目录
前言
(一)“信息”的定位
小结
(二)人工智能
(1)概念
(2)诞生
(3)人工智能的目的
(三)实现人工智能的两种方法:
(四)发展铺垫
(1)马尔可夫假设:
(2)Transformer 模型
(五)词语向量化
(1)为什么要将词语向量化?
(2)我们想要达到什么效果呢?
(六)信息压缩与特征提取
(七)Attention Is All You Need训练模型核心概述
(1)Input Embedding 词嵌入
(2)Positional Encoding 位置编码
(3) 多头自注意力机制的编码器
(4)Masked 多头自注意力
(5)Softmax 概率转化
(八)总结
(九)ChatGPT能取代人类吗?
前言
前不久,在学习C语言的我写了一段三子棋的代码,但是与我对抗的电脑是没有任何思考的,你看了这段代码就理解为什么了:
void computerMove(char Board[ROW][COL], int row, int col)
{
while (1)
{
unsigned int i = rand() % ROW, j = rand() % COL;
if (Board[i][j] == ' ')
{
Board[i][j] = '#';
break;
}
}
}
电脑的走的棋子是随机产生的,于是我想赋予电脑一定的智能,给它写一些思考函数,但是,一种一种的if嵌套if的逻辑代码写下来不仅极易出错,而且后续想要Debug也十分困难。
我们知道人工智能是可以下棋的,但是人工智能自主学习的源码是怎么实现的呢?
