Qualcomm® AI Engine Direct 使用手册(1)
- 1. 介绍
- 1.1 目的
- 1.2 惯例
- 1.3 平台差异
- 1.4 发行说明
- 2 概述
- 2.1 特征
- 2.2 软件架构
- 2.3 集成工作流程
- 2.4 Linux 上的开发人员
- 2.5 Windows 上的集成工作流程
- 2.6 Windows 上的开发人员
1. 介绍
1.1 目的
本文档提供 Qualcomm® AI Engine Direct 软件开发套件 (SDK) 的参考指南。
笔记
Qualcomm® AI Engine Direct 在源代码和文档中也称为 Qualcomm 神经网络 (QNN)。
1.2 惯例
函数声明、函数名称、类型声明、文件名、目录名称和库 名称以不同的字体显示。例如:#include
命令和代码示例出现在特殊格式的代码部分中。例如:
output = (input - offset) * scale.
数学表达式出现在特殊格式的数学部分中。例如:
y = x + 1环境变量前面带有 $,例如 $QNN_SDK_ROOT。
1.3 平台差异
Qualcomm® AI Engine Direct 支持 Windows 和 Linux 平台。之间有几个区别 Linux 和 Windows 系统:
库和可执行程序命名约定
在 Linux 上,共享库名称将以 lib 为前缀,并具有 .so 扩展名。 在 Windows 上,共享库没有前缀,并且具有 .dll 扩展名。
在 Linux 上,库名称具有 .a 扩展名。在 Windows 上,静态使用 .lib 扩展名。 Windows 上的可执行文件具有 .exe 扩展名,而 Linux 可执行文件则没有。
例如,QnnCpu 后端库在 Linux 上为 libQnnCpu.so,在 Windows 上为 QnnCpu.dll。
不同平台的发布文件夹
Qualcomm® AI Engine Direct 软件开发套件 (SDK) 的用户可以通过以下方式找到相应的二进制文件和可执行文件 相关文件夹。例如,对于Linux和Windows平台,用户可以在表明平台的SDK根目录下找到具体路径:
-
(对于 Linux-X86):/bin/x86_64-linux-clang。
-
(对于 Windows-X86):/bin/x86_64-windows-msvc。
-
