目录
1.前言
2.设计思路
2.1课题背景与意义
2.2算法理论原理
2.2.1 YOLOv5算法
2.2.2 跨领域网格匹配策略
2.3检测的实现
2.3.1 数据集
2.3.2 实验环境搭建
2.3.3 实验及结果分析
3.实现效果图样例
4.最后
1.前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
最新最全计算机专业毕设选题精选推荐汇总

2. 设计思路
2.1 课题背景与意义
随着电动车的不断普及,电动车交通安全事件也不断增加,而当人们使用头盔时,可以有效降低事故发生受到的危险提出了一种基于YOLOv5改进的卷积神经网络模型的电动车头盔佩戴检测识别系统。
2.2 算法理论原理
2.2.1 YOLOv5算法
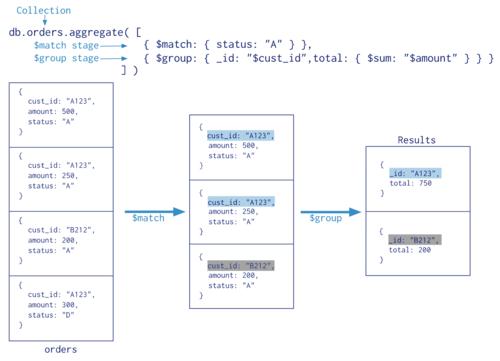
YOLOv5s是YOLOv5系列最小的网络,改进算法网络结构图如下所示。YOLOv5s是在数据输入部分对数据集做Mosaic-9数据增强方式、图片尺寸处理。通过设定初始锚框自动计算最佳锚框值,将输入图片尺寸变化成固定大小,网络模型将基于此锚框进行训练,并与真实框对比,根据它们之间的差值反向迭代,然后送入检测模型进行训练以提高实际检测时的推理速度。
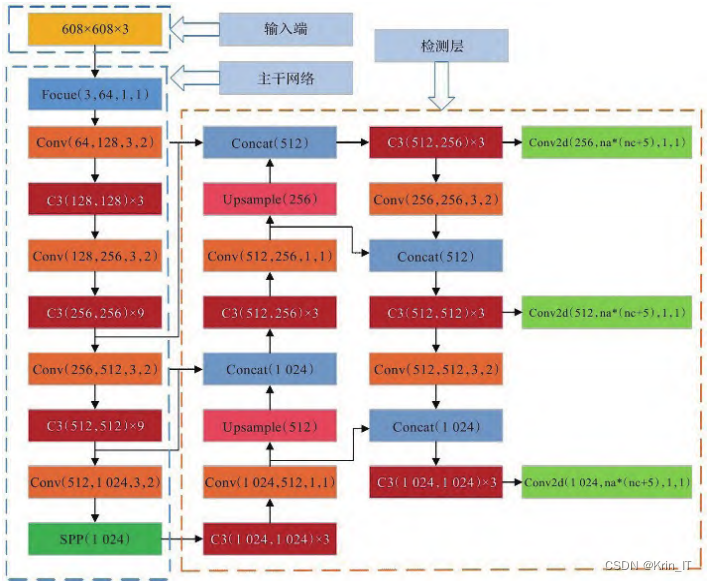
经过Focus进行切片和卷积操作处理,为特征提取保留完整的图片信息,然后利用空间金字塔池化SPP融合多尺度信息实现特征增强,在Neck部分保留空间信息。目标框与检测框的重叠部分与中心距离选用CIoU损失函数以提高定位精度,引入了惩罚项以缓解了IOU两个框不相交的问题,更准确地反映预测框与真实框的相交情况,并且在训练时采用动态调整策略。
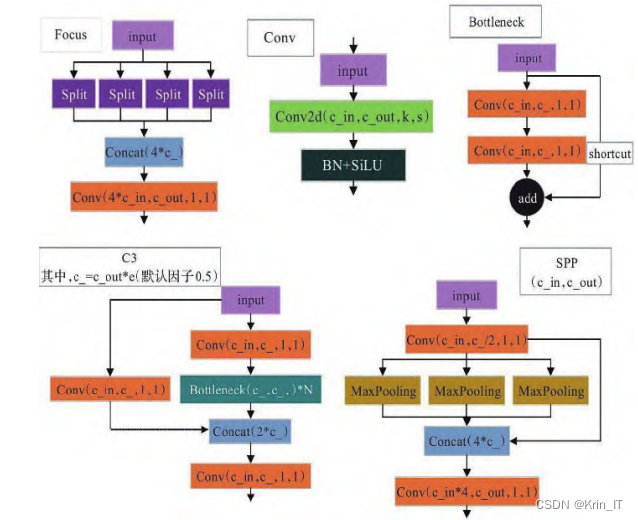
2.2.2 跨领域网格匹配策略
跨领域网格匹配策略是一种在目标检测任务中应用的技术,旨在提高模型的准确性和鲁棒性。该策略的核心思想是将目标检测网络的特征图分成多个不同尺度的网格,并将每个目标与最匹配的网格进行关联。跨领域网格匹配策略通过将特征图分割为多个尺度的网格,并将目标与最匹配的网格进行关联,可以提高目标检测的准确性、鲁棒性和上下文感知能力,同时减少误检率。这一策略在目标检测领域具有广泛的应用前景和潜力。
相关代码:
def match_grid_strategy(targets, anchors, grid_size):
# 初始化匹配结果列表
match_results = []
# 遍历目标列表
for target in targets:
# 计算目标的宽度和高度
target_width = target.width
target_height = target.height
# 初始化最佳匹配的anchor和最佳匹配的IoU
best_anchor = None
best_iou = 0
# 遍历所有的anchors
for anchor in anchors:
# 计算anchor的宽度和高度
anchor_width = anchor.width
anchor_height = anchor.height
# 计算anchor和目标的IoU
intersection = min(target_width, anchor_width) * min(target_height, anchor_height)
union = target_width * target_height + anchor_width * anchor_height - intersection
iou = intersection / union
# 更新最佳匹配的anchor和最佳匹配的IoU
if iou > best_iou:
best_anchor = anchor
best_iou = iou
# 将最佳匹配的anchor添加到匹配结果列表中
match_results.append(best_anchor)
# 根据网格大小调整anchor的位置
adjusted_anchors = adjust_anchors(match_results, grid_size)
return adjusted_anchors
def adjust_anchors(anchors, grid_size):
# 初始化调整后的anchor列表
adjusted_anchors = []
# 遍历所有的anchors
for anchor in anchors:
# 计算调整后的anchor的中心坐标
adjusted_center_x = (anchor.center_x - anchor.grid_x) * grid_size
adjusted_center_y = (anchor.center_y - anchor.grid_y) * grid_size
# 创建调整后的anchor对象
adjusted_anchor = Anchor(adjusted_center_x, adjusted_center_y, anchor.width, anchor.height)
# 将调整后的anchor添加到列表中
adjusted_anchors.append(adjusted_anchor)
return adjusted_anchors
2.3 检测的实现
2.3.1 数据集
数据集来自学长实际拍照和互联网搜索等自主收集方式,所收集到的数据包括不同环境、不同分辨率的图片,并逐一采用LableImg软件进行标注,标注类别分别为bicycle、electric vehicle、helmet、head四类。本文实验数据集为5000张,较全面的概括各类场景的图像。

