其中测试集占比为0.1,并按照"label"列进行分层抽样
dataset = boolq_dataset["train"] ## 参数"stratify_by_column="label""表示按照数据集中的"label"列进行分层抽样, ## 保证训练集和测试集中各类别的样本比例与原始数据集中的比例相同 dataset.train_test_split(test_size=0.1, stratify_by_column="label") # 分类数据集可以按照比例划分
输出
DatasetDict({ train: Dataset({ features: ['question', 'passage', 'idx', 'label'], num_rows: 8484 }) test: Dataset({ features: ['question', 'passage', 'idx', 'label'], num_rows: 943 })四、数据集选取,过滤,映射
1、索引过滤
选择训练集中索引为0和1的数据
# 选取 datasets["train"].select([0, 1])
输出
Dataset({ features: ['title', 'content'], num_rows: 2 })2、字符过滤
过滤训练集中标题包含"中国"的数据,获取过滤后的训练集的前5个标题
# 过滤 filter_dataset = datasets["train"].filter(lambda example: "中国" in example["title"]) filter_dataset["title"][:5]
['聚焦两会,世界探寻中国成功秘诀', '望海楼中国经济的信心来自哪里', '“中国奇迹”助力世界减贫跑出加速度', '和音瞩目历史交汇点上的中国', '中国风采感染世界']
3、数据映射过滤
通过函数进行数据集过滤
# 映射(map) def add_prefix(example): example["title"] = 'Prefix: ' + example["title"] return example prefix_dataset = datasets.map(add_prefix) prefix_dataset["train"][:10]["title"]输出
['Prefix: 望海楼X国打“WW牌”是危险的赌博', 'Prefix: 大力推进高校治理能力建设', 'Prefix: 坚持事业为上选贤任能', 'Prefix: “大朋友”的话儿记心头', 'Prefix: 用好可持续发展这把“金钥匙”', 'Prefix: 跨越雄关,我们走在大路上', 'Prefix: 脱贫奇迹彰显政治优势', 'Prefix: 拱卫亿万人共同的绿色梦想', 'Prefix: 为党育人、为国育才', 'Prefix: 净化网络语言']
4、输入准备
使用分词器对样本的内容和标题进行编码。编码后的结果存储在model_inputs字典中,其中labels键用于存储标题编码的结果,进行输出备用
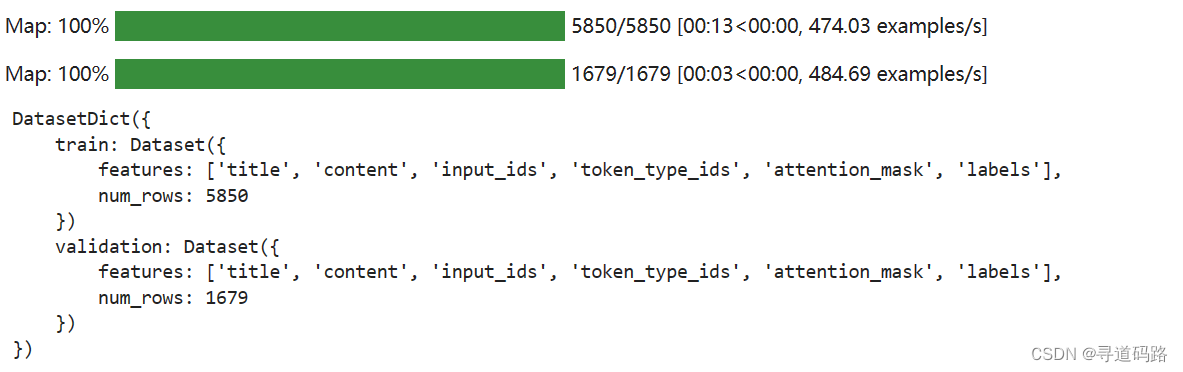
from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese") def preprocess_function(example): model_inputs = tokenizer(example["content"], max_length=512, truncation=True) labels = tokenizer(example["title"], max_length=32, truncation=True) # labels就是title编码的结果 # "labels"键是用来存储标题编码结果的。在训练模型时,我们通常需要指定输入的标签或目标,以便计算损失函数并进行模型优化 model_inputs["labels"] = labels["input_ids"] return model_inputs
processed_datasets = datasets.map(preprocess_function) processed_datasets
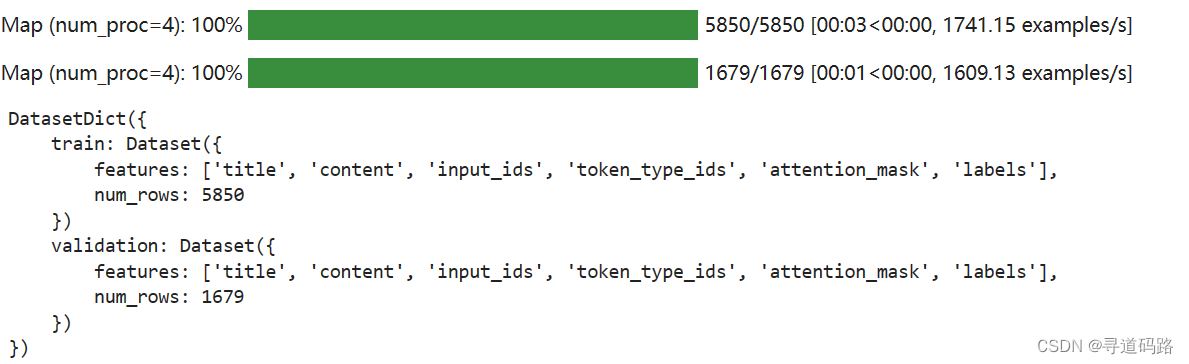
5、多进程并行处理
使用了4个进程并行地对数据集进行处理,以提高处理速度
processed_datasets = datasets.map(preprocess_function, num_proc=4) processed_datasets
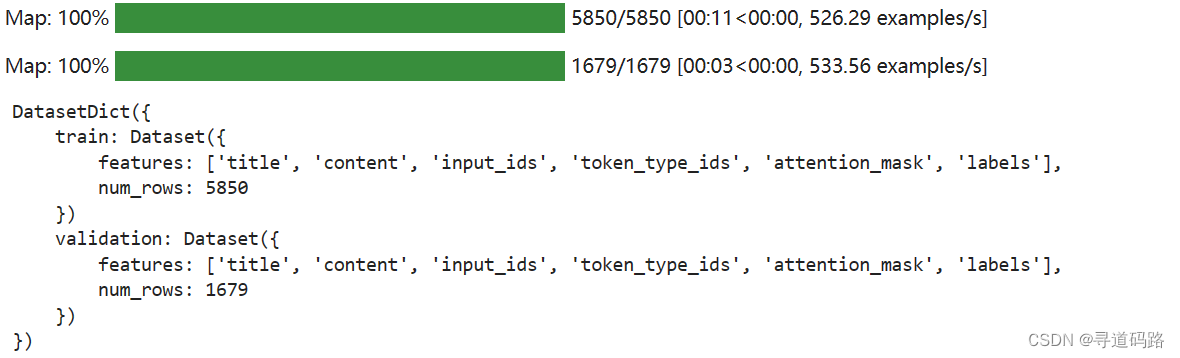
6、分批处理
使用了批处理的方式对数据集进行处理,可以处理较大的数据集
processed_datasets = datasets.map(preprocess_function, batched=True) processed_datasets