(对于 Windows-aarch64):/bin/aarch64-windows-msvc。
Linux 和 Windows 的环境设置
模型工具的操作应以平台依赖项的环境设置为先决条件。请参阅设置 了解更多信息。
1.4 发行说明
发行说明在 SDK 中以 QNN_ReleaseNotes.txt 形式提供。
2 概述
Qualcomm® AI Engine Direct 是 Qualcomm Technologies Inc. (QTI) 用于 AI/ML 用例的软件架构 关于 QTI 芯片组和 AI 加速核心。
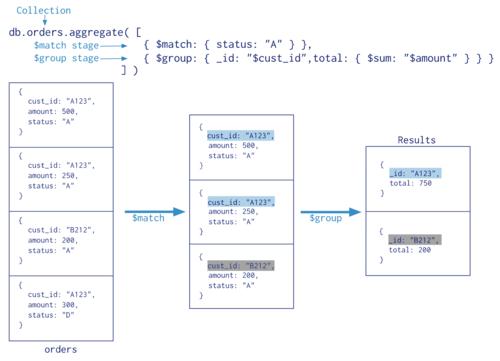
Qualcomm®AI Engine Direct架构旨在提供统一的 API 以及模块化和可扩展性 每个***库构成了全栈人工智能解决方案的可重用基础, QTI 自有框架和第三方框架(如采用 Qualcomm AI Engine Direct 的 AI 软件堆栈图所示)。
采用 Qualcomm AI Engine Direct 的 AI 软件堆栈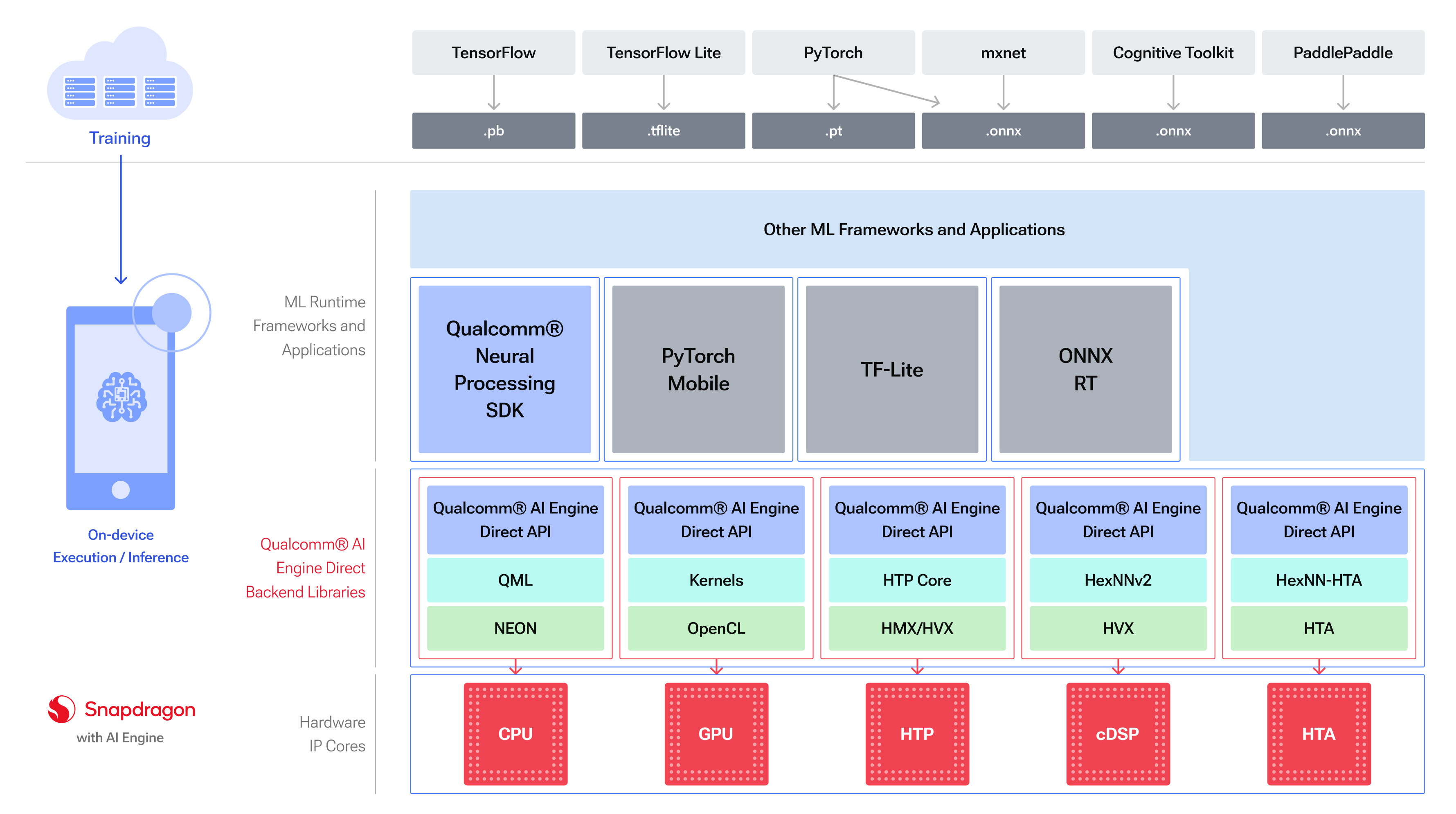
2.1 特征
基于硬件***的模块化
Qualcomm® AI Engine Direct 架构采用模块化设计,可实现软件中的清晰分离 对于不同的硬件核心/***,例如 CPU、GPU 和 DSP,指定为 后端。了解有关 Qualcomm® 的更多信息AI Engine Direct后端此处。
针对不同硬件核心/***的 Qualcomm® AI Engine Direct 后端被编译为 与 SDK 一起打包的各个特定于核心的库。
跨 IP 核的统一 API
Qualcomm® 的主要亮点之一AI Engine Direct 是它提供了统一的 API 来委托操作 例如跨所有硬件***后端的图形创建和执行。这允许用户 将 Qualcomm® AI Engine Direct 视为硬件抽象 API,并将应用程序轻松移植到不同的内核。
正确的抽象级别
Qualcomm® AI Engine Direct API 旨在支持高效的执行模型 具有内部处理的图形优化等功能。 但与此同时,它遗漏了更广泛的功能,例如模型解析和 网络分区到更高级别的框架。
组合的灵活性
