

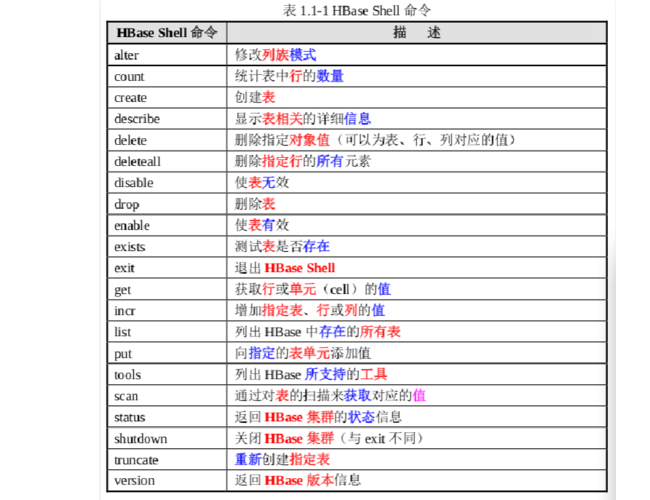
简介:
HBase Shell 是一种操作HBase的交互模式,支持完整的HBase命令集。
(图片来源网络,侵删)
hbase shell # 打开Hbase Shell
目录:
| 命令类别 | 常用命令 |
|---|---|
| General | version,status,whoami,help |
| DDL | alter,creater,describe,disable,drop,enable,exists,is_disabled,is_enabled,list, |
| DML | count,delete,deleteall,get,get_counter,incr,put,scan,truncate |
| Tools | assign,balance_switch,balancer,close_region,compact,flush,major_compact,move,split,unassign,zk_dump |
| Replication | add_peer,disable_peer,enable_peer,remove_peer,start_replication,stop_replication |
一、General(通用操作)
help # 显示hbase shell的帮助信息,包括可用的命令列表、命令的简要描述以及如何使用这些命令等。 help 'status' # 获取命令的详细信息 version # 查看HBase的版本信息。 status # 查看HBase集群的状态,包括集群是否运行正常、各RegionServer的状态等。 whoami # 查看当前在Hbase shell中登录的用户信息
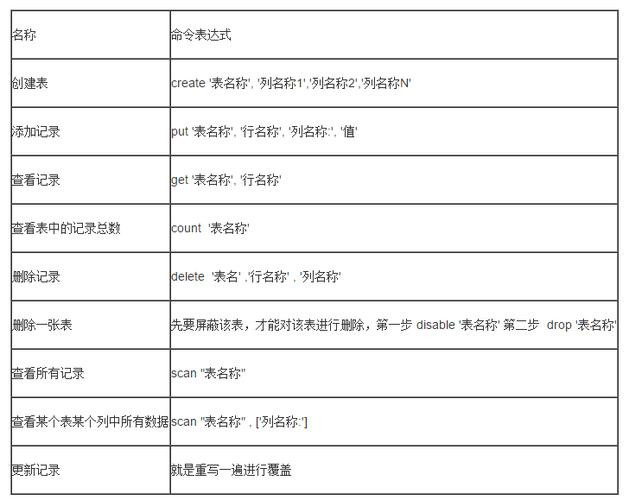
二、DDL(数据定义语言)
主要用于定义、修改和删除数据库对象,如表、视图、索引等
(图片来源网络,侵删)
1、命名空间
-
命令格式
list_namespace # 列出命名空间 create_namespace "NAME" # 创建一个新的命名空间 list_namespace_tables 'NAME' # 列出命名空间下的表 drop_namespace 'NAME' # 删除命名空间,需要删除改命名空间下的所有表后才能删除
- NAME:命名空间名称
-
案例
list_namespace # 列出命名空间 create_namespace "hbase_test" # 创建命名空间名为hbase_test list_namespace_tables 'hbase_test' # 列出hbase_test命名空间下的表,发现是空的则可以删除该命名空间 drop_namespace 'hbase_test' # 删除命名空间hbase_test
2、数据表格
-
命令格式
创建表
create "[NAMESPACE:]TABLE",{NAME=>"cf1",VERSIONS=1, ...},...,{NAME=>"cfn",VERSIONS=1,...} # 创建表 list_namespace_tables "NAMESPACE" # 列出该命名空间的所有表 desc "[NAMESPACE:]TABLE" # 查看表的详细信息 exists "[NAMESPACE:]TABLE" # 判断表是否存在修改表:存在则覆盖,不存在则追加
alter "[NAMESPACE:]TABLE","cf1" # 给表添加列族cf1...