于是,我想起了Chatgpt,虽然Chatgpt并非是严格通过代码来实现的,但是它的原理确实很有趣。
(一)“信息”的定位
人工智能的运作离不开信息;
信息这个词语,我们耳熟能详,但是信息到底在时间和空间上有什么地位呢?换句话说:它的位置是什么?
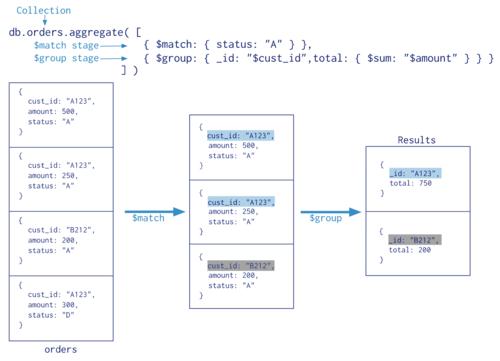
如图:
在物质上,从地球出发,地球是最大的生态系统,生态系统的三个功能是:
能量流动,物质循环,信息传递;
在生态系统中,三大功能密不可分,相互作用和相互依存。
这幅图我们暂且搁置,作为铺垫。
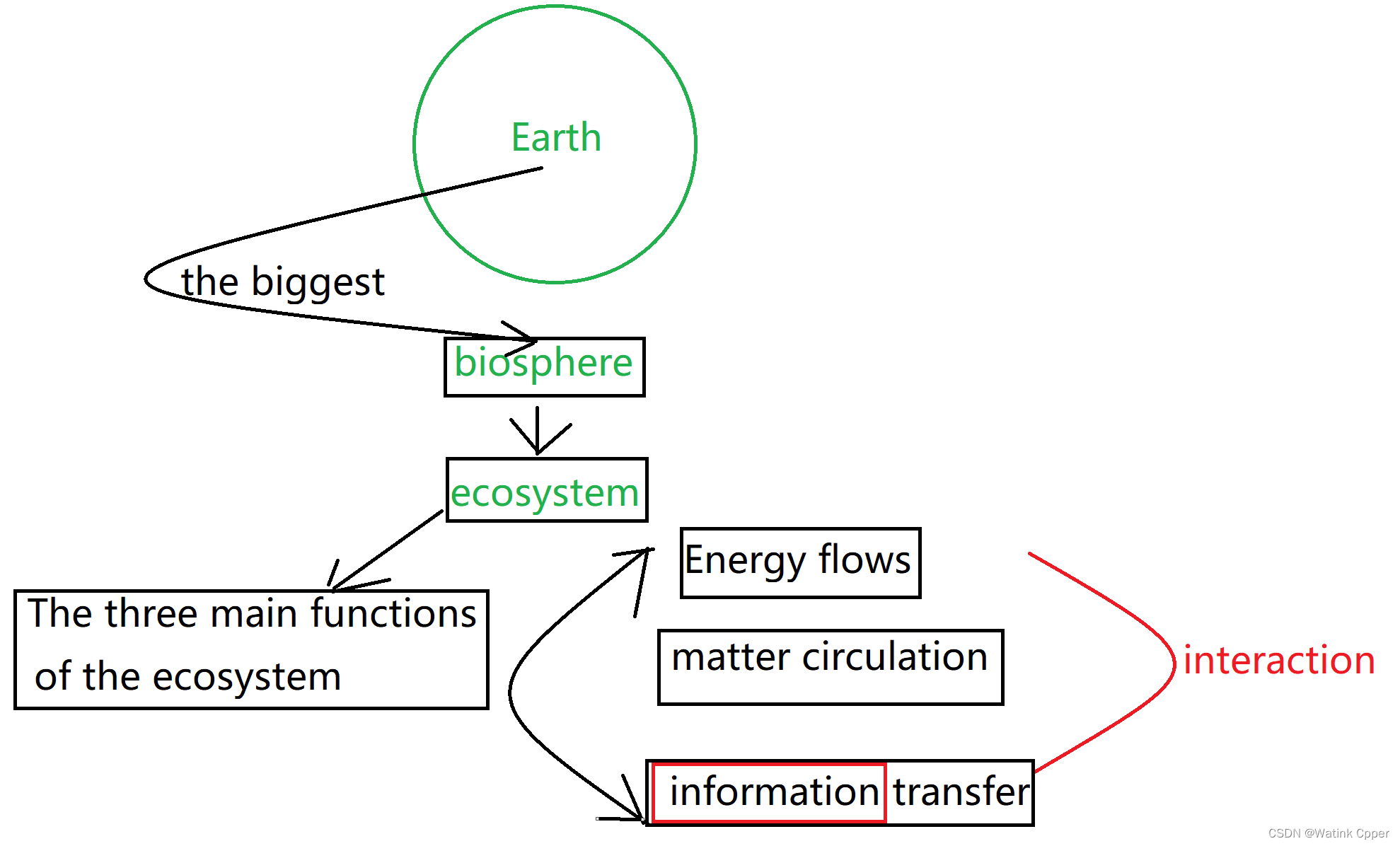
纵观人类的历史的发展历程, 我们经历了这几个历史时期:
每一个时期都是一个阶段,每一个阶段都是一次跨越,是量变以后的质变。
每一个时期由于相对于上一个时期,新时期的技术往往更加有优势,新时期的技术往往会淘汰旧时期的技术,所以人类历史是向前发展的。
小结
在生态系统中,信息是动态的,它不断流动,传递,从而发挥作用;
直到人类通信技术及计算机技术的飞速发展和广泛应用。标志着人类进入了信息化时代,直到这时,我们才真正注意起信息的作用。
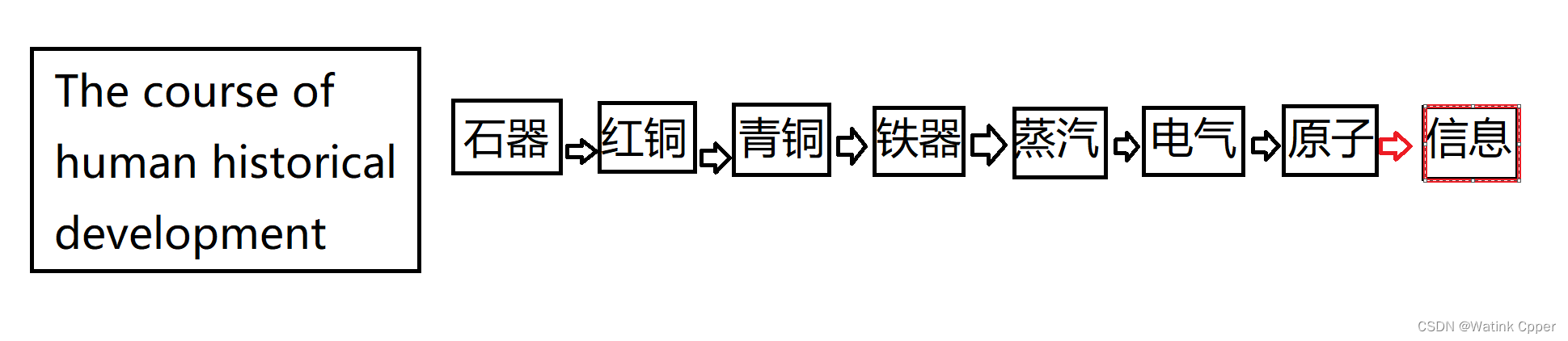
从信息的定位来看:
1.信息的地位是很重要的
2.计算机的出现使得几乎所有信息都可以用数据表现,信息可被计算机表现,意味着可被计算,计算机可 表示信息,搜索信息,甚至通过信息,预测将要出现的新的信息。
预测信息可以做什么?