借助 Qualcomm® AI Engine Direct,用户可以在后端提供的功能之间进行适当的权衡 以及库大小和内存利用率方面的占用空间。这提供了以下能力: 构建 Qualcomm® AI Engine Direct 操作包,仅包含服务一组模型所需的操作 以用例为目标1。有了这个,用户可以创建灵活的应用程序 内存占用低,适合各种硬件产品。
可扩展的运营支持
Qualcomm® AI Engine Direct 还为客户集成自定义操作以无缝协作提供支持 内置操作。
提高执行性能
凭借优化的网络加载和异步执行支持 Qualcomm®AI Engine Direct 可提供高度 机器学习框架和应用程序加载和执行网络图的高效接口 他们想要的硬件***。
2.2 软件架构
Qualcomm® AI Engine Direct API 和相关软件堆栈提供应用程序所需的所有构造 在所需的硬件***核心上构建、优化和执行网络模型。 Qualcomm AI Engine 直接组件 - 高级视图图表说明了主要构造。
Qualcomm AI Engine 直接组件 - 高级视图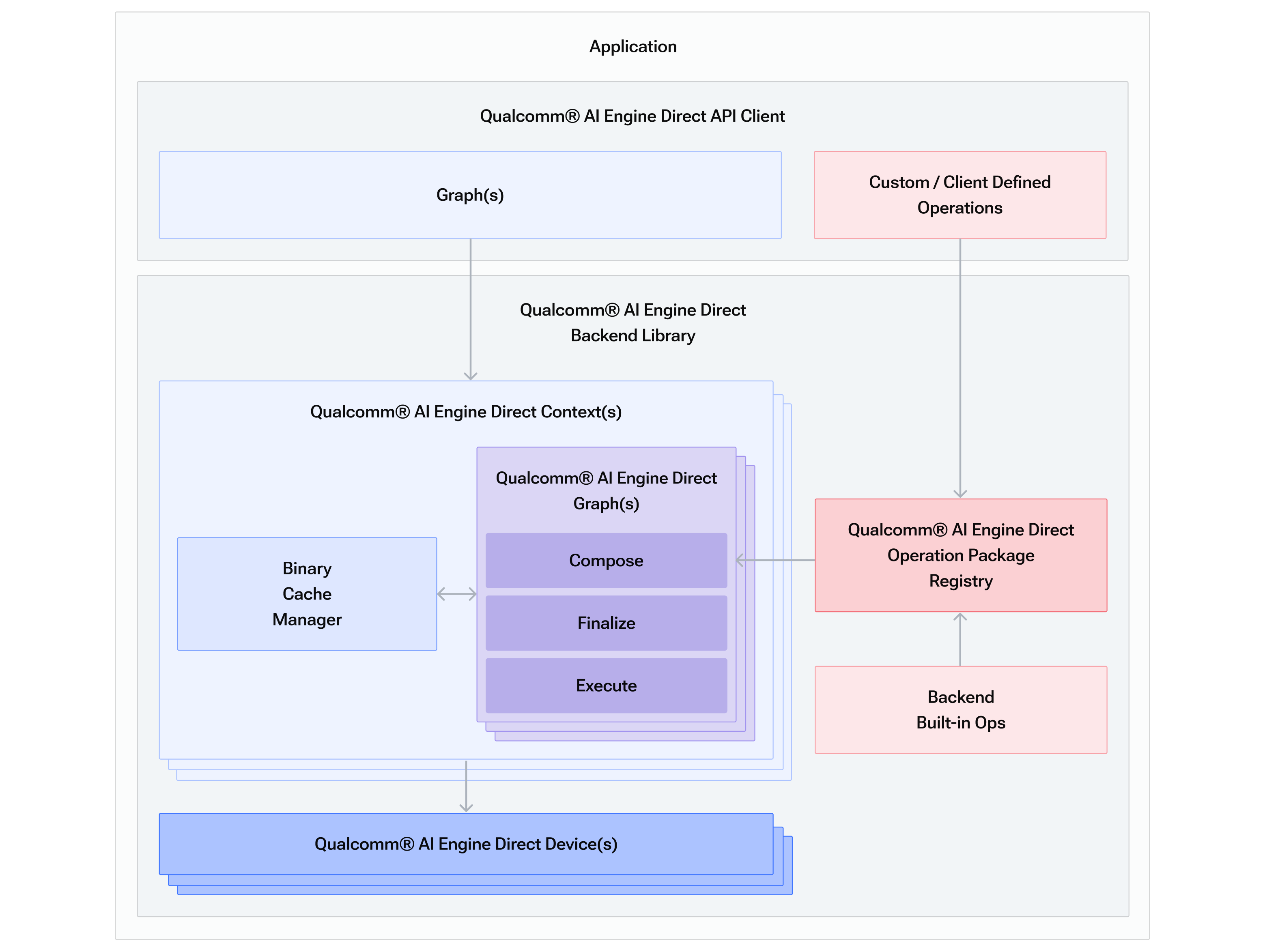
设备
硬件***平台的软件抽象。提供关联所需硬件所需的所有构造 用于执行用户组成的图的***资源。一个平台可能被分解为多个 设备。设备可能有多个核心。
后端
后端是顶级 API 组件,托管和管理图形所需的大部分后端资源 组合和执行,包括存储所有可用操作的操作注册表。 了解有关 Qualcomm® 的更多信息AI Engine Direct后端此处。
语境
代表维持用户应用程序所需的所有 Qualcomm® AI Engine Direct 组件的构造。主机网络由 用户并允许将构造的实体缓存到序列化对象中以供将来使用。它实现了互操作性 通过提供可共享的内存空间来在多个图之间实现张量在图之间交换。
图形
Qualcomm® AI Engine Direct 表示可加载网络模型的方式。由代表的节点组成 将它们互连以组成有向无环图的运算和张量。 Qualcomm® AI Engine Direct 图结构支持执行初始化、优化和执行的 API 网络模型。
操作包注册表
一个注册表,用于维护可用于执行模型的所有操作的记录。 这些操作可以是内置的,也可以由用户作为自定义操作提供。 了解有关操作包的更多信息此处。
2.3 集成工作流程