删除列族
alter "[NAMESPACE:]TABLE","delete"=>"cf1" # 删除列族cf1 is_enabled "[NAMESPACE:]TABLE" # 这个命令用于检查指定表是否已启用 is_disabled "[NAMESPACE:]TABLE" # 这个命令用于检查指定表是否已被禁用 enable "[NAMESPACE:]TABLE" # 启用一个被禁用的表 disable "[NAMESPACE:]TABLE" # 禁用一个表
删除表之前必须先禁用
drop "[NAMESPACE:]TABLE" # 删除表
- NAMESPACE:命名空间的名称
- [NAMESPACE:]TABLE:要创建的表的名称,哪个命名空间下的哪找表,[ ]代表里面的值可以省略
- {NAME=>"cf1",VERSIONS=1, ...},...:定义了表的列族及其属性
- cf1~cfn:列族名称
- VERSIONS=1:每个列族指定版本数
-
案例
存在创建表
exists "hbase_test:student_info" # 判断hbase_test命名空间下是否有student_info表 create "hbase_test:student_info","base","scores" #在hbase_test命名空间下创建了一个表叫student_info,含有两个列族base,scores list_namespace_tables "hbase_test" # 列出hbase_test命名空间的所有表
查看修改表
alter "hbase_test:student_info", "base2" # hbase_test命名空间下student_info表,添加列族base2 desc "hbase_test:student_info" # 查看hbase_test命名空间下student_info表的详细信息 alter "hbase_test:student_info","delete"=>"base2" # 删除列族base2
禁用删除表
is_enabled "hbase_test:student_info" # 检查指定表是否已启用 disable "hbase_test:student_info" # 禁用一个表 drop "hbase_test:student_info" # 删除表
三、DML(数据操纵语言)
则主要用于插入、更新、删除和查询数据库中的数据
-
命令格式
新增数据
put "[NAMESPACE:]TABLE","ROW_KEY","CF:CN",VALUE
查看数据
count "[NAMESPACE:]TABLE" # 计算表中行的数量 get "[NAMESPACE:]TABLE","ROW_KEY" # 表中指定行键(ROW_KEY)的所有列和最新版本的数据 get "[NAMESPACE:]TABLE","ROW_KEY","CF" # 表中指定行键(ROW_KEY)和列族(CF)的所有列的数据。 get "[NAMESPACE:]TABLE","ROW_KEY","CF:CN" # 表中指定行键(ROW_KEY)、列族(CF)和列限定符(CN)的单个单元格的数据。 # 扫描HBase表中的数据。它接受一个参数列表,用于指定扫描的各种选项和过滤器 scan "[NAMESPACE:]TABLE",{VERSIONS => 5, FILTER => "KeyOnlyFilter(true)", ROWPREFIXFILTER => 'row_key'}删除数据
delete "[NAMESPACE:]TABLE","ROW_KEY","CF:CN" # 删除单元格最近版本数据 deleteall "[NAMESPACE:]TABLE","ROW_KEY","CF:CN" # 删除字段 deleteall "[NAMESPACE:]TABLE","ROW_KEY" # 删除整行 truncate "[NAMESPACE:]TABLE" # 删除所有数据
计数器列相关的操作
#确保指定的表、行键和列存在,并且列的类型是计数器列 #针对不存在的列操作,针对存在的列会报错 Field is not a long, it's 10 bytes wide incr "[NAMESPACE:]TABLE","ROW_KEY","cf:cn",N # 原子性地增加一个计数器列的值 get_counter "[NAMESPACE:]TABLE","ROW_KEY","cf:cn" # 用于获取计数器列的当前值
- ROW_KEY:行键
- CF:CN:列族:列限定符
- FILTER => "KeyOnlyFilter(true)":应用一个过滤器,只返回键而不返回值
- ROWPREFIXFILTER => 'row_key':应用一个行前缀过滤器,只返回行键以row_key为前缀的行。
-
案例
新增数据
# 新增三个学生信息 put "hbase_test:student_info","1","base:name","张老三" put "hbase_test:student_info","1","base:age",22 put "hbase_test:student_info","1","base:gender","男" put "hbase_test:student_info","1","scores:hive",72 put "hbase_test:student_info","1","scores:hbase",88 put "hbase_test:student_info","2","base:name","张老二" put "hbase_test:student_info","2","base:age",26 put "hbase_test:student_info","2","base:gender","女" put "hbase_test:student_info","2","scores:hive",66 put "hbase_test:student_info","2","scores:hbase",35 put "hbase_test:student_info","3","base:name","张老大" put "hbase_test:student_info","3","base:age",35 put "hbase_test:student_info","3","base:gender","男" put "hbase_test:student_info","3","scores:hive",89 put "hbase_test:student_info","3","scores:hbase",90
查看数据