可以做天气预报,可以预测股价,甚至可以在一定程度上通过特定的语言模型实现人工智能!
(二)人工智能
(1)概念
人工智能,是指通过计算机技术模拟人类智能的理论、方法、技术和应用系统。AI能够让机器像人类一样思考、理解、判断、学习、推理、规划、决策等,从而能够完成各种智能任务。
(2)诞生
1956年夏季,以麦卡赛、明斯基、罗切斯特和申农等为首的一批有远见卓识的年轻科学家在一起聚会,共同研究和探讨用机器模拟智能的一系列有关问题,并首次提出了“人工智能”这一术语,它标志着“人工智能”这门新兴学科的正式诞生。
(3)人工智能的目的
人工智能的目的是模拟人类智能的各种能力和特征。人工智能的最终目标是使计算机能够像人类一样思考、学习、理解和解决问题。通过模拟人类智能的过程,人工智能可以执行各种任务,如语音识别、图像识别、自然语言处理、决策制定等。人工智能的目的是为了提高计算机系统的智能和自主决策能力,使其能够更好地与人类进行交互并实现更高效的任务执行。
(三)实现人工智能的两种方法:
(1)工程学方法:
即不考虑所用方法是否与人等智慧体所用的方法相同,只要能达到相应的效果就行。
(2)模拟法:
即不仅要看效果,还要求实现方法与人等智慧体所用方法一致。
现在请停下来想一想,深入理解:
我们解一个一元二次方程,用到求根公式,但是计算机不知道有求根公式这个东西,它解这个方程,用的是穷举法,将自变量的值一个一个代入尝试,最后输出最接近真实值的根。
当然我们也可编写一个程序,与机器交流,告诉它有个求根公式,并且它可以使用。
但是,这并不代表按照我们设定好的程序运行的机器有了智能;可以说这只是算法的优化,但是机器距离真正的智能还有很大的差距。
如果我为电脑编写一套程序,告诉它,if(判断){实现}(当然这样对编写程序的我来说十分痛苦)。这同样可以达到让计算机实现智能的目的,这是也许实现人工智能的一种方法,但是电脑并没有真正的 ”思考“,因为他只是按照代码指令一步步执行而已。
同时这样(制定一套规则来让计算机照着执行)是有很大缺陷的:
1.人工编程繁琐,工作量大
2.人工编写易出错
3.一旦出错,需要 调试 ,修改源码 ,编译,运行 ,最终人工提供新的版本
相反:
如果为电脑编写一种方法,让他从下三子棋的对局中汲取教训,不断学习,最终达到依靠自己的数据库来达到自我决策的目的,这可能也是实现人工智能的一种方法。
也就是说,我只要实现一个智能系统,虽然刚开始它什么也不懂,就像婴儿一样,但是他可以学习,它能够渐渐适应环境,以应对各种复杂情况。
(四)发展铺垫
首先,引入一种假设:
(1)马尔可夫假设:
一个词语出现的概率,只和前面的词语有关,而与更早的词语或者往后的词语无关。
一句话中,后面将要出现的词语假设与前(n-1)个词语有关(这就是也就是所谓的N-gram模型)。
但是n需要有一个范围,需要满足:
该出现高频的词语,在样本中出现高的频率;该出现低频的词语,在样本中出现低的频率。
但是n的值是不易确定的:
如果n值过大,那么需要记录的概率分布将呈指数级增长,于是n不能无限大,即不能有很长的上下文;同时,n过大,那么这个词语就很可能依靠很久以前的上下文,那么这个模型就显得很低效了。
如果n值太小,那么结果的准确性很难保证。
这也就是N-gram模型的弊端,尽管RNN(循环神经网络)解决了N-gram的部分问题,但是RNN仍带来了新的问题——梯度削减
因为有激活函数的存在,在反向传播的时候,原来的占小部分的变量的变化被忽略,因为较小的部分对值的变化不敏感。
(2)Transformer 模型
直到后来,一个新的模型被Goggle提出《Attention Is All You Need》——GPT模型
(论文链接放在文章末尾)

(五)词语向量化
(1)为什么要将词语向量化?