7、批处理&移除列
使用批处理的方式对数据集进行处理,并且移除了原始数据集中的列信息,只保留了处理后的数据集。
processed_datasets = datasets.map(preprocess_function, batched=True, remove_columns=datasets["train"].column_names) processed_datasets
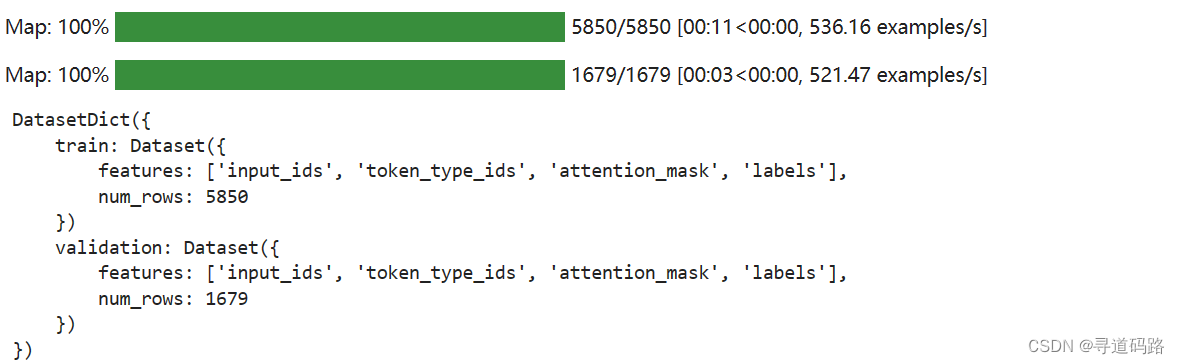
五、数据集保存与加载
1、保存数据集到本地
将处理后的数据集processed_datasets保存到当前目录下的"./processed_data"文件夹中。
processed_datasets.save_to_disk("./processed_data")
执行完成后,本地新增了processed_data文件夹
2、加载本地数据集
从当前目录下的"./processed_data"文件夹中加载数据集,并将其赋值给变量processed_datasets。
processed_datasets = load_from_disk("./processed_data") processed_datasets
六、加载本地数据集
1、load_dataset直接加载本地文件
使用load_dataset函数从指定的文件路径中加载数据集,并将其赋值给变量dataset。其中,data_files参数指定了数据集的文件路径,split参数指定了要加载的数据集的划分方式(这里是"train")。
dataset = load_dataset("csv", data_files="/root/pretrains/ChnSentiCorp_htl_all/ChnSentiCorp_htl_all.csv", split="train") dataset输出

2、Dataset.from_csv加载本地文件
使用Dataset.from_csv方法从指定的文件路径中加载数据集,并将其赋值给变量dataset。
dataset = Dataset.from_csv("/root/pretrains/ChnSentiCorp_htl_all/ChnSentiCorp_htl_all.csv") dataset输出

3、pandas库的read_csv方法加载本地文件
通过预先加载的其他格式转换加载数据集
使用pandas库的read_csv方法从指定的文件路径中读取CSV格式的数据,并将其赋值给变量data。
import pandas as pd data = pd.read_csv("/root/pretrains/ChnSentiCorp_htl_all/ChnSentiCorp_htl_all.csv") data.head()
4、pandas对象转化为数据集
使用Dataset.from_pandas方法将data转换为datasets对象,并将其赋值给变量dataset。
dataset = Dataset.from_pandas(data) dataset
输出
Dataset({ features: ['label', 'review'], num_rows: 7766 })5、自定义List加载数据集
定义了一个包含两个字典的列表data,每个字典表示一个样本,其中键为"text",值为字符串类型的文本数据。然后使用Dataset.from_list方法将data转换为datasets对象,并将其赋值给变量dataset。
# List格式的数据需要内嵌{},明确数据字段 data = [{"text": "abc"}, {"text": "def"}] # data = ["abc", "def"] Dataset.from_list(data)输出
Dataset({ features: ['text'], num_rows: 2 })6、通过JSON加载数据集
使用load_dataset函数从指定的JSON文件中加载数据集,并将其赋值给变量dataset。其中,field参数指定了要加载的数据集的字段名(这里是"data")。
load_dataset("json", data_files="./cmrc2018_trial.json", field="data")输出

7、自定义脚本加载数据集
使用自定义的加载脚本load_script.py加载数据集,并将其赋值给变量dataset。其中,split参数指定了要加载的数据集的划分方式(这里是"train")
dataset = load_dataset("./load_script.py", split="train") dataset输出

dataset[0]
输出