count "hbase_test:student_info" # 计算hbase_test命名空间下student_info表中行的数量 get "hbase_test:student_info","1" # 查看行键为1的数据 get "hbase_test:student_info","1","base" get "hbase_test:student_info","1","base:name" scan "hbase_test:student_info" # 查看所有数据 # 返回键而不返回值,返回行键以1为前缀的行 scan "hbase_test:student_info",{VERSIONS => 1, FILTER => "KeyOnlyFilter(true)", ROWPREFIXFILTER => '1'}删除数据
delete "hbase_test:student_info","1","base:name" # 删除单元格最近版本数据 deleteall "hbase_test:student_info","1","base:age" # 删除字段 deleteall "hbase_test:student_info","1" # 删除行键为1的所有值 truncate "hbase_test:student_info" # 删除所有数据
计数器列相关的操作
incr "hbase_test:student_info","1","base:num",1 # 增加一个计数器列的值1 get_counter "hbase_test:student_info","1","base:num" # 得到值 1
四、Tools(工具)
待整理
管理表存储文件,对于优化HBase的性能和恢复存储空间非常重要
major_compact "[NAMESPACE:]TABLE" # 触发表的主要压缩 compact "[NAMESPACE:]TABLE" # 触发表的普通压缩
使用 HBase 的 ImportTsv 工具从一个 TSV(Tab-separated values,制表符分隔值)文件导入数据到 HBase 表中
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv \ -Dimporttsv.separator="," \ -Dimporttsv.columns=HBASE_ROW_KEY,info1:name,info1:age,info2:java,info2:mysql \ hbase_test:for_phoenix_test \ file:///root/hbase/students_for_import_2.csv
- hbase org.apache.hadoop.hbase.mapreduce.ImportTsv:这是调用 HBase 的 ImportTsv 工具的命令。
- -Dimporttsv.separator=",":设置字段分隔符为竖线(,)。
- -Dimporttsv.columns=HBASE_ROW_KEY,info1:name,info1:age,info2:java,info2:mysql:定义 HBase 表的列族和列。HBASE_ROW_KEY 是特殊的标识符,用于指定行键。其他的列使用 列族:列名 的格式指定。
- hbase_test:for_phoenix_test:指定 HBase 表的名字。
- file:///root/hbase/students_for_import_2.csv:指定要导入的文件的路径。
预分区
#查看分区 scan 'hbase:meta',{STARTROW=>'hbase_test:for_mysql_import',LIMIT=>10} #默认分区策略 IncreasingToUpperBoundRegionSplitPolicy #预分区 create 'test:pre_par_test','cf1','cf2',{NUMREGIONS=>4 , SPLITALGO=>'UniformSplit' } create 'test_split_table','base','scores',SPLITS=>['100','200','300'] # hdfs 存储信息 #Permission Owner Group Size Last Modified Rep Block Size Name #drwxr-xr-x root supergroup 0 B Feb 20 17:37 0 0 B .tabledesc #drwxr-xr-x root supergroup 0 B Feb 20 17:37 0 0 B .tmp #drwxr-xr-x root supergroup 0 B Feb 20 17:37 0 0 B 59cfcaf86548e4cad1... #drwxr-xr-x root supergroup 0 B Feb 20 17:37 0 0 B 5ea0b24bec6c73d227... #drwxr-xr-x root supergroup 0 B Feb 20 17:37 0 0 B 9256e995584fd306ea... #drwxr-xr-x root supergroup 0 B Feb 20 17:37 0 0 B ea4524c282c3876175...HIVE 表映射
create external table for_hbase_mapping( row_key int, base_age int, base_gender string, base_name string, base_phone string, score_hadoop int, score_java int, score_spark int ) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties("hbase.columns.mapping"=":key,base:test_age,base:test_gender,base:test_name,base:test_phone,scores:hadoop,scores:java,scores:spark") tblproperties("hbase.table.name"="hbase_test:for_mysql_import");五、Replication
未完待续…