计算机的底层是二进制,现实世界的信息若交给计算机处理,那么都会被转化为数字。
一个富有语义的词语在计算机内部仅仅是一串0,1组成的数字串,计算机怎么理解它们呢?
我们是一个智慧体,可以将判断,处理信息;早期的计算机只是一个储物柜,他来帮我们储存信
息,就像我们在冰箱存储食物一样。冰箱不认得食物的种类,它的任务仅仅是储存,重要的是我们
认识食物的种类就行了。如何让冰箱认得食物的种类呢?
词语向量化就是解决这一问题的方法。
词语向量化可以使得词汇之间的语义关系,在向量空间中得以体现,而向量是可以计算的这就为计算机理解词汇奠定基础。
(2)我们想要达到什么效果呢?
想象一下:
i,king向量减去man向量加上woman向量正好是queen向量;
ii,king和queen象征着王权,man和woman象征着性别,这样一来,我们大致可以认为王权在一个轴分量较多,性别在另一个轴分量较多;
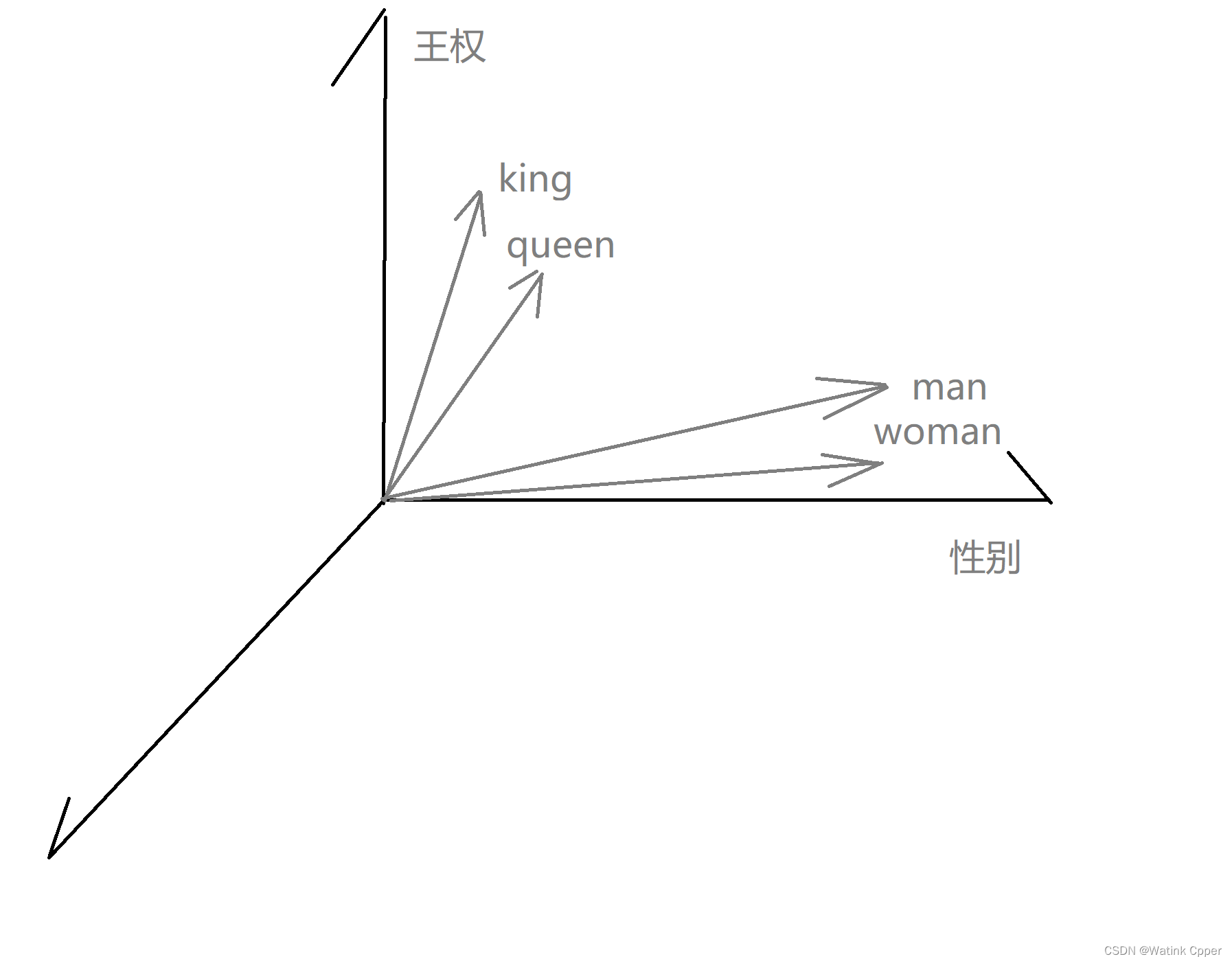