通过改进数据增强方式,采用了Mosaic-9,将图片数量由原来的4张扩至9张进行拼接。数据集来自实际拍照和python网络爬虫等自主收集方式,所收集到的数据包括不同环境、不同分辨率的图片,并逐一采用LableImg软件进行标注,标注类别分别为bicycle、electric vehicle、helmet、head四类。

随机透视变换中的旋转缩放、平移、错切 / 非垂直投影、透视变换均采用单独的一种数据增强方法,通过构造变换矩阵让数据随着变换矩阵而变化。

2.3.2 实验环境搭建
通过对骑行人员佩戴头盔情况进行智能识别,并部署于嵌入式平台Jetson nano上,实时识别出骑行人员未佩戴头盔的行为,达到高效率监督监管。
2.3.3 实验及结果分析
在YOLOv5的环境下,mAP为91.2%,相对于YOLOv4有了很大提升。在YOLOv5的基础上进行目标框回归与跨网格匹配策略和Mosaic-9的数据增强的改进,改进后的mAP高达96.8%,如图6所示。
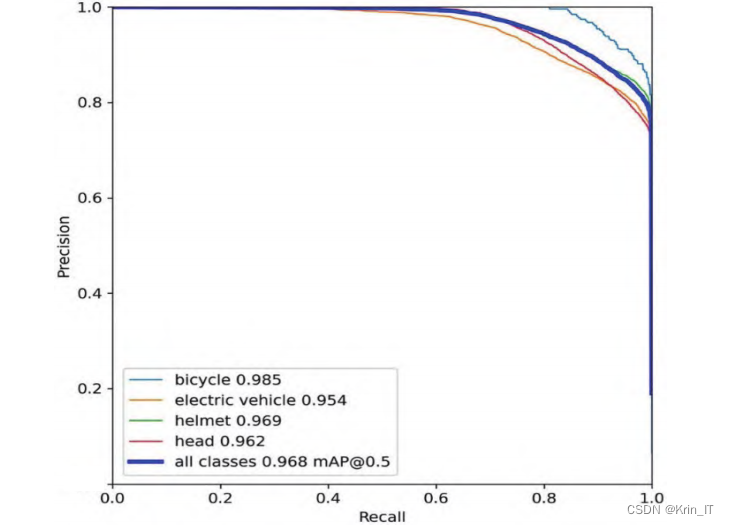
不同检测算法性能指标对比:

相关代码如下:
import torch
import torchvision.transforms as transforms
from torchvision.models.detection import fasterrcnn_resnet50_fpn
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from PIL import Image
# 加载预训练模型
model = fasterrcnn_resnet50_fpn(pretrained=True)
# 替换模型的分类器
num_classes = 2 # 包括“带头盔”和“未带头盔”两个类别
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
# 加载模型权重
model.load_state_dict(torch.load('path_to_model_weights.pth'))
model.eval()
# 设置转换器
transform = transforms.Compose([transforms.ToTensor()])
# 加载并预处理图像
image = Image.open('path_to_image.jpg').convert('RGB')
image_tensor = transform(image)
# 添加批次维度
image_tensor = image_tensor.unsqueeze(0)
# 模型推理
with torch.no_grad():
predictions = model(image_tensor)
# 解析预测结果
scores = predictions[0]['scores']
labels = predictions[0]['labels']
boxes = predictions[0]['boxes']
# 阈值过滤和绘制边界框
threshold = 0.5 # 置信度阈值
for score, label, box in zip(scores, labels, boxes):
if score > threshold and label == 1: # 检测到未带头盔的骑电动车行人
x_min, y_min, x_max, y_max = box
print("未带头盔的骑电动车行人坐标:", (x_min.item(), y_min.item(), x_max.item(), y_max.item()))
# 显示图像
image.show()
3. 实现效果图样例
创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!