{'id': 'TRIAL_800_QUERY_0', 'context': '基于《跑跑卡丁车》与《泡泡堂》上所开发的游戏,由韩国Nexon开发与发行。中国大陆由盛大游戏运营,这是Nexon时隔6年再次授予盛大网络其游戏运营权。台湾由游戏橘子运营。玩家以水枪、小枪、锤子或是水炸弹泡封敌人(玩家或NPC),即为一泡封,将水泡击破为一踢爆。若水泡未在时间内踢爆,则会从水泡中释放或被队友救援(即为一救援)。每次泡封会减少生命数,生命数耗完即算为踢爆。重生者在一定时间内为无敌状态,以踢爆数计分较多者获胜,规则因模式而有差异。以2V2、4V4随机配对的方式,玩家可依胜场数爬牌位(依序为原石、铜牌、银牌、金牌、白金、钻石、大师) ,可选择经典、热血、狙击等模式进行游戏。若游戏中离,则4分钟内不得进行配对(每次中离+4分钟)。开放时间为暑假或寒假期间内不定期开放,8人经典模式随机配对,采计分方式,活动时间内分数越多,终了时可依该名次获得奖励。', 'question': '生命数耗完即算为什么?', 'answers': {'text': ['踢爆'], 'answer_start': [127]}}load.script.py
import json import datasets from datasets import DownloadManager, DatasetInfo class CMRC2018TRIAL(datasets.GeneratorBasedBuilder): def _info(self) -> DatasetInfo: """ info方法, 定义数据集的信息,这里要对数据的字段进行定义 :return: """ return datasets.DatasetInfo( description="CMRC2018 trial", features=datasets.Features({ "id": datasets.Value("string"), "context": datasets.Value("string"), "question": datasets.Value("string"), "answers": datasets.features.Sequence( { "text": datasets.Value("string"), "answer_start": datasets.Value("int32"), } ) }) ) def _split_generators(self, dl_manager: DownloadManager): """ 返回datasets.SplitGenerator 涉及两个参数: name和gen_kwargs name: 指定数据集的划分 gen_kwargs: 指定要读取的文件的路径, 与_generate_examples的入参数一致 :param dl_manager: :return: [ datasets.SplitGenerator ] """ return [datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"filepath": "./cmrc2018_trial.json"})] def _generate_examples(self, filepath): """ 生成具体的样本, 使用yield 需要额外指定key, id从0开始自增就可以 :param filepath: :return: """ # Yields (key, example) tuples from the dataset with open(filepath, encoding="utf-8") as f: data = json.load(f) for example in data["data"]: for paragraph in example["paragraphs"]: context = paragraph["context"].strip() for qa in paragraph["qas"]: question = qa["question"].strip() id_ = qa["id"] answer_starts = [answer["answer_start"] for answer in qa["answers"]] answers = [answer["text"].strip() for answer in qa["answers"]] yield id_, { "context": context, "question": question, "id": id_, "answers": { "answer_start": answer_starts, "text": answers, }, }七、DataCollator
DataCollatorWithPadding是Hugging Face Transformers库中的一个类,用于处理文本数据。它的主要功能和作用如下:
- 填充(Padding): DataCollatorWithPadding可以将不同长度的文本序列进行填充,使它们具有相同的长度。这对于批量输入到神经网络模型中非常重要,因为模型通常要求输入数据具有相同的形状。
- 动态填充(Dynamic Padding): DataCollatorWithPadding可以根据输入数据的最大长度动态地调整填充的长度。这意味着如果一个批次中的最长文本序列长度为100,那么所有其他较短的文本序列将被填充至长度为100。
- 指定填充值(Padding Value): DataCollatorWithPadding允许用户指定填充值,默认为0。这可以用于区分填充部分和实际文本内容。
- 支持多种框架(Framework Support): DataCollatorWithPadding支持多种深度学习框架,包括PyTorch、TensorFlow等。这使得用户可以在不同的框架之间灵活切换,而无需更改数据处理代码。
DataCollatorWithPadding是一个功能强大的工具,可以帮助用户在处理文本数据时进行填充操作,确保输入数据的一致性和模型训练的稳定性。
1、加载数据集
加载CSV格式的数据集,并对数据进行过滤
from transformers import DataCollatorWithPadding dataset = load_dataset("csv", data_files="/root/pretrains/ChnSentiCorp_htl_all/ChnSentiCorp_htl_all.csv", split='train') dataset = dataset.filter(lambda x: x["review"] is not None) dataset输出

2、数据处理
函数的作用是对输入的文本数据进行分词和截断处理,并将标签添加到结果中
def process_function(examples): tokenized_examples = tokenizer(examples["review"], max_length=128, truncation=True) tokenized_examples["labels"] = examples["label"] return tokenized_examples tokenized_dataset = dataset.map(process_function, batched=True, remove_columns=dataset.column_names) tokenized_dataset
打印前4个样本的信息
print(tokenized_dataset[:4])

3、数据填充
创建DataCollatorWithPadding对象,用于对数据进行填充
collator = DataCollatorWithPadding(tokenizer=tokenizer) collator
输出
DataCollatorWithPadding(tokenizer=BertTokenizerFast(name_or_path='bert-base-chinese', vocab_size=21128, model_max_length=512, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True), added_tokens_decoder={ 0: AddedToken("[PAD]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True), 100: AddedToken("[UNK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True), 101: AddedToken("[CLS]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True), 102: AddedToken("[SEP]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True), 103: AddedToken("[MASK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True), }, padding=True, max_length=None, pad_to_multiple_of=None, return_tensors='pt')创建DataLoader对象,指定批量大小为4,使用collator进行数据填充,并进行随机打乱
from torch.utils.data import DataLoader dl = DataLoader(tokenized_dataset, batch_size=4, collate_fn=collator, shuffle=True) #获取下一个批次的数据 next(enumerate(dl))