上述两个例子,都是让词汇向量化的例子。
在一个合适的向量空间中,词语之间的空间关系反映了 它们现实之间的实际关系。
如何达到这样的效果呢?
向量是可以计算的,也就是正确结果与结果之间的差距可以计算,这两者的差距可以用函数关系表示,这个函数就是损失函数,而一旦转化为函数,那么训练的过程就是可计算的数学方法了,也就是损失函数要收敛。
(六)信息压缩与特征提取
我们人类,可以通过大脑的注意力机制,忘记一些无关紧要的信息,保留一些重要的信息,我们可以通过对问题中的主要信息的处理来回答问题。
但是计算机并没有大脑的这一功能,于是,我们想要找到提取语言特征的方法。
但是在一般的模型如N-gram和RNN模型都有一定的局限性,比如:
小明看了博主的文章,他很喜欢,伸手就给了博主一个______:
A:三连 B:大嘴巴子
显然,我们作为智慧体,有大脑的重要信息提取的加持,很容易得到推断结果——三连;
(在这一过程中,我们的大脑通过提取 ”文章“ ”喜欢“ 等词语,推测结果,但是计算机没有这一功能)
但是如果仅靠N-gram和RNN模型,模型首要注意的是距离推测内容最近的词语,这样计算机就很有可能给博主的 就不是三连了。 (0_=_0)..
(七)Attention Is All You Need训练模型核心概述
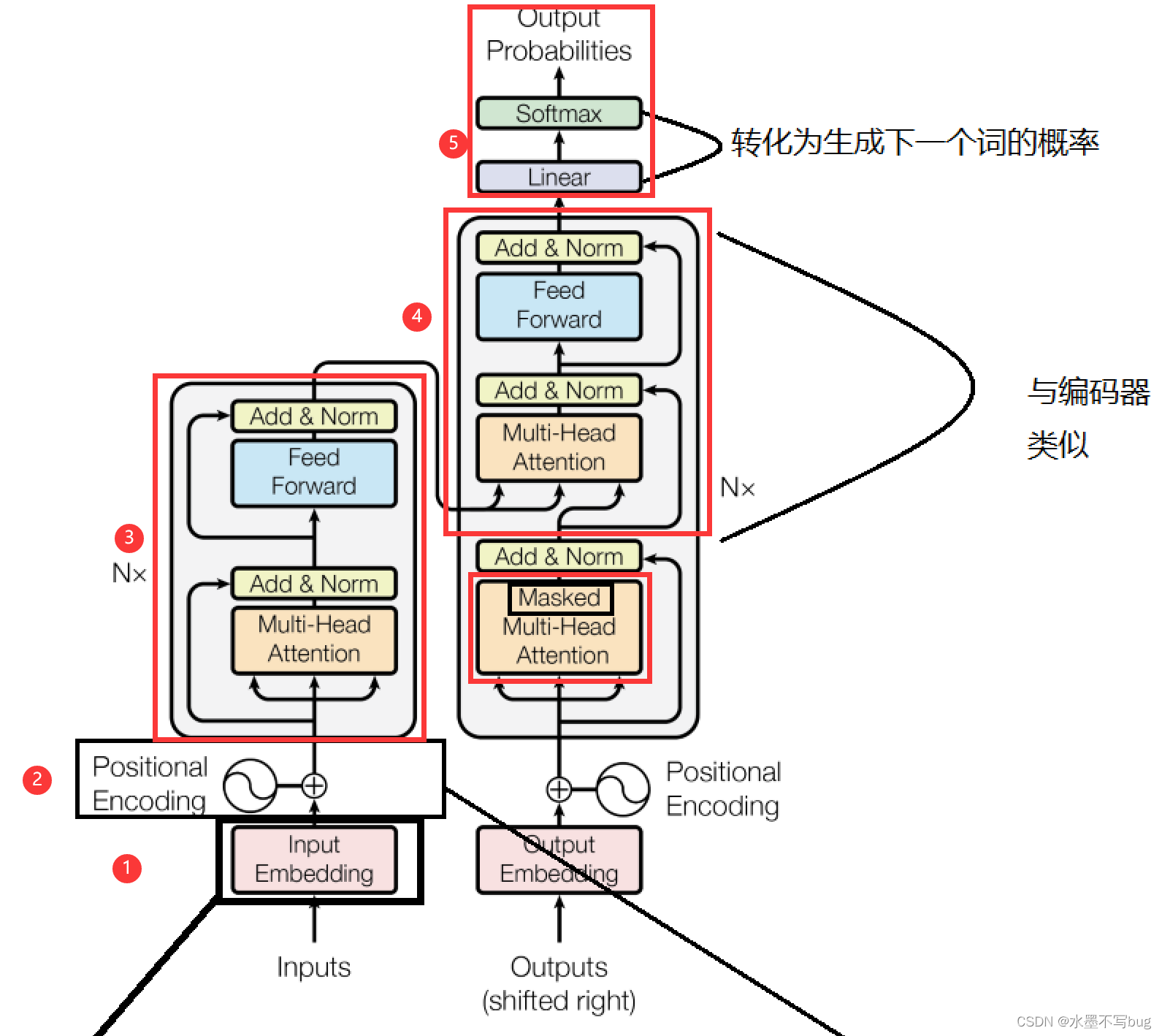
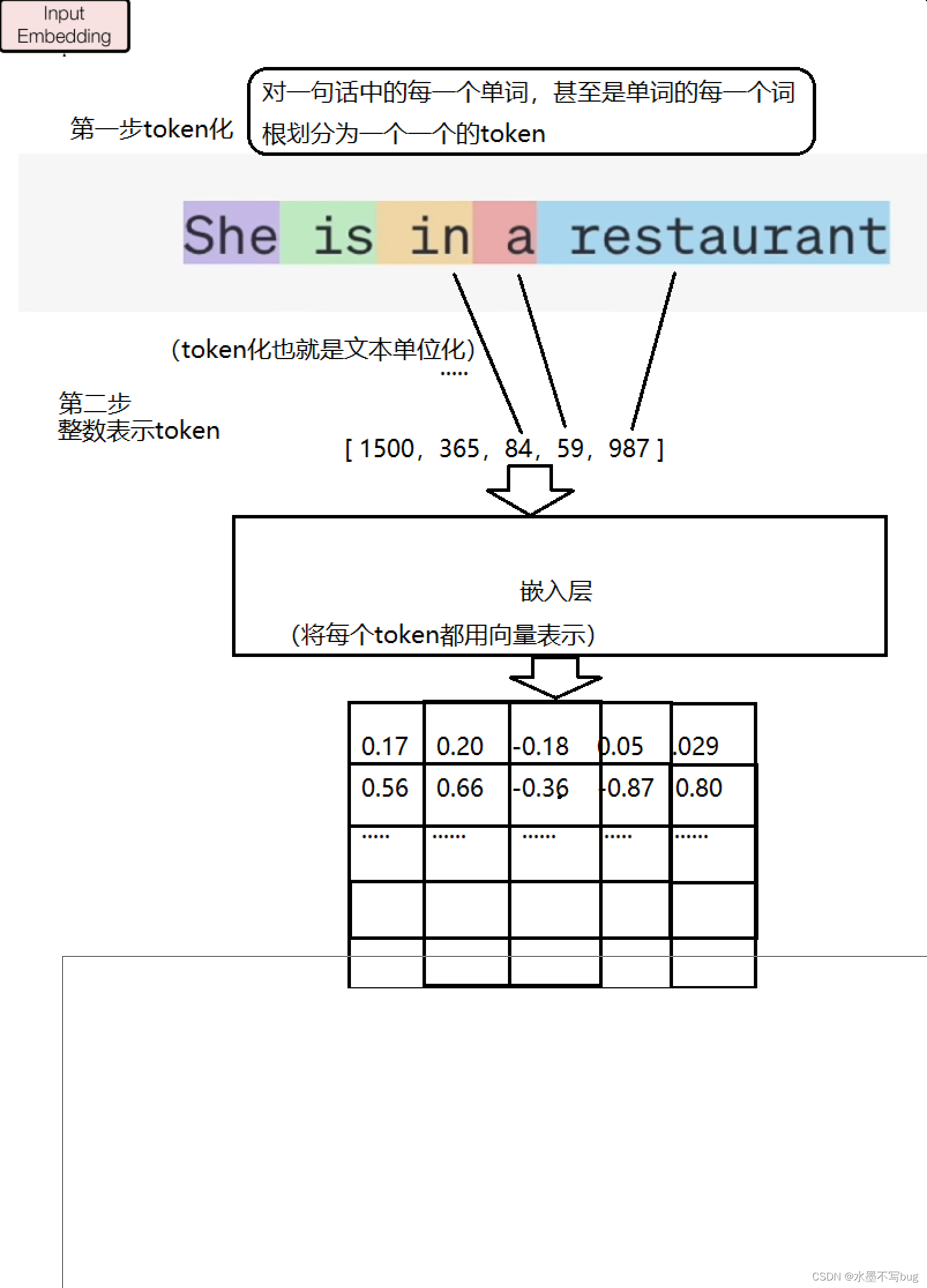
(1)Input Embedding 词嵌入
在transformer模型中,对于输入的每一句话,都会进行处理。
对一句话中的每一个单词,甚至是每一个长单词的词根划分为一个个token(token是一个文本单位,将会参与运算)。每一个token对应一个整数编号,把token转化为对应的编号,于是一句话就被转化为一串数字,具体来说是向量。为了尽可能多的保留语言的语意完整性,一句话转化成的向量通常非常长,有近512个参数。
词嵌入图解