Qualcomm® AI Engine Direct SDK 提供工具和可扩展的每个***库,支持统一的 API 在 QTI 芯片组上灵活集成和高效执行 ML/DL 神经网络。 Qualcomm® AI Engine Direct API 旨在支持经过训练的神经网络的推理,因此客户负责 在他们选择的训练框架中训练 ML/DL 网络。训练过程一般是 在服务器主机上、设备外完成。一旦网络经过培训,客户就可以使用 Qualcomm® AI Engine Direct 做好准备 在设备上部署并运行。该工作流程用以下图解说明 训练与推理工作流程图表。
训练与推理工作流程
Qualcomm® AI Engine Direct SDK 包含的工具可帮助客户将经过训练的深度学习网络集成到他们的 应用程序。基本集成工作流程如下图所示 Qualcomm AI Engine 直接集成工作流程图表。
Qualcomm AI Engine直接集成工作流程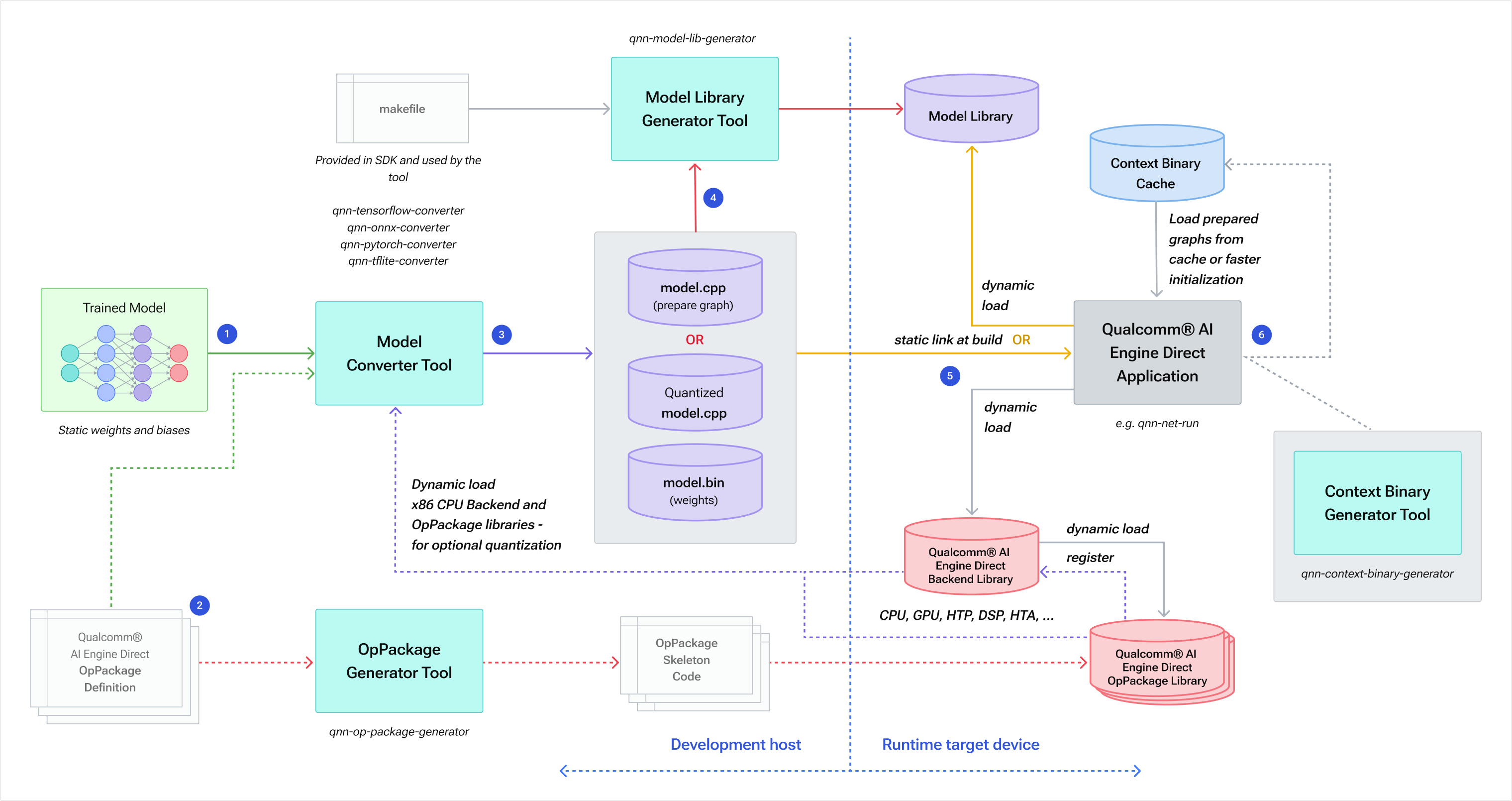
-
客户通过提供经过训练的网络模型文件作为输入来调用 Qualcomm® AI Engine Direct 转换器工具。 网络必须在 Qualcomm® AI Engine Direct 转换器工具支持的框架中进行训练。 有关 Qualcomm® AI Engine Direct 转换器的更多详细信息,请参阅工具部分。
-
当源模型包含 Qualcomm® 本身不支持的操作AI Engine Direct后端时, 客户端需要向转换器提供OpPackage定义文件,表达自定义/客户端 定义的操作。或者,他们可以使用 OpPackage 生成器工具来生成 框架代码来实现并将其自定义操作编译到 OpPackage 库中。 请参阅 qnn-op-package-generator 了解使用详情。
-
Qualcomm® AI Engine Direct模型转换器是一款帮助客户编写 Qualcomm® 序列的工具AI引擎直接 API 调用以构建 Qualcomm® AI Engine Direct 训练网络的图形表示形式,该网络作为工具的输入提供。 转换器输出以下文件:
-
.cpp 源文件(例如model.cpp),包含构建所需的 Qualcomm® AI Engine Direct API 调用 网络图
-
.bin 二进制文件(例如 model.bin),包含作为 float32 数据的网络权重和偏差