输出
(0, {'input_ids': tensor([[ 101, 1057, 857, 749, 6121, 3124, 2145, 2791, 8024, 2600, 860, 3341, 6432, 8024, 6983, 2421, 6820, 679, 7231, 8024, 3302, 1218, 1447, 4638, 5162, 6574, 738, 3683, 6772, 7770, 511, 2215, 1071, 3221, 6121, 3124, 3517, 2231, 4638, 3302, 1218, 1447, 966, 2533, 6134, 2813, 511, 704, 7623, 7667, 4638, 3343, 2376, 5831, 2523, 1962, 1391, 8024, 4384, 1862, 738, 6820, 679, 7231, 8024, 966, 2533, 2972, 5773, 8013, 6432, 6432, 5375, 4157, 1416, 8038, 1765, 3175, 3300, 671, 4157, 974, 8024, 4895, 6205, 3959, 1920, 5276, 8115, 1146, 7164, 6756, 4923, 8024, 2802, 6756, 679, 2159, 3211, 8024, 679, 6814, 680, 2791, 817, 1276, 6981, 3341, 4692, 738, 5050, 1394, 4415, 511, 852, 3297, 1400, 671, 1921, 6842, 2791, 3198, 8024, 2769, 812, 2347, 5307, 102], [ 101, 2600, 860, 2697, 6230, 679, 7231, 119, 817, 3419, 6844, 704, 119, 4500, 7623, 3340, 816, 671, 5663, 119, 6983, 2421, 5632, 2346, 4638, 7623, 1324, 679, 1922, 1962, 117, 7392, 1880, 4638, 1920, 6825, 3862, 7831, 7623, 7667, 2213, 1377, 117, 852, 679, 5543, 1762, 6983, 2421, 2145, 2791, 5041, 1296, 117, 679, 3221, 2523, 3175, 912, 119, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [ 101, 2791, 7313, 3300, 5273, 510, 7942, 510, 5905, 676, 4905, 5682, 6444, 511, 1057, 857, 3198, 8024, 1184, 1378, 6820, 712, 1220, 6418, 7309, 6848, 2885, 1525, 4905, 7582, 5682, 4638, 2791, 7313, 119, 2414, 677, 4500, 1501, 2523, 5653, 6844, 119, 2697, 6230, 3221, 1059, 3469, 4638, 511, 2791, 7313, 6006, 2207, 8024, 852, 6163, 934, 7599, 3419, 4324, 4294, 8024, 966, 2533, 671, 857, 511, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [ 101, 2496, 1765, 3297, 1962, 4638, 8024, 1762, 1059, 1744, 5050, 2595, 817, 3683, 679, 7231, 4638, 758, 3215, 5277, 6983, 2421, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'labels': tensor([1, 1, 1, 1])})总结
本文介绍了Hugging Face Transformer库中的Datasets组件,包括如何加载数据集、查看数据集、划分数据集、选择、过滤和映射数据集、保存和加载数据集以及使用DataCollator处理文本数据。通过这些功能,可以方便地对数据集进行预处理和后处理,为训练AI模型提供高质量的数据。

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!