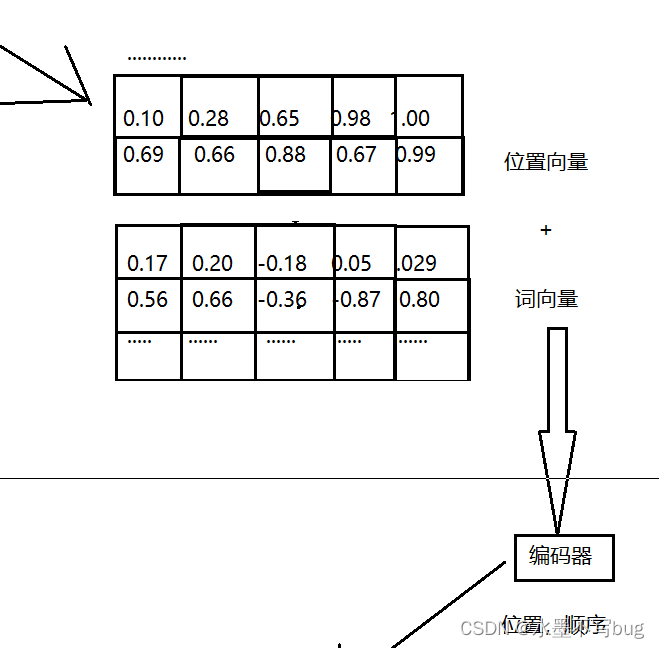
(2)Positional Encoding 位置编码
句子中的词汇的位置也携带了信息,这些信息被捕捉到并被转化为向量,这样的向量成为位置向量。
位置向量作为词向量的补充被输入到编码器中。
位置编码图解
(3) 多头自注意力机制的编码器
原文:

编码器图解
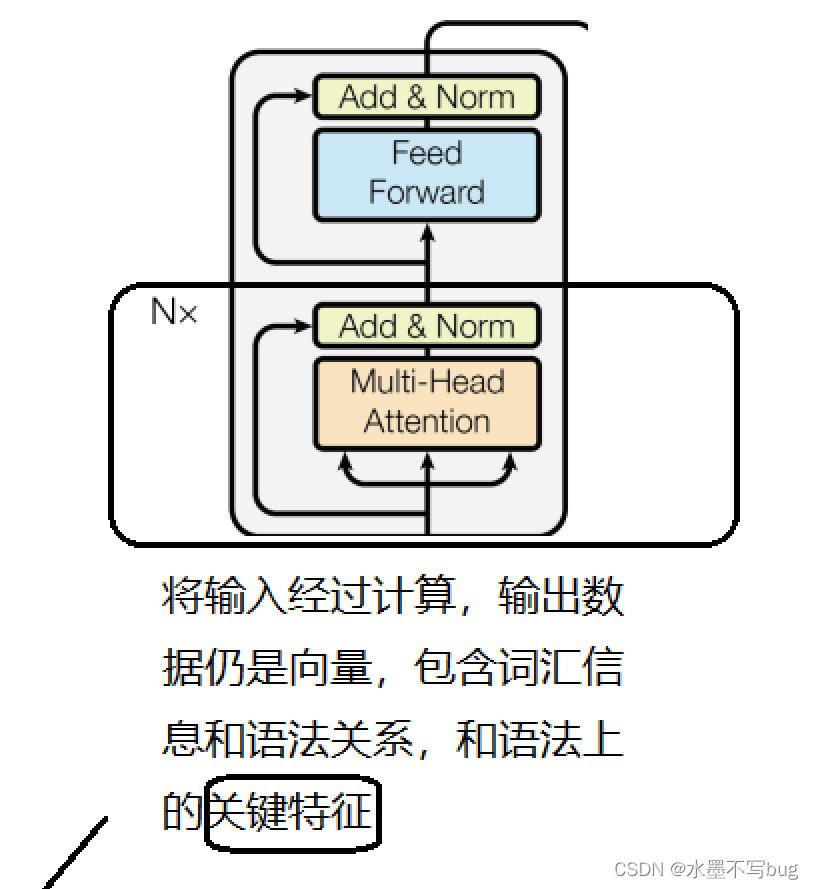
(4)Masked 多头自注意力
与第三步基本相同,但是下半部分是Masked的,遮盖的部分是输出的整个句子。原因在于在输出时,不能让 GPT知道将要输出的内容,否则达不到训练的目的了。
(5)Softmax 概率转化
将计算得到的信息传给Softmax函数,得到下一个词汇输出的概率,按照输出概率最大的词汇输出。
(八)总结
简单来说,让句子中的词语分别和句子中的所有词做向量点乘,对得出的结果再次进行训练,最终训练得到的结果会让电脑根据一个词语与句子中其他词语的点乘结果来推测这个词语后面出现其他词语的可能性,根据可能性来输出下一个词语。
词汇相关性分析图解

局限性
在合适的特征提取训练下,计算机学会了如何把话说得漂亮;ChatCPT本身就是一个语言模型,它被发明出来的目的并不是解决实际问题,而是怎样把话说得漂亮,之所以我们认为ChatGPT说得很有道理,是它阅读了大量语料库,经过大量训练的结果。
ChatGPT根据上文的内容去推测下一个词是什么,然后把这个词加进去,继续推测。
(九)ChatGPT能取代人类吗?
ChatGPT只是一个语言模型,它能够为我们解决问题提供一定的参考,但是并不能真正的解决问题。它确实可以取代一些人,令人们失业,但是如果这些人能够利用好GPT的优势,让它成为自己的力量,而不是排斥它,贬斥它,那么,GPT的出现并不应引起我们的焦虑,而是应引起我们的思考。
《attention is all you need》原文https://arxiv.org/abs/1706.03762
完~
未经作者同意禁止转载