客户端可以选择指示转换器输出量化模型而不是默认模型, 如图所示量化模型.cpp。在这种情况下 model.bin 文件将 包含量化数据,并且 model.cpp 将引用量化张量数据类型和 包括量化编码。某些 Qualcomm® AI Engine Direct 后端库可能需要量化模型, 例如HTP 或 DSP(请参阅 general/api:后端补充 了解有关受支持的信息 数据类型)。有关转换器量化功能和选项的详细信息,请参见 量化支持。
-
客户可以选择使用 Qualcomm® AI Engine Direct 模型库生成工具来生成模型库。 请参阅qnn-model-lib-generator了解使用详情。
-
客户通过动态加载模型库将 Qualcomm® AI Engine Direct 模型集成到其应用程序中 或编译并静态链接model.cpp 和model.bin。 为了准备和执行模型(即运行推理),客户端还需要加载所需的 Qualcomm® AI Engine Direct 后端***和 OpPackage 库。 Qualcomm® AI Engine Direct OpPackage 库已注册并 由后端加载。
-
客户端可以选择保存上下文二进制缓存以及准备好的和最终确定的图表。看 上下文缓存供参考。 这样的图可以从缓存中重复加载,而不需要模型.cpp/库 任何进一步。从缓存加载模型图比通过准备加载模型图要快得多 模型 .cpp/库中提供的一系列图形组合 API 调用。缓存的图表不能 进一步修改;它们旨在部署准备好的图表,从而实现更快的 客户端应用程序的初始化。
-
客户可以选择使用Qualcomm 神经处理 SDK 生成的深度学习容器 (DLC) 与提供的 libQnnModelDlc.so 库结合使用,从应用程序中的 DLC 路径生成 QNN 图形句柄。这提供了单一格式 用于跨产品使用并支持无法编译到共享模型库的大型模型。使用详情 可以在利用 DLC 中找到。
-
2.4 Linux 上的开发人员
可执行文件和库可以在 SDK 的目标文件夹下找到,名称中包含“linux”、“ubuntu”或“android”。 请参阅不同平台的发布文件夹以供参考。 上述操作可以在Ubuntu系统等Linux操作系统下运行。
2.5 Windows 上的集成工作流程
2.6 Windows 上的开发人员
Qualcomm SDK 为 Windows 主机提供了三种不同的平台。对于熟悉Linux操作的用户来说, 我们建议在 Windows 上使用 WSL(适用于 Linux 的 Windows 子系统)。对于想要直接通过powershell环境在Windows-PC上使用工具的开发者来说, Qualcomm®AI Engine Direct提供基于x86_64-windows的工具。请检查以下先决条件。
WSL平台
对于 WSL 开发人员: Windows 主机上的工作流程与 Linux 主机上的工作流程相同,但某些步骤需要在 WSL (x86) 上执行 其他的将在 Windows 上本地执行,如下所述。由于 WSL 运行在 GNU/Linux 环境上,因此模型工具 和库应该分别从 x86_64-linux-clang 获取。 要了解有关 WSL 设置的更多信息,请访问 Linux 平台依赖项。
Windows 本机平台
对于 Windows 本机 PC 开发人员: 这些工具和库位于“x86_64-windows-msvc”文件夹中。工具与Python版本和设置密切相关。所以, 运行前需要设置好原生powershell的环境。请参考Windows下的设置 Windows 平台依赖项
-
对于 OP 定制,op 包骨架代码是通过在 WSL (x86) 上运行 Linux OpPackage Generator Tool 生成的。
-
对于上下文二进制生成,客户端可以使用 WSL (x86) 上的 Linux 上下文二进制生成器工具 或 Windows 原生 powershell。使用的工具可执行文件和库需要来自相应的文件夹,如针对不同平台的发布文件夹中所述。
-
对于模型库生成,模型库是通过在 Windows 上本机运行 Windows 模型库生成器工具来生成的。
-
“集成工作流程”中提到的工具可以通过 WSL 或 Windows 本机 x86 应用。 工具中展示了按平台划分的工具支持列表。
-
SC8380XP 上的 CPU 和 HTP 后端支持 ARM64X 封装格式。这些工具和库位于“arm64x-windows-msvc”文件夹中。 有关使用方法和详细信息,请参阅ARM64X教程。
笔记
使用 WSL 时,必须从 linux 文件夹获取模型工具,因为它是 Linux 的子系统。
笔记
当在 Windows 上本地运行时,模型库生成工具必须使用 python 运行。 有关示例,请参阅Windows 主机上的模型构建部分。
-
-